

現在の AI 時代におけるエキサイティングな要素として、強力な基盤モデルがオープンに共有され、あらゆる人のイノベーションを加速している点が挙げられます。この進歩から、「オープン性の次のステップは何なのか?」という問いが見えてきます。Marin プロジェクトでは、「オープン」の定義をモデルの背後にある科学的プロセス全体にまで拡張する機会を見出しています。
スタンフォード大学 Center for Research on Foundation Models(CRFM)の Marin プロジェクトは、「オープンラボ」として設計されており、モデルを共有するだけでなく、コード、データセット、データ手法、テスト、ハイパーパラメータ、トレーニング ログなど、開発のすべての過程を公開することを目標としています。このレベルの透明性は、研究者が開発中のモデルを精査、構築し、信頼性を高められるようにするユニークで完全に再現可能なリソースを提供することで、既存のエコシステムを補完します。スタンフォード大学の Marin プロジェクトは、今後の基盤モデル研究をより透明でアクセスしやすいものにすることを目指しています。
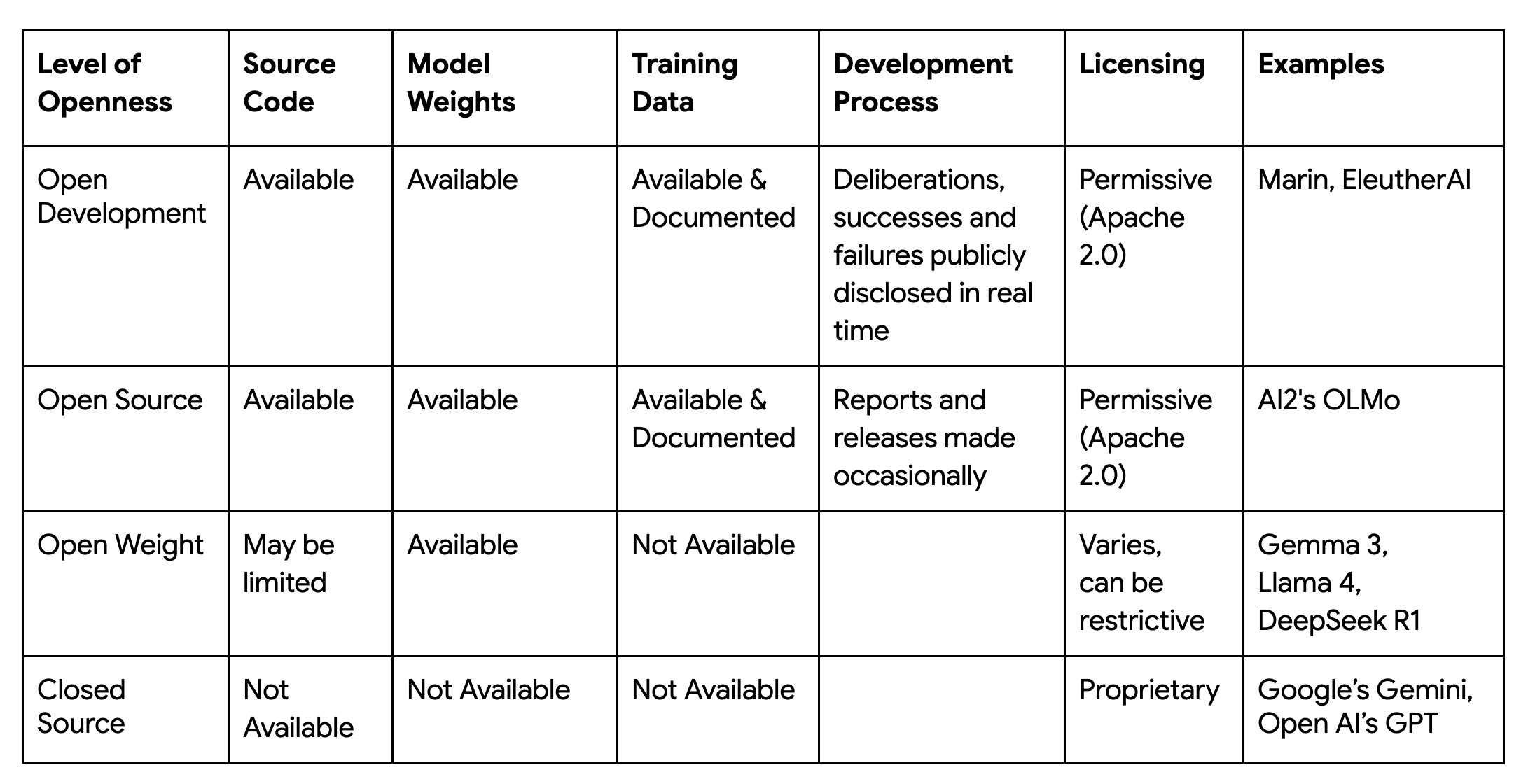
このオープンラボから最初に公開されたモデルは、Marin-8B-Base と Marin-8B-Instruct です。プロジェクトの原則に従って、モデル、データ、コード、トークナイザーはすべて許容性の高い Apache 2.0 ライセンスの下で公開されています。完全な再現性を目指すこの取り組みには、極めて困難なエンジニアリング上の課題があります。大規模に分散されたシステムにおいて、あらゆる変動要因を制御する必要があります。このプロジェクトの成功は、この再現性を大規模に実現し、優れたコスト パフォーマンスで基盤モデルのトレーニング効率を最大化できるテクノロジー スタックにかかっています。
Marin プロジェクトにおいて、真にオープンでスケーラブルかつ再現可能な基盤モデルの作成に成功するために、CRFM チームはいくつかのエンジニアリング上の課題を解決しなければなりませんでした。チームが JAX を基盤として選んだのは、その設計原理がこれらの課題に対する直接的な解決策を提供していたためです。そして、JAX の力を活用するための新しいフレームワークであるLevanter(下記を参照)を構築しました。以下に課題とその解決策の例をいくつかご紹介します。
