

현재 AI 시대의 흥미로운 요소 하나는, 강력한 파운데이션 모델들이 개방형으로 공유되어 모두의 혁신을 가속하고 있다는 점입니다. 이러한 발전은 우리로 하여금 ‘개방성(openness)의 다음 단계는 무엇인가?’라는 질문을 던지게 만듭니다. Marin 프로젝트는 모델을 둘러싼 전체 과학적 프로세스를 포함하도록 '개방'의 정의를 확장할 수 있는 가능성을 모색합니다.
Stanford CRFM(Center for Research on Foundation Models, 파운데이션 모델 연구센터)의 Marin 프로젝트는 단순히 모델을 공유하는 데 그치지 않고, 코드, 데이터 세트, 데이터 구축 방법론, 실험, 하이퍼파라미터, 학습 로그에 이르기까지 모델 개발 전 과정에 누구나 접근할 수 있도록 설계된 '오픈 랩(open lab)'입니다. 이러한 수준의 투명성은 연구자들이 개발 중인 모델을 면밀히 분석하고, 신뢰하며, 그를 토대로 새로운 연구를 이어갈 수 있도록 하는 고유하고 완전히 재현 가능한 자원을 제공함으로써 기존 생태계를 보완합니다. Stanford의 Marin 프로젝트는 파운데이션 모델 연구의 투명성과 접근성을 한층 더 끌어올리는 미래를 지향합니다.
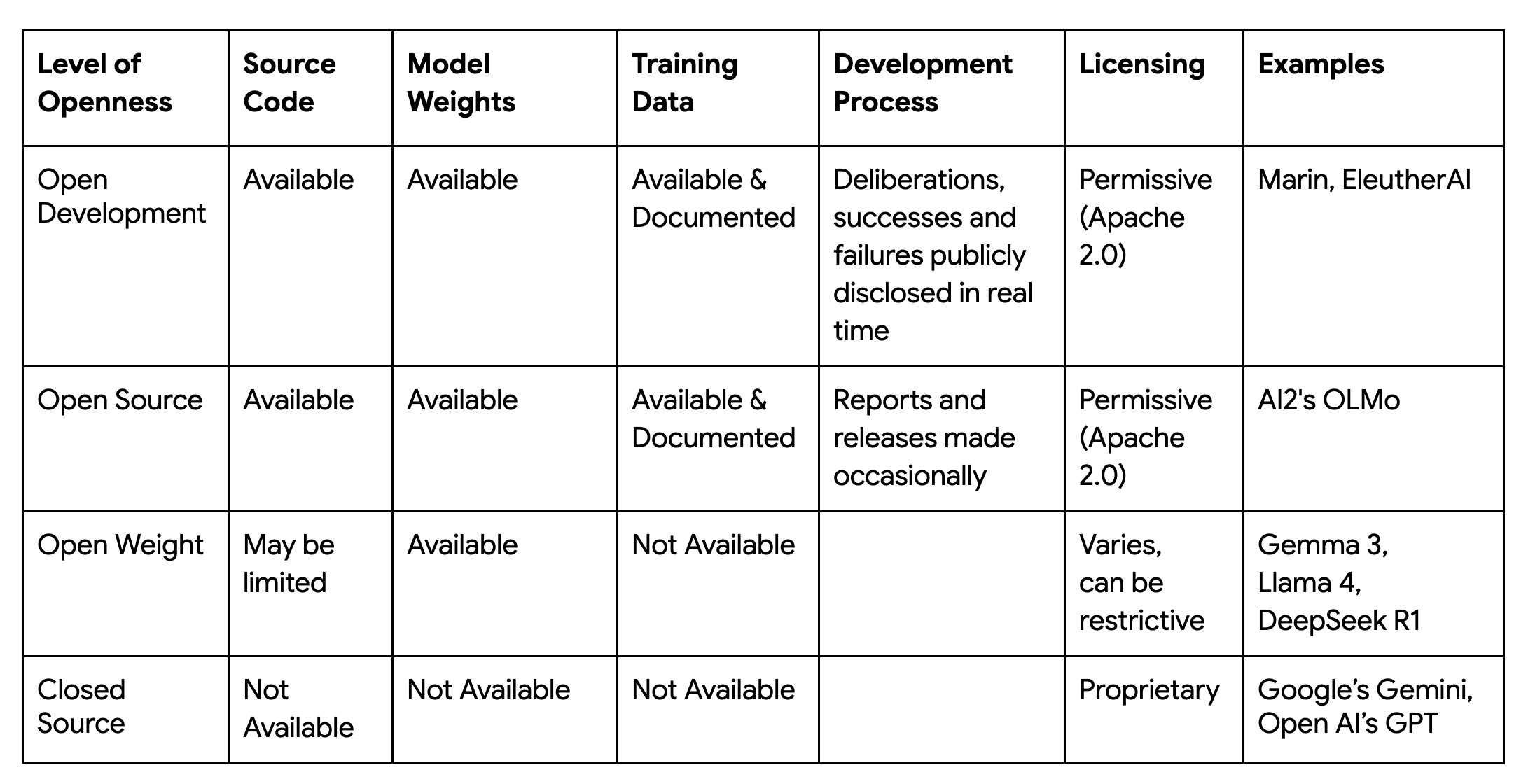
이 오픈 랩에서 처음으로 공개된 결과물은 Marin-8B-Base와 Marin-8B-Instruct 모델입니다. 프로젝트의 원칙에 따라, 모델은 물론 데이터, 코드, 토크나이저(tokenizer)까지 모두 자유로운 Apache 2.0 라이선스 하에 공개되었습니다. 완전한 재현 가능성에 대한 이러한 의지는 대규모 분산 시스템에서 발생할 수 있는 모든 변동 요인을 통제해야 하는 고난도의 엔지니어링 과제를 수반합니다. 이 프로젝트의 성공은 대규모 환경에서도 재현 가능성을 보장하는 동시에 비용 대비 최고 수준의 효율로 파운데이션 모델을 학습시킬 수 있는 기술 스택에 달려 있습니다.
Marin 프로젝트가 진정으로 개방적이고 확장 가능하며 재현 가능한 파운데이션 모델을 만드는 데 성공하기 위해, CRFM 팀은 몇 가지 엔지니어링 과제를 해결해야 했습니다. 이들은 이러한 문제들을 설계 차원에서 직접 해결할 수 있다는 이유로 JAX를 기반으로 선택했으며, JAX의 성능을 효과적으로 활용하기 위해 새로운 프레임워크인 Levanter(아래 참조)를 구축했습니다. 아래는 주요 과제와 그 해결책의 몇 가지 사례입니다.
