

An exciting element of the current AI era is how powerful foundation models are being shared in the open and helping to accelerate innovation for everyone. This progress inspires us to ask, 'What's next for openness?' The Marin project sees an opportunity to expand the definition of 'open' to encompass the entire scientific process behind a model.
Stanford CRFM’s (Center for Research on Foundation Models) Marin project is designed as an 'open lab,' where the goal is not only to share the model but to make the complete journey accessible — including the code, data set, data methodologies, experiments, hyperparameters and training logs. This level of transparency complements the existing ecosystem by providing a unique, fully reproducible resource that empowers researchers to scrutinize, build upon, and trust the models being developed. Stanford’s Marin project seeks to foster a more transparent and accessible future for foundation model research.
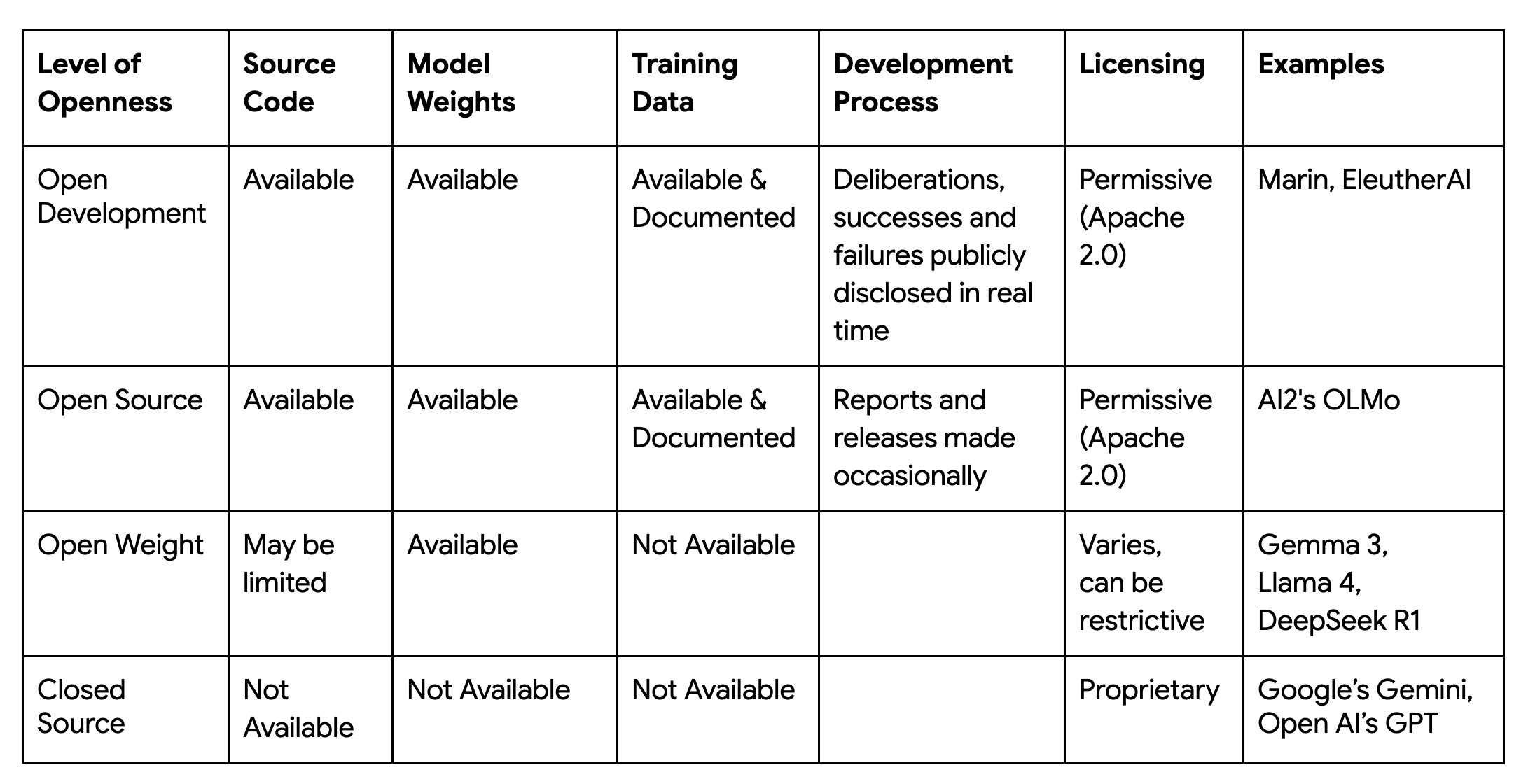
The first releases from this open lab are the Marin-8B-Base and Marin-8B-Instruct models. In keeping with the project's principles, the models, data, code, and tokenizer are all released under the permissive Apache 2.0 license. This commitment to complete reproducibility is a formidable engineering problem, requiring control over every source of variance in a massively distributed system. The project's success hinges on a technology stack that can deliver this guarantee of reproducibility at scale, and maximize efficiency to train a foundation model with leading price / performance.
For the Marin project to succeed in creating truly open, scalable, and reproducible foundation models, the CRFM team had to solve several engineering challenges. The team chose JAX as the foundation because its design principles provided direct solutions to these problems, and built a new framework, Levanter (see below), to harness JAX's power. Here are a few examples of challenges and their solutions
Problem: The core training loop is executed billions of times, so the overhead from an interpreted language like Python creates a massive performance bottleneck. If operations are dispatched step by step, the loop can also incur excessive memory traffic and overhead—especially on hardware like TPUs, where throughput depends on executing fused operations efficiently.
Our solution:
@jax.jit decorator. JAX's XLA compiler transforms this entire process into a single, highly-optimized machine code kernel, fusing operations to maximize hardware utilization at scale.jax.value_and_grad to compute both the loss and its gradients in a single pass. JAX also makes it easy to use advanced techniques like gradient checkpointing, saving memory and enabling us to use larger batch sizes with almost no overhead.Pallas-based Splash Attention kernel, a highly optimized implementation of Dot Product Attention, one of the most critical operations at the heart of nearly all large language models.Problem: Training state-of-the-art models requires scaling out to thousands of accelerator chips. Manually managing how the model and data are partitioned and how the devices communicate is immensely complex, and the code quickly becomes difficult to read, debug, and adapt.
Our solution:
@jax.jit decorator also seamlessly supports Single-Program, Multiple-Data (SPMD) parallelization that automates the underlying data sharding and communication. The XLA compiler automatically schedules communication between accelerators to minimize time spent waiting on the network and maximizing time spent on computation.jit’s power even easier and safer to use, Levanter developed Haliax, a library for named tensors. By referring to tensor axes with human-readable names (like "embed" or "batch") instead of positional indices, the code becomes self-documenting and robust.Problem: Large-scale training requires flexible access to massive compute clusters. We rely heavily on preemptible TPU instances to manage costs, which means we need a way to easily combine many smaller, disparate TPU slices into one logical cluster and be resilient to frequent interruptions.
