
Gemma is a family of open models built from the same research and technology used to create the Gemini models. The family currently includes Gemma, CodeGemma, PaliGemma, and RecurrentGemma. Collectively, the models are capable of performing a wide range of tasks, including text generation, code completion and generation, many vision-language tasks, and can run on various devices from edge to desktop to cloud. You can go even further and fine-tune Gemma models to suit your specific needs.
Gemma is built for the open community of developers and researchers powering AI innovation. You can explore more about Gemma and access quickstart guide on ai.google.dev/gemma
In this blog post, let's explore 3 fun project ideas and how to use Gemma models to create them:
The Korean alphabet, or Hangul, has undergone changes over time, resulting in several letters no longer used in modern Korean. These obsolete letters include:
2. ㆆ (Yeorin-hieut): Pronounced as a 'light h,' akin to a softer version of the English 'h.'
3. ㅿ (Bansiot): Represents the 'z' sound.
4. ㆁ (Yet-ieung): A velar nasal sound comparable to 'ng' in the word 'sing.'
For native Korean speakers, reading older literature presents a challenge due to the utilization of now-obsolete letters. Early Hangul lacked spaces between words, further complicating readability. In contrast, modern Hangul employs spaces, consistent with most alphabetic systems.
Gemma's capabilities enable the creation of a translator that assists in comprehending and bridging the divide between contemporary and archaic Korean. SentencePiece serves as the foundation for Gemma's tokenizer. In contrast to conventional tokenizers, which heavily rely on language-specific guidelines or predefined dictionaries, SentencePiece undergoes training directly on raw text data. Consequently, it becomes independent of any specific language and adaptable to various forms of text data.
Software
To simplify the task, we will adopt the following structure for fine-tuning the model. The model will generate contemporary Korean text based on the user's input in Early Hangul.

Instruction-tuned (IT) models are trained with a specific formatter. Note that the control tokens are tokenized in a single token in the following manner:

For model training, we will use “Hong Gildong jeon”, a Joseon Dynasty-era Korean novel.
To assess the model’s output quality, we will use text from outside the training datasets, specifically the classic Korean novel “Suk Yeong Nang Ja jeon” by an unknown author.
The model has no capability to translate Early Hangul.

After fine-tuning, responses follow the instruction, and it generates contemporary Korean text based on the Early Hangul text.

For your reference, please see the following text, which has been translated by a human:
“금두꺼비가 품에 드는 게 보였으니 얼마 안 있어 자식을 낳을 것입니다.
하였다. 과연 그 달부터 잉태하여 십삭이 차니”
Note: Korean text means, “I saw a golden toad in her arms, so it won’t be long before she gives birth to a child.” Indeed, she conceived from that month and was ten months old.
And here's another output.

And the translation by a human below:
“이 때는 사월 초파일이었다. 이날 밤에 오색구름이 집을 두르고 향내 진동하며 선녀 한 쌍이 촉을 들고 들어와 김생더러 말하기를,”
Note: Korean text means, At this time, it was the 8th of April. On this night, with five-colored clouds surrounding the house and the scent of incense vibrating, a pair of fairies came in holding candles and said to Kim Saeng,
Although the translation is not flawless, it provides a decent initial draft. The results are remarkable, considering that the datasets are limited to a single book. Enhancing the diversity of data sources will likely improve the translation quality.
Once you fine tune the model, you can simply publish it to Kaggle and Hugging Face.
Below is an example.
# Save the finetuned model
gemma.save_to_preset("./old-korean-translator")
# Upload the model variant on Kaggle
kaggle_uri = "kaggle://my_kaggle_username/gemma-ko/keras/old-korean-translator"
keras_nlp.upload_preset(kaggle_uri, "./old-korean-translator")To achieve similar tasks, you can replicate the same structure. Below are some examples:
Various everyday objects and concepts have different names depending on the region. For example, in American English (AmE), people use terms like "elevator," "truck," "cookie," and "french fries," while in British English (BrE), the equivalent words are "lift," "lorry," "biscuit," and "chips," respectively.
Apart from vocabulary differences, spelling variations also exist. For instance, in AmE, words ending in "-or" are often spelled with "-our" in BrE. Examples include "color" (AmE) and "colour" (BrE), or "humor" (AmE) and "humour" (BrE).
Another spelling variation is the "-ize" versus "-ise" distinction. In AmE, words like "organize" and "realize" are commonly spelled with a "z," whereas in BrE, the preferred spelling is "organise" and "realise," using an "s" instead.
With the help of AI tools like Gemma, it is possible to create a style transfer from one English to another, allowing seamless transitions between American and British English writing styles.
In the Kansai region of Japan, there is a distinct group of dialects known as Kansai-ben. Compared to the standard Japanese language, native speakers perceive Kansai-ben as being both more melodic and harsher in its pronunciation and intonation.
Utilizing the Gemma's capabilities, you can create a dialect translator by preparing a substantial quantity of Kansai-ben datasets.
With Gemma as your trusty companion, you can embark on a journey to create a captivating game. It all starts with a simple one-sentence pitch that serves as the foundation of your game's concept. Gemma will skillfully guide you in fleshing out the game's concept, crafting intricate main characters, and writing a captivating main story that will immerse players in your game's world.
Software
Starting with writing a core concept, one-sentence pitch of your game, like below:

Gemma can add more details based on your pitch.
Input : “Elaborate about this game with the given core concept below.\n{pitch}”
Example Output :

Input : “Design main characters”
Example Output :

Input : “Design villain characters”
Example Output :

Input : “Write the main story of this game with an introduction, development, turn, and conclusion.”
Example Output :

By modifying the prompt, you can get a similar companion for almost any type of creative content.
Pitch : “A new steam-powered toothbrush”
Input : “Generate a marketing phrase for the new product below.\n{pitch}”
Example Output :

Pitch : “Universe and shooting stars”
Input : “Generate a florist idea inspired by the concept below, along with suggestions for suitable flowers.\n{pitch}”
Example Output :

Pitch : “Cyberpunk Kraken”
Input : “Generate a cooking recipe with the concept below.\n{pitch}”
Example Output :

The traditional method of sending letters to Santa can be limited and impersonal. Children often have to wait weeks or even months for a response, and their letters may not be as detailed or interactive as they would like.
In this project, we will use Gemma, running on a Raspberry Pi, to compose magical letters from Santa using the power of a large language model.
Hardware
Software
Text generation
You can write your own C++ application with libgemma.
Use the prompt below to instruct the model

Before building, modify the MODEL_PATH defined in the code.
$ g++ santa.cc -I . -I build/_deps/highway-src -I build/_deps/sentencepiece-src build/libgemma.a build/_deps/highway-build/libhwy.a build/_deps/sentencepiece-build/src/libsentencepiece.so -lstdc++ -lRun
$ LD_LIBRARY_PATH=./build/_deps/sentencepiece-build/src ./a.outIt will read the text from letter.txt and generate a letter from Santa Claus.
NOTE: the text generation on Raspberry Pi may take some time.