문제: 핵심 학습 루프는 수십억 번 실행되므로, Python과 같은 인터프리트 언어에서 발생하는 오버헤드는 심각한 성능 병목 현상을 초래합니다. 연산이 단계별로 개별 실행될 경우, 루프는 과도한 메모리 트래픽과 오버헤드를 유발할 수 있으며, 특히 처리량이 연산 융합의 효율적 실행에 크게 좌우되는 TPU와 같은 하드웨어에서는 문제가 더욱 심각해집니다.
당사의 해결책:
@jax.jit 데코레이터를 사용합니다. JAX의 XLA 컴파일러는 이 전체 프로세스를 고도로 최적화된 단일 기계어 코드 커널로 변환하며, 연산을 융합하여 대규모 환경에서 하드웨어 활용도를 극대화합니다.jax.value_and_grad를 사용하여 손실과 해당 기울기(gradient)를 한 번에 계산합니다. 또한 JAX는 gradient checkpointing 같은 고급 기법을 쉽게 사용할 수 있도록 지원하며, 이를 통해 메모리를 절약하고 오버헤드를 거의 발생시키지 않으면서 더 큰 배치 크기를 사용할 수 있습니다.Pallas 기반 Splash Attention 커널을 사용합니다.문제: 최첨단 모델을 학습시키려면 수천 개의 가속기 칩으로 확장해야 합니다. 모델과 데이터를 어떻게 분할할지, 기기 간 통신을 어떻게 처리할지를 수동으로 관리하는 것은 극도로 복잡하며, 코드를 읽고 디버깅하고 수정하는 작업도 매우 까다로워집니다.
당사의 해결책:
@jax.jit 데코레이터는 기본적인 데이터 샤딩(sharding) 및 통신을 자동화하는 단일 프로그램, 다중 데이터(Single-Program, Multiple-Data, SPMD) 동시 로드를 원활하게 지원합니다. XLA 컴파일러는 가속기 간의 통신을 자동으로 스케줄링하여, 네트워크 대기 시간을 최소화하고 계산에 더 많은 시간을 할당할 수 있게 합니다.jit의 강력한 기능을 보다 쉽고 안전하게 활용할 수 있도록, Levanter는 명명된 텐서(tensor)를 지원하는 라이브러리인 Haliax를 개발했습니다. 위치 기반 인덱스 대신 사람이 읽을 수 있는 이름(예: "embed" 또는 "batch")으로 텐서 축을 참조함으로써, 코드 자체가 설명이 필요 없는 문서 역할을 하며, 더욱 안정적이고 유지보수가 쉬워집니다.문제: 대규모 모델을 학습시키려면 대규모 컴퓨트 클러스터를 유연하게 활용할 수 있어야 합니다. 우리는 비용 절감을 위해 선점형(preemptible) TPU 인스턴스에 크게 의존하고 있으며, 이로 인해 더 작고 서로 다른 수많은 TPU 슬라이스를 하나의 논리 클러스터로 쉽게 통합하고, 잦은 중단에도 안정적으로 대응할 방법이 필요합니다.
