
Gemma는 Gemini 모델을 만드는 데 사용되는 것과 동일한 연구와 기술로 개발된 개방형 모델 제품군입니다. 이 제품군에는 현재 Gemma, CodeGemma, PaliGemma, RecurrentGemma가 포함됩니다. 전체적으로 해당 모델들은 텍스트 생성, 코드 완성 및 생성, 많은 비전 언어 작업을 포함한 광범위한 작업을 수행할 수 있으며 에지부터 데스크톱과 클라우드까지 다양한 기기에서 실행할 수 있습니다. 더 나아가 특정한 필요에 맞게 Gemma 모델을 더 세밀하게 조정할 수도 있습니다.
Gemma는 AI 혁신에 박차를 가하는 개발자와 연구자로 구성된 개방형 커뮤니티를 위해 개발되었습니다. ai.google.dev/gemma에서 Gemma에 대해 자세히 알아보고 빠른 시작 가이드를 볼 수 있습니다.
오늘은 3가지 재미있는 프로젝트 아이디어와 Gemma 모델을 사용하여 프로젝트를 만드는 방법을 살펴보겠습니다.
한국어 문자, 즉 한글은 시간의 흐름에 따라 변화를 거듭했고 그 결과 몇몇 글자는 현대 한국어에는 더 이상 사용되지 않습니다. 사용되지 않는 글자에는 아래 4개가 있습니다.
2. ㆆ(여린히읗): 영어 알파벳 'h'를 좀 더 부드럽게 발음하는 '가벼운 ㅎ'으로 발음됩니다.
3. ㅿ(반시옷): 영어의 'z' 소리를 나타냅니다.
4. ㆁ(옛이응): 영단어 'sing'에서 'ng'와 비슷한 연구개음 콧소리입니다.
한국어 원어민도 이제 더 이상 사용되지 않는 글자로 쓰인 옛 문헌을 읽기란 쉽지 않습니다. 초창기 한글은 단어 사이에 공백이 없어 읽기가 더 난해합니다. 반면 현대 한글은 대부분의 알파벳 체계와 마찬가지로 띄어쓰기를 합니다.
Gemma의 기능을 사용하면 현대 한국어와 고대 한국어의 차이를 이해하고 그 간극을 메우는 데 도움이 되는 번역기를 만들 수 있습니다. SentencePiece는 Gemma 토크나이저의 기초 역할을 합니다. 언어별로 다른 지침이나 미리 정의된 사전에 크게 의존하는 기존 토크나이저와 달리 SentencePiece는 가공되지 않은 텍스트 데이터에 대해 직접 학습을 거칩니다. 따라서 어떤 특정 언어로부터도 독립적이며 다양한 형태의 텍스트 데이터에 적응할 수 있게 됩니다.
Software
작업 단순화를 위해 다음의 구조를 채택하여 모델을 미세 조정할 것입니다. 이 모델은 사용자가 입력한 초창기 한글을 기반으로 현대 한국어 텍스트를 생성합니다.

명령 튜닝(IT) 모델은 특정 포맷터로 학습됩니다. 제어 토큰은 다음과 같은 방식으로 단일 토큰으로 토큰화됩니다.

모델 학습에는 조선시대의 언문 소설 '홍길동전'을 사용합니다.
모델의 출력 품질을 평가하기 위해 학습 데이터 세트 외부의 텍스트, 구체적으로는 작가 미상의 한국 고전 소설 '숙영낭자전'을 사용하겠습니다.
이 모델은 초창기 한글을 번역할 수 없습니다.

미세 조정 후, 응답은 지시를 따르며 초창기 한글 텍스트를 기반으로 한 현대 한국어 텍스트를 생성합니다.

참고로, 사람이 번역한 텍스트는 다음과 같습니다.
“금두꺼비가 품에 드는 게 보였으니 얼마 안 있어 자식을 낳을 것입니다.
하였다. 과연 그 달부터 잉태하여 십삭이 차니”
참고: 위 한국어 텍스트는 "내가 그녀의 품에 안긴 황금 두꺼비를 보았으므로 조만간 아기를 낳을 겁니다. 아니나 다를까, 그 달에 임신해 이제 열 달이 지났습니다."란 뜻입니다.
또 다른 출력 예가 있습니다.