課題: コアとなるトレーニング ループは何十億回も実行されるため、Python のようなインタプリタ言語に起因するオーバーヘッドが、パフォーマンスに対する大きなボトルネックとなります。オペレーションが段階的にディスパッチされる場合、ループによってメモリ トラフィックとオーバーヘッドが過剰に生じる可能性もあります。特に TPU のようなハードウェアでは、スループットが融合されたオペレーションの効率性に依存しているため、この問題が顕著になります。
解決策:
@jax.jit デコレータを使用します。JAX の XLA コンパイラは、このプロセス全体を高度に最適化された単一のマシンコード カーネルに変換し、オペレーションを融合させて大規模にハードウェアを最大限活用できるようにします。jax.value_and_grad を使用して 1 つのパスで損失とその勾配の両方を計算します。また、JAX を使用すると、勾配チェックポインティングなどの高度な手法を簡単に使用でき、メモリを節約して、オーバーヘッドをほとんど発生させることなくより大きなバッチサイズを使用できます。Pallas ベースの Splash Attention カーネルを使用しています。これは、ほぼすべての大規模言語モデルの中核をなす最も重要なオペレーションの一つである Dot Product Attention の高度に最適化された実装です。課題: 最先端のモデルをトレーニングするには、何千ものアクセラレータ チップにスケールアウトする必要があります。モデルとデータの分割方法やデバイス間の通信方法を手動で管理するのは非常に複雑で、コードの読み取り、デバッグ、適応がすぐに困難になります。
解決策:
@jax.jit デコレータは、基盤となるデータのシャーディングと通信を自動化する「Single-Program, Multiple-Data 」(SPMD)並列化もシームレスにサポートしています。XLA コンパイラはアクセラレータ間の通信を自動的にスケジュールして、ネットワーク上の待機時間を最小限に抑え、計算に費やす時間を最大化します。jit の機能をさらに安全で使いやすくするために、Levanter は名前付きテンソルのライブラリである Haliax を開発しました。テンソル軸を、位置インデックスではなく人間が読み取り可能な名前(「embed」や「batch」など)で参照することにより、コードの自己文書化が進み堅牢になります。課題: 大規模なトレーニングには、大規模なコンピューティング クラスタへの柔軟なアクセスが不可欠です。コスト管理のためにプリエンプティブル TPU インスタンスに大きく依存しているので、多くの小規模で分散した TPU スライスを 1 つの論理クラスタに簡単に結合し、頻繁な中断にも耐えられる仕組みが必要です。