당사의 해결책:
문제: Marin 프로젝트의 핵심 목표 중 하나는 검증 가능한 과학을 실현하는 것입니다. 이를 위해서는 학습 과정이 일시 중지되거나 재시작되거나, 서로 다른 시스템 환경으로 이동하더라도 동일한 결과를 재현해야 합니다. 이는 기술적으로 상당히 어려운 도전 과제입니다.
당사의 해결책:
문제: JAX는 강력한 엔진을 제공하지만 기존의 어떤 고수준 프레임워크도 가독성, 대규모 확장성, 그리고 비트 단위의 결정론적 동작이라는 세 가지 엄격한 요건을 동시에 충족하지 못했습니다. 우리는 전체 학습 프로세스를 조율할 수 있는, 명확한 설계 철학을 갖춘 완전한 시스템이 필요했습니다.
당사의 해결책:
jit)와 저수준 제어(Pallas)의 매끄러운 통합 기능을 바탕으로 Levanter를 구축했습니다.앞서 설명한 원칙, 도구, 라이브러리들은 Marin-8B 학습 실행 과정에서 실제로 구현하여 사용되었습니다. 해당 모델 아키텍처는 Llama 스타일의 트랜스포머입니다.
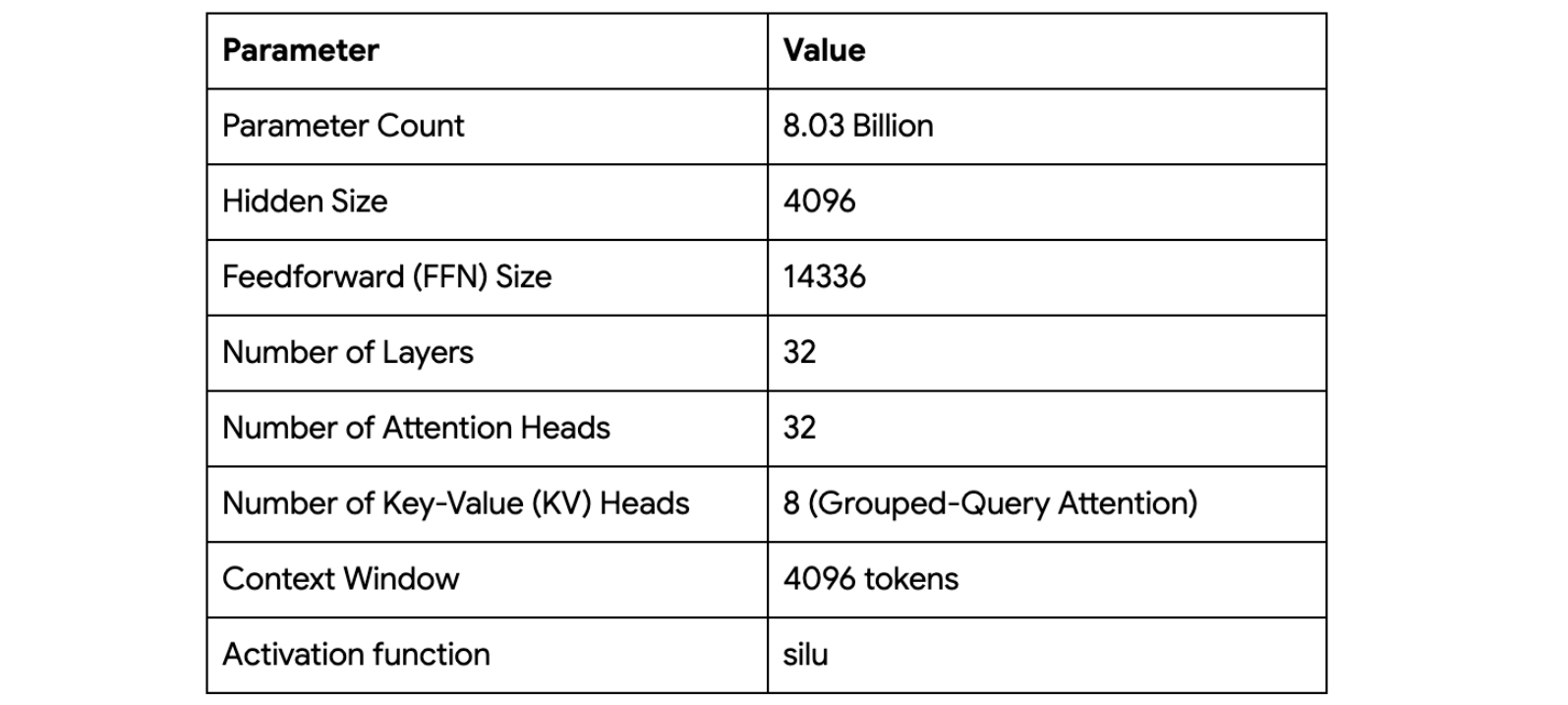
Marin-8B의 학습은 고정적이고 일괄적인 실행이 아니라, 내부적으로 "Tootsie" 프로세스라고 불리는 적응형 여정이었습니다. 실제 연구 워크플로의 현실을 정직하게 보여주는 이 과정은 세부적인 부분까지 공개되어 있습니다. 이 프로세스는 12조 개가 넘는 토큰을 처리했으며, 새로운 데이터와 기법, 그리고 다양한 하드웨어 구성에 적응하기 위해 여러 단계로 구성되었습니다. 예를 들면, 학습 도중에 대규모 다중 슬라이스 TPU 구성(2x v5e-256에서 1x v4-2048 포드로) 마이그레이션이 이루어졌습니다. 연구팀은 데이터 조합을 지속적으로 개선하여 보다 고품질의 소스를 통합하고 학습률과 배치 크기 같은 하이퍼파라미터를 조정하여 성능을 최적화했습니다. 이렇게 "복잡하고 예측 불가능한(messy)" 현실은 오히려 강력한 교육 도구가 되며, JAX 및 Levanter 스택이 이러한 유동적 변화 속에서도 비트 단위의 재현성을 유지할 수 있었다는 점은 그 기술적 견고함을 잘 보여줍니다.
