

The way AI visually understands images has evolved tremendously. Initially, AI could tell us "where" an object was using bounding boxes. Then, segmentation models arrived, precisely outlining an object's shape. More recently, open-vocabulary models emerged, allowing us to segment objects using less common labels like "blue ski boot" or "xylophone" without needing a predefined list of categories.
Previous models matched pixels to nouns. However, the real challenge — conversational image segmentation (closely related to referring expression segmentation in the literature) — demands a deeper understanding: parsing complex descriptive phrases. Rather than just identifying "a car," what if we could identify "the car that is farthest away?"
Today, Gemini's advanced visual understanding brings a new level of conversational image segmentation. Gemini now "understands" what you're asking it to "see."
The magic of this feature lies in the types of questions you can ask. By moving beyond simple single-word labels, you can unlock a more intuitive and powerful way to interact with visual data. Consider the 5 categories of queries below.
Gemini can now identify objects based on their complex relationships to the objects around them.
1: Relational understanding: "the person holding the umbrella"
2: Ordering: "the third book from the left"
3: Comparative attributes: "the most wilted flower in the bouquet"
Sometimes you need to query with conditional logic. For example, you can filter with queries like "food that is vegetarian". Gemini can also handle queries with negations like "the people who are not sitting".

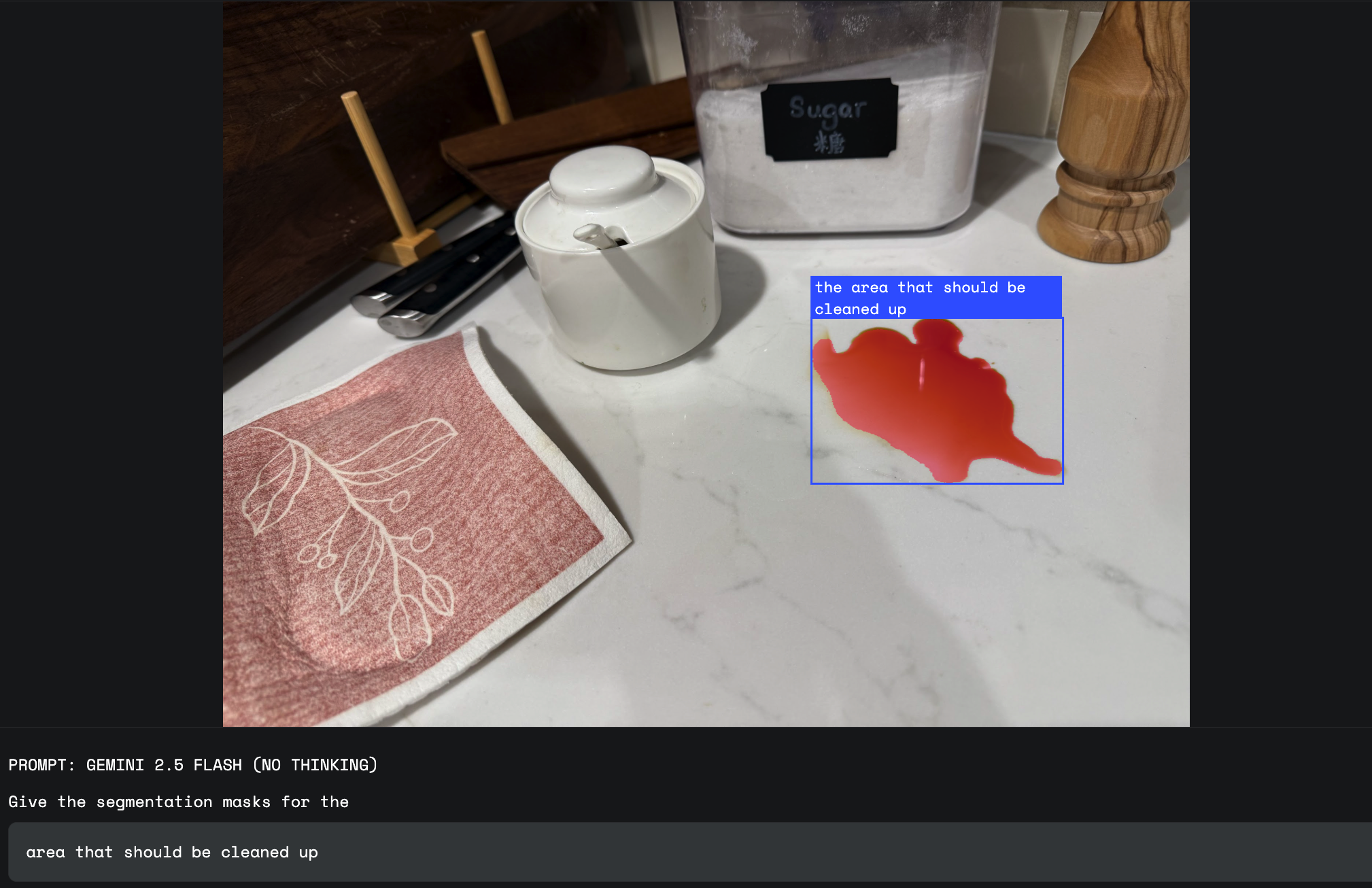
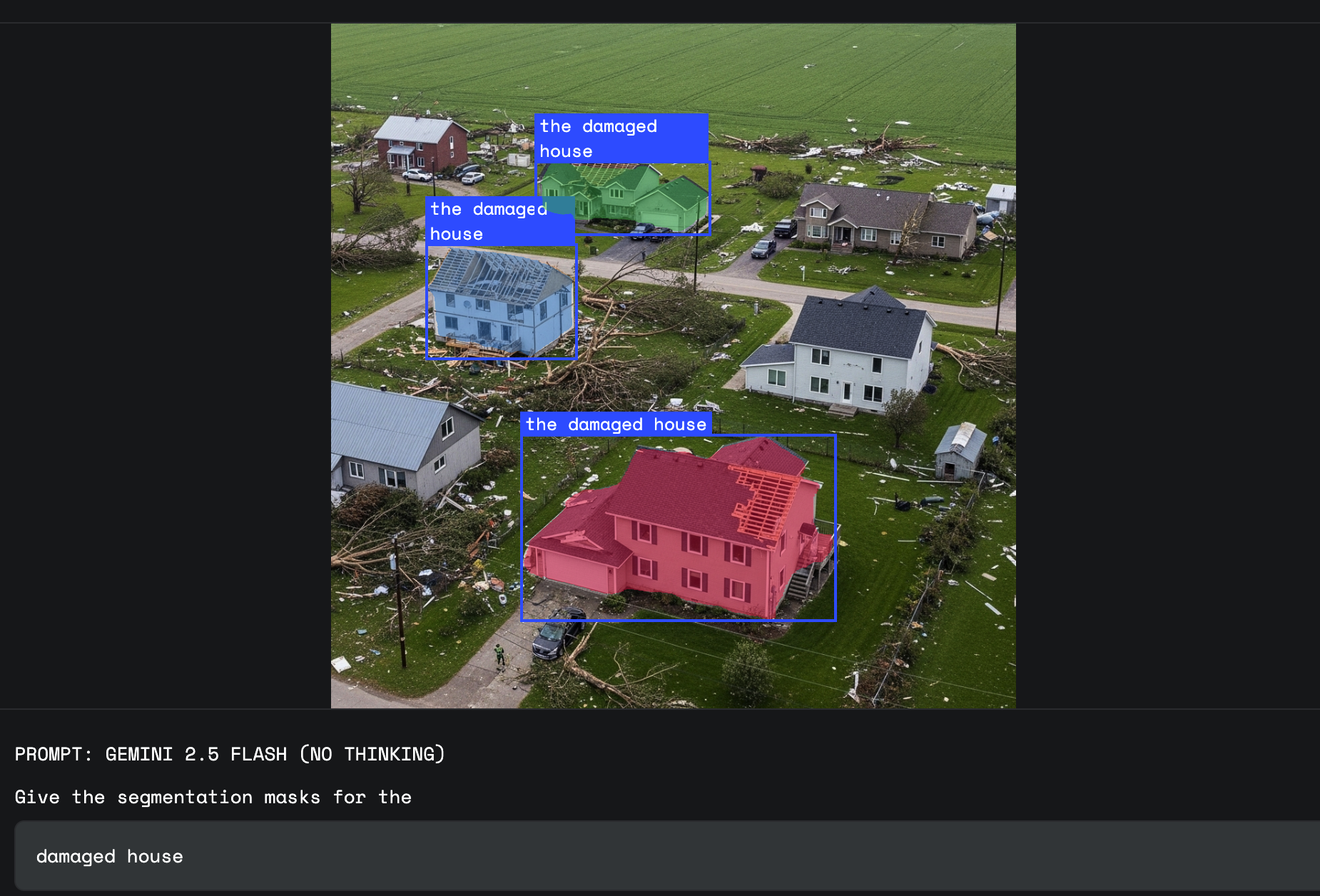
This is where Gemini's world knowledge shines. You can ask it to segment things that don't have a simple, fixed visual definition. This includes concepts like "damage," "a mess," or "opportunity."