그리고 아래는 사람에 의한 번역문입니다.
“이때는 사월 초파일이었다. 이날 밤에 오색구름이 집을 두르고 향내 진동하며 선녀 한 쌍이 촉을 들고 들어와 김생더러 말하기를,”
참고: 위 한국어 텍스트는 "때는 4월 8일이었다. 이날 밤, 오색구름이 집을 둘러싸고 향기가 진동하는 가운데 한 쌍의 선녀가 촛불을 들고 들어와 김생에게 이렇게 말했다."라는 뜻입니다.
번역이 나무랄 데 없는 것은 아니지만 초안 치고는 괜찮습니다. 데이터 세트가 책 한 권으로 제한되어 있다는 점을 고려하면 놀라운 결과입니다. 데이터 소스의 다양성을 향상하면 번역 품질이 개선될 수 있을 것입니다.
모델을 미세 조정하면 이를 간단히 Kaggle과 Hugging Face에 게시할 수 있습니다.
아래는 이에 대한 예입니다.
# 미세 조정된 모델 저장
gemma.save_to_preset("./old-korean-translator")
# Kaggle에서 모델 대안 업로드
kaggle_uri = "kaggle://my_kaggle_username/gemma-ko/keras/old-korean-translator"
keras_nlp.upload_preset(kaggle_uri, "./old-korean-translator")유사한 작업을 완료하기 위해 동일한 구조를 복제할 수 있습니다. 다음은 몇 가지 예입니다.
일상생활과 관련된 다양한 사물과 개념은 지역에 따라 다르게 불립니다. 예를 들어, 미국 영어(AmE) 화자들은 'elevator', 'truck', 'cookie', 'french fries'를 사용하는 반면, 영국 영어(BrE) 화자들은 각각 'lift', 'lorry', 'biscuit', 'chips'를 사용합니다.
어휘 차이 외에 철자를 다르게 쓰는 경우도 있습니다. 예를 들어, AmE에서 '-or'로 끝나는 단어는 종종 BrE에서 '-our'로 끝납니다. 'color'(AmE)와 'colour'(BrE), 'humor'(AmE)와 'humour'(BrE)를 예로 들 수 있습니다.
철자를 서로 다르게 쓰는 또 다른 예로는 '-ize'와 '-ise'의 차이를 들 수 있습니다. AmE에서는 'organize' 및 'realize'와 같은 단어에 공통적으로 'z'를 쓰는 반면, BrE에서는 's'를 사용하여 'organise'와 'realise'로 쓰는 것을 선호합니다.
Gemma와 같은 AI 도구를 사용하면 한 지역의 영어에서 다른 지역의 영어로 스타일 전이를 생성할 수 있으므로, 미국식 영어와 영국식 영어 쓰기 스타일 사이에 전환이 원활해집니다.
일본의 간사이 지역에는 간사이 벤으로 알려진 뚜렷이 구분되는 방언이 사용됩니다. 표준 일본어와 비교할 때, 원어민들은 간사이 벤의 발음과 억양이 더욱 선율적이고 세다고 인식합니다.
Gemma의 기능을 활용하여 상당량의 간사이 벤 데이터 세트를 준비하여 방언 번역기를 만들 수 있습니다.
믿음직한 동반자로서 Gemma와 함께라면 매혹적인 게임을 만드는 여정에 나설 수 있습니다. 모든 것은 게임 콘셉트의 기초가 되는 간단한 핵심 문장인 '피치'에서 시작됩니다. 게임의 콘셉트를 구체화하고, 복잡한 메인 캐릭터를 창조하고, 마음을 사로잡는 메인 스토리를 창작하여 플레이어를 게임의 세계에 몰입시킬 수 있도록 Gemma가 능숙하게 여러분을 안내할 것입니다.
Software
핵심 개념 작성부터 시작해 아래와 같은 게임에 대한 한 문장의 피치:

Gemma는 피치를 기본으로 해서 더 많은 세부 정보를 추가할 수 있습니다.
입력: "아래에 주어진 핵심 개념으로 이 게임에 대해 자세히 설명하세요.\n{pitch}"
출력 예시:

입력: "메인 캐릭터 디자인"
출력 예시:

입력: "빌런 캐릭터 디자인"
출력 예시:

입력: "이 게임의 메인 스토리를 기승전결의 구조로 작성하세요."
출력 예시:

프롬프트를 수정하면 거의 모든 유형의 창작 콘텐츠에 대해 비슷한 도우미를 얻을 수 있습니다.
피치: "새로운 스팀 구동식 칫솔"
입력: "아래 신제품을 홍보하는 마케팅 문구를 생성하세요.\n{pitch}"
출력 예시:

피치: “우주와 유성”
입력: "적합한 꽃에 대한 제안과 함께 아래 콘셉트에서 영감을 얻은 플로리스트 아이디어를 생성하세요.\n{pitch}"
출력 예시:

피치: “사이버펑크 크라켄”
입력: "아래 콘셉트의 요리 레시피를 생성하세요.\n{pitch}"
출력 예시:

산타에게 편지를 보내는 전통적인 방법은 한계가 있기도 하고 정서적인 따스함이 없을 수도 있습니다. 아이들은 답장을 받으려 종종 몇 주나 몇 달을 목이 빠지게 기다려야 하고 도착한 답장은 아이들이 원하는 상세한 내용이나 대화 형식이 아닐 수도 있습니다.
이 프로젝트에서는 Raspberry Pi에서 실행되는 Gemma를 사용하여 대규모 언어 모델의 힘을 통해 산타가 보내는 마법의 편지를 작성합니다.
하드웨어
Software
텍스트 생성
libgemma로 자체적인 C++ 애플리케이션을 작성할 수 있습니다.
아래 프롬프트를 사용하여 모델에 지시하세요.

빌드하기 전에 코드에 정의된 MODEL_PATH를 수정하세요.
$ g++ santa.cc -I . -I build/_deps/highway-src -I build/_deps/sentencepiece-src build/libgemma.a build/_deps/highway-build/libhwy.a build/_deps/sentencepiece-build/src/libsentencepiece.so -lstdc++ -l실행
$ LD_LIBRARY_PATH=./build/_deps/sentencepiece-build/src ./a.outletter.txt에서 텍스트를 읽고 산타클로스가 보내는 편지를 생성합니다.
참고: Raspberry Pi에서 텍스트를 생성하는 데 다소 시간이 걸릴 수 있습니다.