解決策:
課題: Marin プロジェクトの中核的な目標は、検証可能な科学を実現することです。そのためには、トレーニングが中断、再開、または異なるマシン構成に移行した場合でも再現可能な結果を達成する必要があります。これは大きな技術的ハードルでした。
解決策:
課題: JAX は強力なエンジンを提供していますが、既存の高レベル フレームワークはいずれも、読みやすさ、大規模なスケーラビリティ、ビット単位の決定論という私たちの厳格な要件をすべて満たすものではありませんでした。トレーニング プロセス全体をオーケストレートするために、包括的で明確な方針を持つシステムが必要でした。
解決策:
jit)と低レベルの制御(Pallas)とのシームレスな統合を基盤として開発を進めました。前述の原則、ツール、ライブラリは、Marin-8B のトレーニング実行中に実装され、実際に機能しました。モデル アーキテクチャは Llama スタイルの Transformer です。
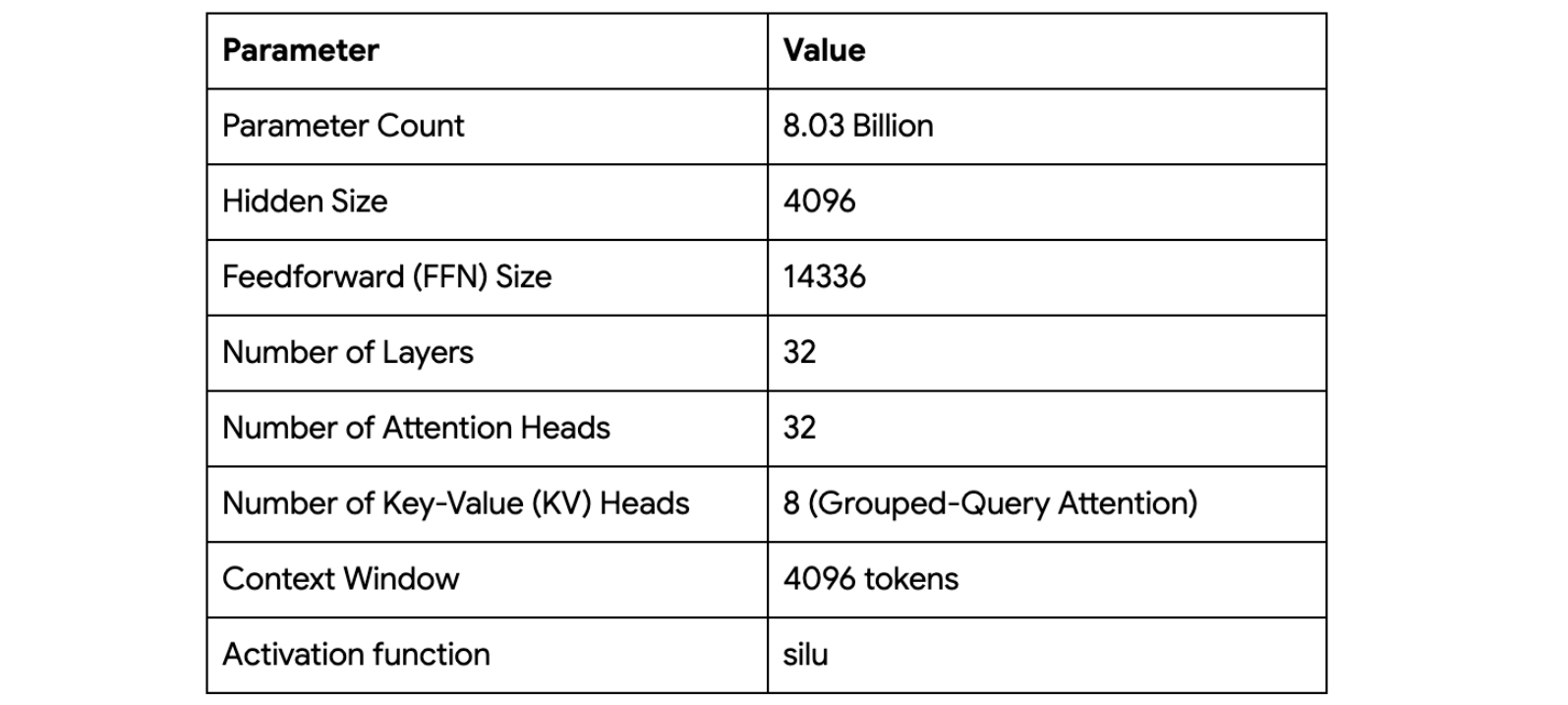
Marin-8B のトレーニングは静的でモノリシックな実行ではなく、適応的なプロセスであり、社内では「Tootsie」プロセスと呼ばれていました。これは、実際の研究ワークフローを包み隠さず描写したもので、詳細が一般に公開されています。このプロセスは 12 兆を超えるトークンに及び、新しいデータ、手法、さらには大規模なマルチスライス TPU 構成(2x v5e-256 から 1x v4-2048 ポッド)への移行を途中で行うなど、異なるハードウェア構成に適応する複数のフェーズを経て実施されました。チームは継続的に混合データを改良し、より高品質なソースを組み込んで学習率やバッチサイズなどのハイパーパラメータの調整を行い、パフォーマンスを最適化しました。この「ごちゃごちゃした」現実のプロセスは強力な教材であり、JAX と Levanter スタックがこれらの重大な変化に対応しながらもビット単位の再現性を維持できたという能力は、その技術の堅牢性を強力に実証しています。