Marin 프로젝트는 파운데이션 모델 개발의 미래에 함께하고 JAX 생태계에 기여할 수 있도록 열려 있는 초대장입니다. Marin의 여정은 우리가 던졌던 질문, "개방의 다음 단계는 무엇일까요?"에 대한 당사의 답이라 할 수 있습니다. '오픈 랩'을 실현하려는 이러한 노력은 JAX 생태계의 기술적 기반 덕분에 가능해졌습니다. 성능, 이식성, 그리고 재현성을 염두에 둔 설계는 연구 과정 '전체 여정'을 누구나 접근 가능한 형태로 공개하는 데 필요한 핵심 요소입니다.
데이터 방법론에서 학습 로그에 이르기까지 모든 것을 공유함으로써, 우리는 연구자가 작업을 면밀히 검토하고, 그를 통해 연구를 이어가며, 신뢰할 수 있는 완전히 재현 가능한 자원을 제공하고자 합니다. 우리는 이것이야말로 AI를 더욱 투명한 방향으로 나아가게 하는 공동의 한 걸음이라고 믿습니다. Marin을 활용하고, 연구에 기여하고, 혁신적이고 신뢰할 수 있는 차세대 파운데이션 모델을 함께 만들어 나가는 데 도움이 되는 이 '오픈 랩'에 여러분을 초대합니다.
이 프로젝트의 핵심 자료는 공식 웹사이트 marin.community에 있습니다. 이곳에서 Hugging Face에 공개된 모델을 찾고, GitHub의 '오픈 랩'을 탐색하고, Marin 문서를 읽고, Levanter 학습 프레임워크를 살펴볼 수 있습니다. 또한 간단한 추론 예제를 통해 콜랩(colab)에서 Marin을 직접 실행해 볼 수도 있습니다.
Discord 채널에서는 다른 개발자들과 직접 소통할 수 있는 활발한 토론이 진행 중입니다. 이 생태계를 처음 접하는 분들을 위해, 공식 JAX 문서에는 빠른 시작 가이드(Quickstart guide)를 포함하여 탁월한 학습 자료들이 잘 정리되어 있습니다.

Announcing the Data Commons Gemini CLI extension

Google Cloud, Linux Foundation에 A2A 제공
Coral NPU 소개: Edge AI를 위한 풀 스택 플랫폼

Building with Gemini 3 in Jules
Beyond Request-Response: Architecting Real-time Bidirectional Streaming Multi-agent System

Firebase Studio로 에이전트 AI 개발 진전