최종 결과는 다음과 같습니다.
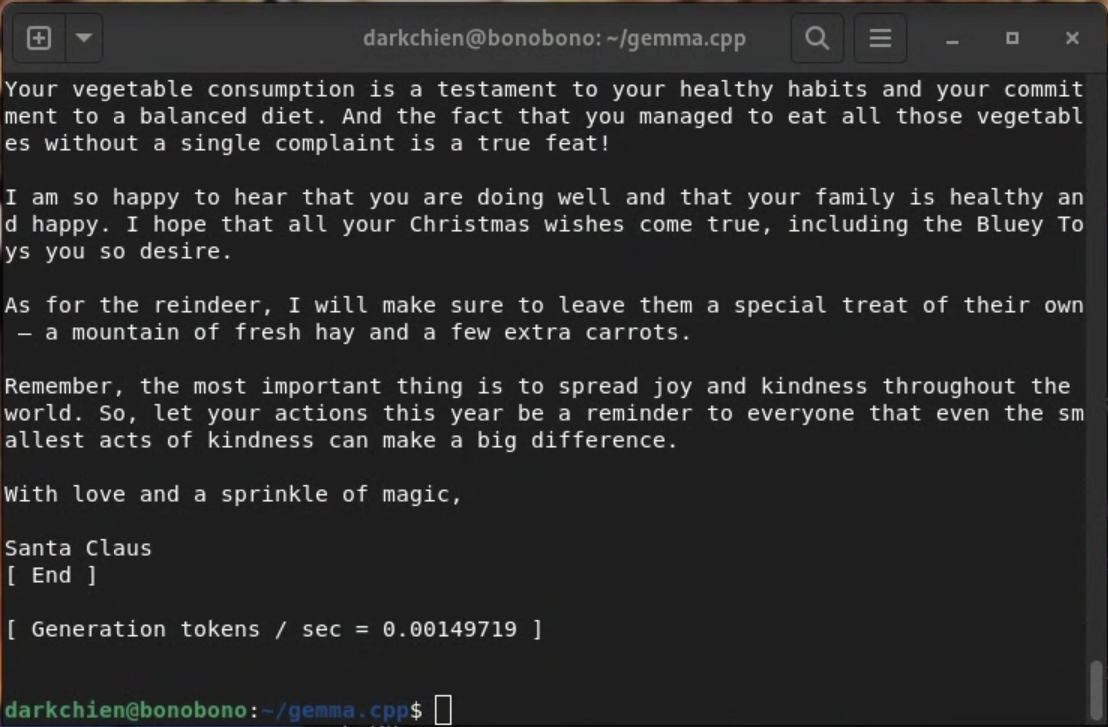
$ ./main -m models/gemma-2b-it.gguf --repeat-penalty 1.0 -p “당신은 산타클로스입니다. 이 아이에게 답장을 써주세요.\n<start_of_turn>user\nPLACE_THE_CONTEXT_OF_LETTER_HERE<end_of_turn>\n<start_of_turn>model\n”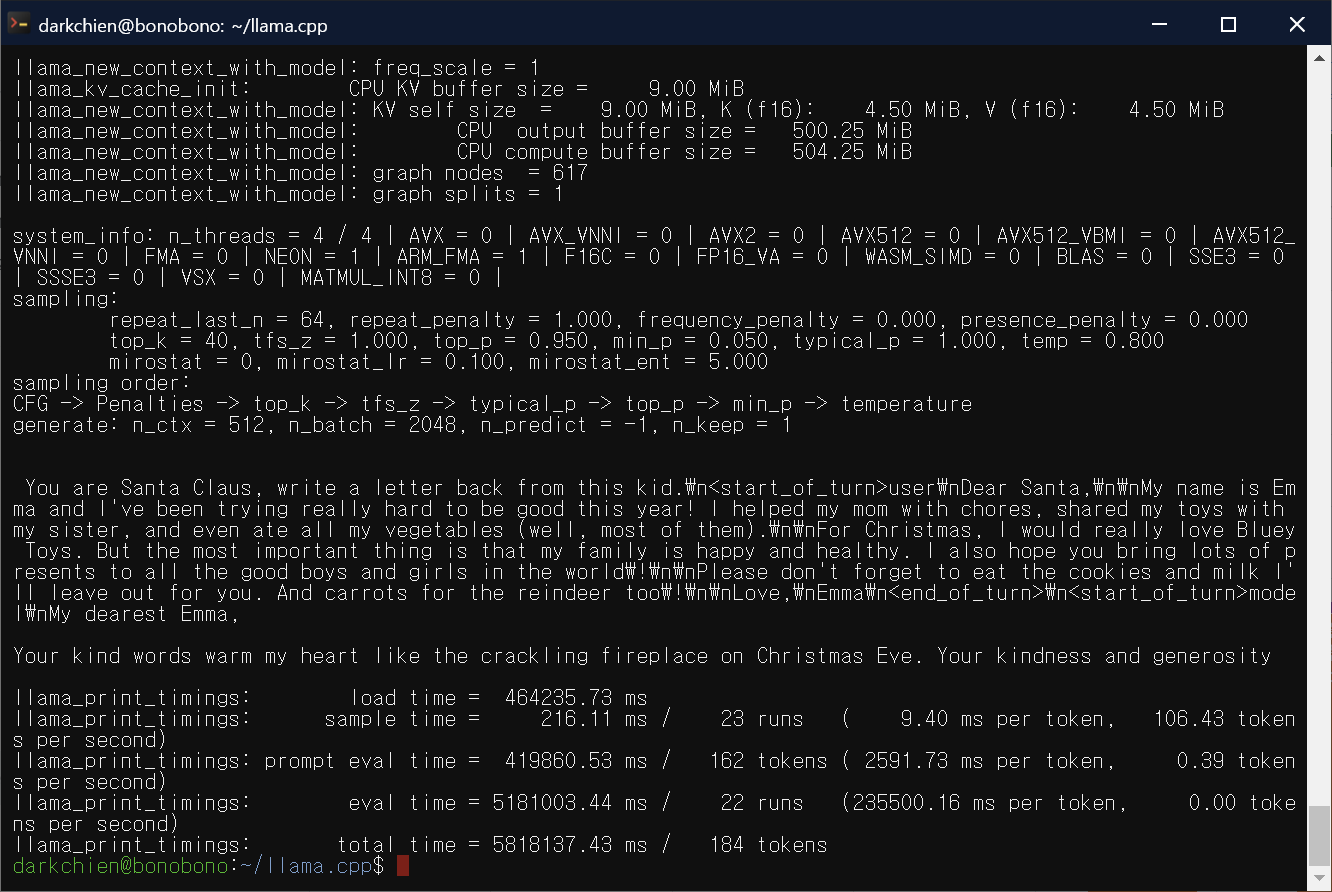
Gemma는 무한한 가능성을 제공합니다. 앞서 제공한 여러 제안이 여러분께 영감을 드렸길 바라며, 여러분의 작품이 현실로 구현되기를 간절히 기대합니다.
Google 개발자 커뮤니티 Discord 서버에 가입하시길 추천합니다. 그곳에서 프로젝트를 공유하고 같은 생각을 가진 여러 사람들과 소통할 수 있습니다.
즐겁게 사용해 보세요!

Announcing the Data Commons Gemini CLI extension

Grain 및 ArrayRecord를 사용하여 고성능 데이터 파이프라인 구축

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

LangChain4j 통합을 통해 타사 언어 모델에도 개방되는 자바용 ADK