Marin プロジェクトは、基盤モデル開発の将来に参加し、JAX エコシステムに貢献することを広く呼びかける招待状です。Marin の歩みは「オープン性の次のステップとは何なのか?」という問いへの答えを表しています。この「オープンラボ」創出の取り組みは、JAX エコシステムの技術的能力によって可能になりました。そのパフォーマンス、ポータビリティ、再現性を重視した基礎設計は、研究の「完全な旅」を実現するための重要な要素となっています。
データ手法からトレーニング ログまで、あらゆる情報を共有することで、私たちは完全に再現可能なリソースを提供することを目指しています。このリソースにより、研究者は作業を詳細に検証し、そのうえでの構築し、信頼性を高めることができます。これは、より透明性の高い AI の未来に向けたコラボレーションの一歩であると考えています。ぜひこの「オープンラボ」に参加し、Marin を活用してください。研究に貢献することで、革新的かつ信頼性の高い次世代の基盤モデル構築にご協力ください。
プロジェクトの主なリソースは公式ウェブサイト marin.community です。そこから、Hugging Face でリリースされたモデルにアクセスする、GitHub の「オープンラボ」を探索する、Marin のドキュメントを閲覧する、Levanter のトレーニング フレームワークの詳細を学ぶ、といったことが可能です。シンプルな推論例を使用して、Colab で Marin を試すこともできます。
また、Discord チャンネルでは活発な議論が行われており、他のデベロッパーと直接交流できます。エコシステムを初めて利用する方のために、JAX の公式ドキュメントにはクイックスタート ガイドなどの優れたリソースも掲載されていますので、そちらもご活用ください。

Google Cloud が A2A を Linux Foundation に寄贈

Firebase Studio でエージェント AI 開発を推進
Beyond Request-Response: Architecting Real-time Bidirectional Streaming Multi-agent System

Building with Gemini 3 in Jules
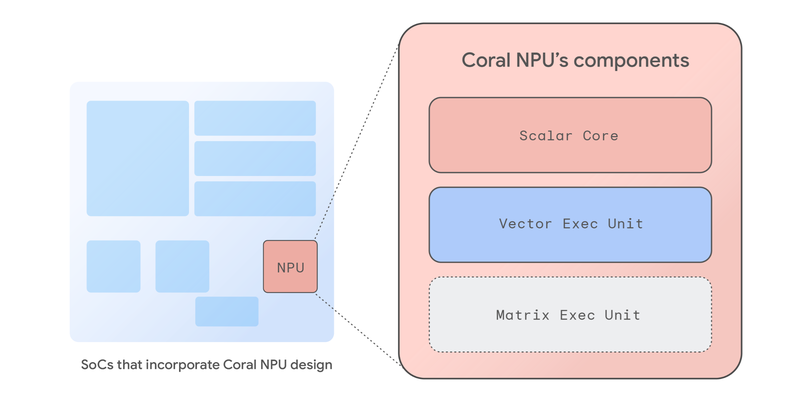
Coral NPU のご紹介: エッジ AI 向けフルスタック プラットフォーム

Announcing the Data Commons Gemini CLI extension