Our solution:
Problem: A core goal of the Marin project is to enable verifiable science. This requires achieving reproducible results, even when training is paused, restarted, or moved between different machine configurations—a significant technical hurdle.
Our solution:
Problem: While JAX provides a powerful engine, no existing high-level framework met our stringent, combined requirements for legibility, massive scalability, and bitwise determinism. We needed a complete, opinionated system to orchestrate the entire training process.
Our solution:
jit) with low-level control (Pallas).The principles, tools and libraries discussed above were implemented and put to work during the Marin-8B training run. The model architecture is a Llama-style transformer.
Rather than a static, monolithic run, the training of Marin-8B was an adaptive journey, internally dubbed the "Tootsie" process. This honest portrayal of a real-world research workflow is detailed in the public. The process spanned over 12 trillion tokens and involved multiple phases that adapted to new data, techniques, and even different hardware configurations — migrating between large-scale, multi-slice TPU configurations (2x v5e-256 to 1x v4-2048 pods) mid-stream. The team continuously refined the data mixture, incorporating higher-quality sources, and adjusted hyperparameters like learning rate and batch size to optimize performance. This "messy" reality is a powerful educational tool, and the ability of the JAX and Levanter stack to handle these significant shifts while maintaining bit-for-bit reproducibility is a powerful demonstration of its robustness.
The Marin project is an open invitation to participate in the future of foundation model development and contribute to the JAX ecosystem. The journey of Marin represents the answer to our question, "What's next for openness?" This effort to create an 'open lab' is made possible by the technical capabilities of the JAX ecosystem. Its performance, portability, and foundational design for reproducibility are the key ingredients that allow us to make the 'complete journey' of research accessible.
By sharing everything from data methodologies to training logs, we aim to provide a fully reproducible resource—one that empowers researchers to deeply scrutinize, build upon, and trust the work. We believe this is a collaborative step toward a more transparent future for AI. We invite you to join us in this 'open lab'—to use Marin, to contribute to the research, and to help build the next wave of innovative and trustworthy foundation models.
The central resource for the project is the official website, marin.community. From there, you can find the released models on Hugging Face, explore the "open lab" on GitHub, read Marin documentation, and dive into the Levanter training framework. You can also test drive Marin in a colab with a simple inference example.
And active discussions are taking place in the Discord channel where you can interact directly with other developers. For those new to the ecosystem, the official JAX documentation provides excellent resources, including a Quickstart guide.
Unlocking Peak Performance on Qualcomm NPU with LiteRT

Architecting efficient context-aware multi-agent framework for production

Announcing the Data Commons Gemini CLI extension

Google Cloud donates A2A to Linux Foundation

Advancing agentic AI development with Firebase Studio