And here’s the final result later:
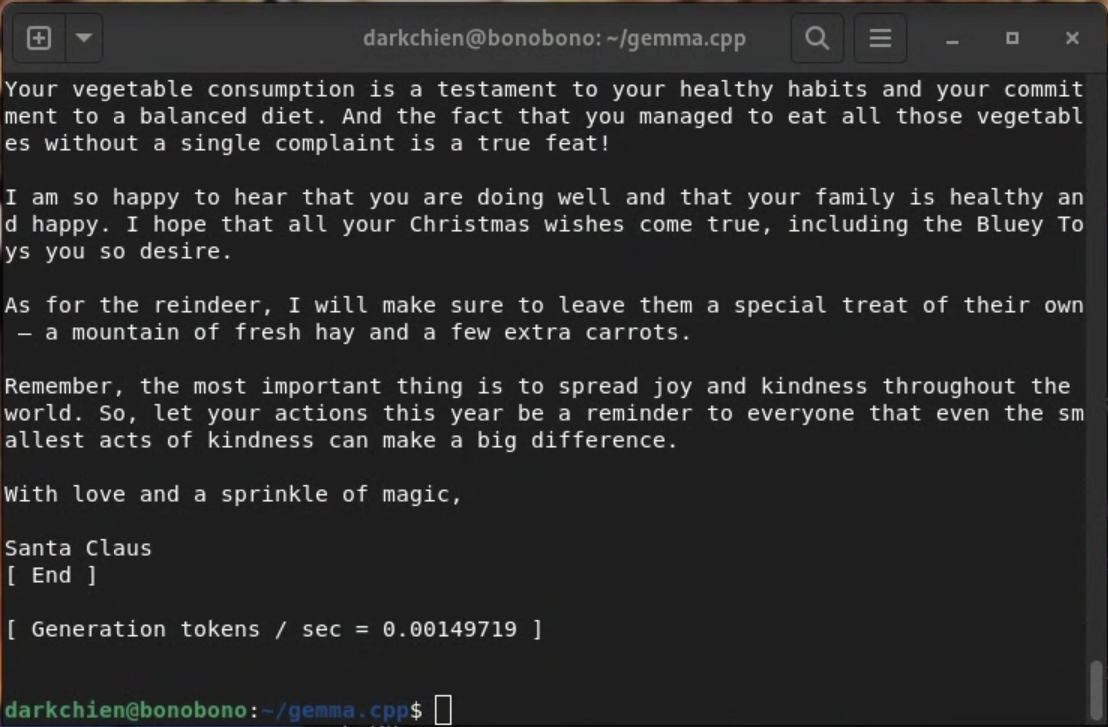
$ ./main -m models/gemma-2b-it.gguf --repeat-penalty 1.0 -p “You are Santa Claus, write a letter back from this kid.\n<start_of_turn>user\nPLACE_THE_CONTEXT_OF_LETTER_HERE<end_of_turn>\n<start_of_turn>model\n”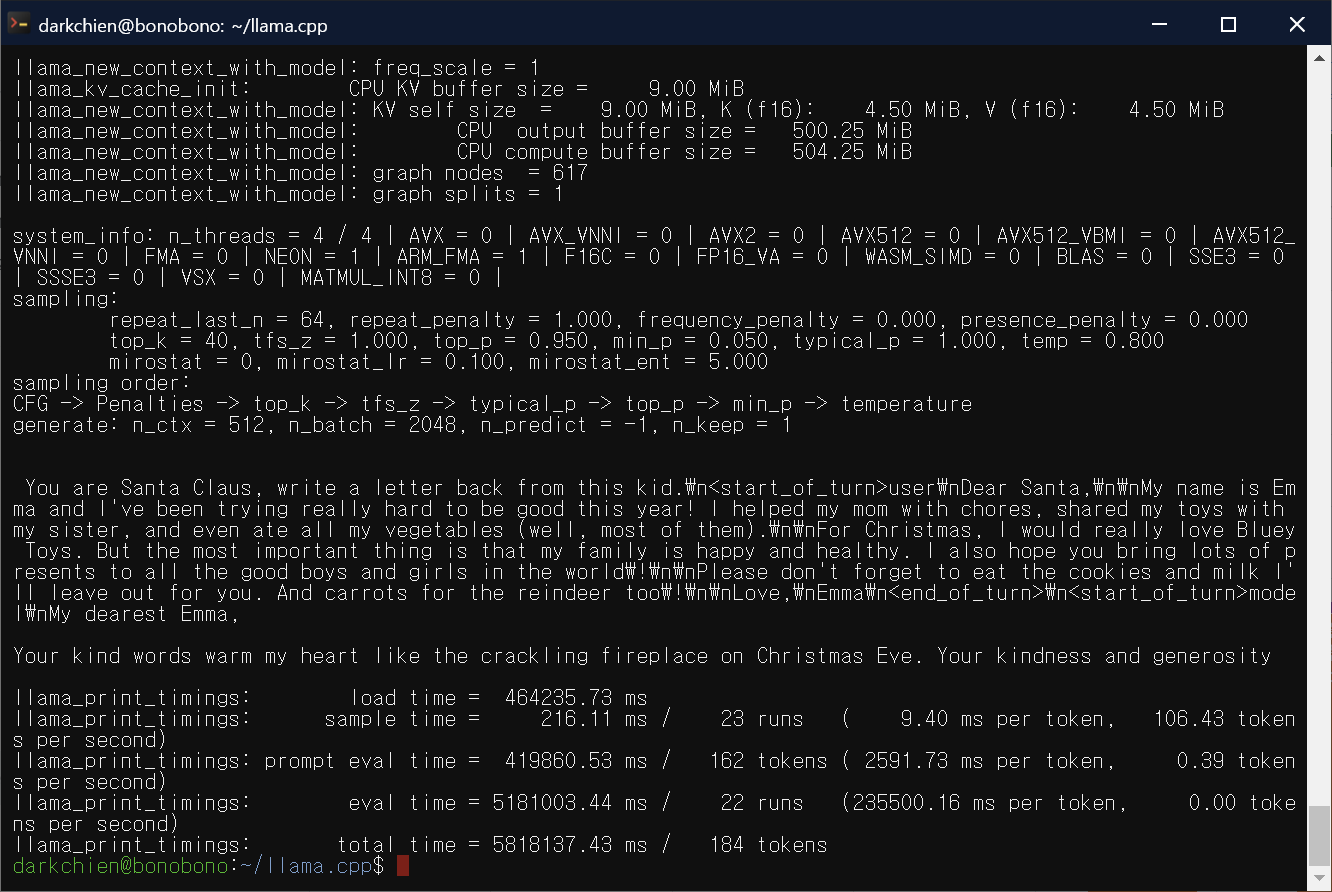
Gemma offers limitless possibilities. We hope these suggestions inspire you, and we eagerly anticipate seeing your creations come to life.
We encourage you to join the Google Developer Community Discord server. There, you can share your projects and connect with other like-minded individuals.
Happy tinkering!

An important update: Transitioning Gemini CLI to Antigravity CLI

Google Tensor SDK Beta with LiteRT

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Supercharging LLM inference on Google TPUs: Achieving 3X speedups with diffusion-style speculative decoding

New enhancements for merchant initiated transactions with the Google Pay API