When appearance alone is not enough to distinguish the precise category of an object, the user might refer to it through a written text label present in the image. This requires OCR abilities for the model, one of the strengths of Gemini 2.5.
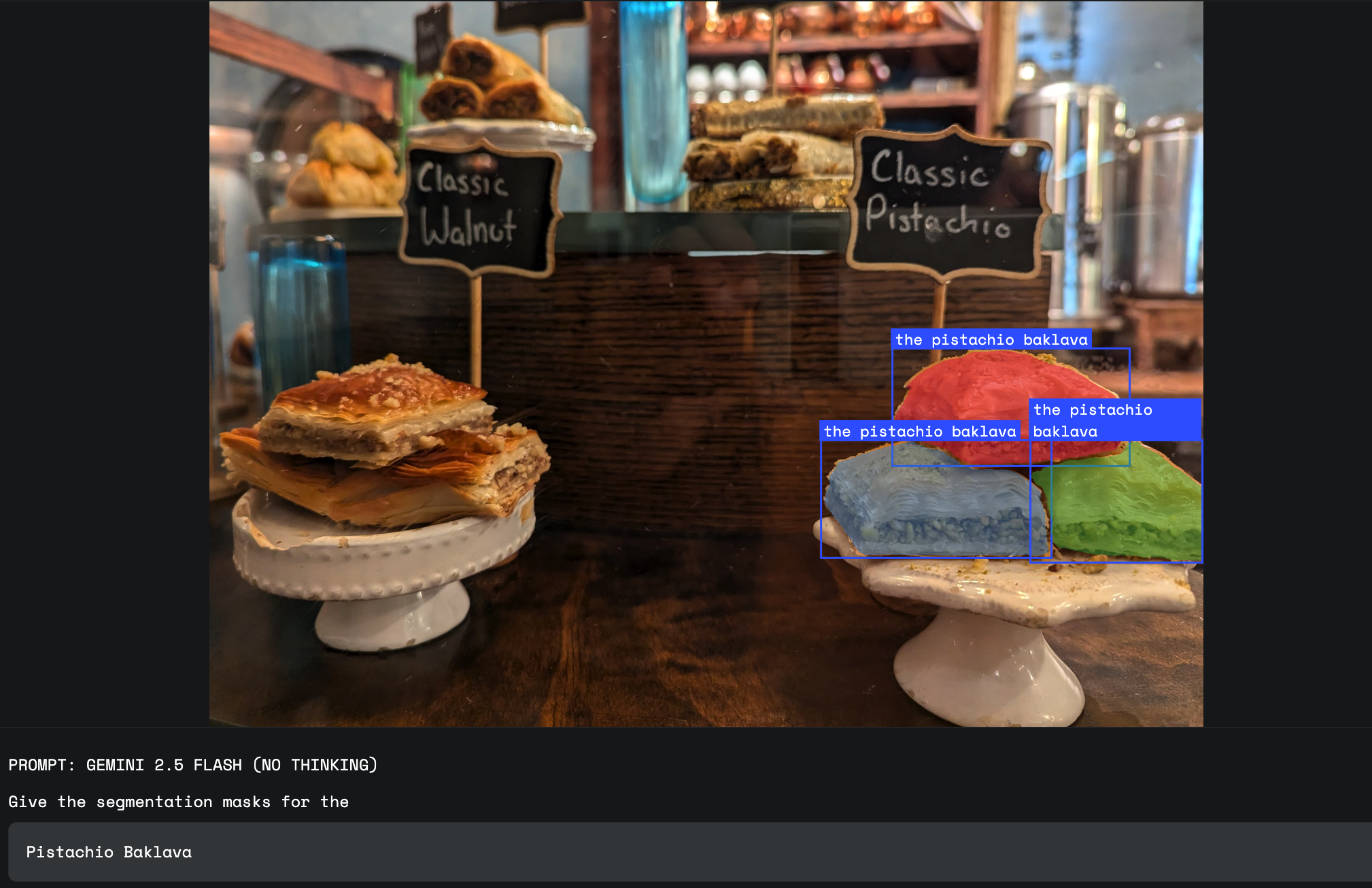
Gemini is not restricted to a single language and can handle labels in many different languages.

Let's explore how these query types could enable new use cases.
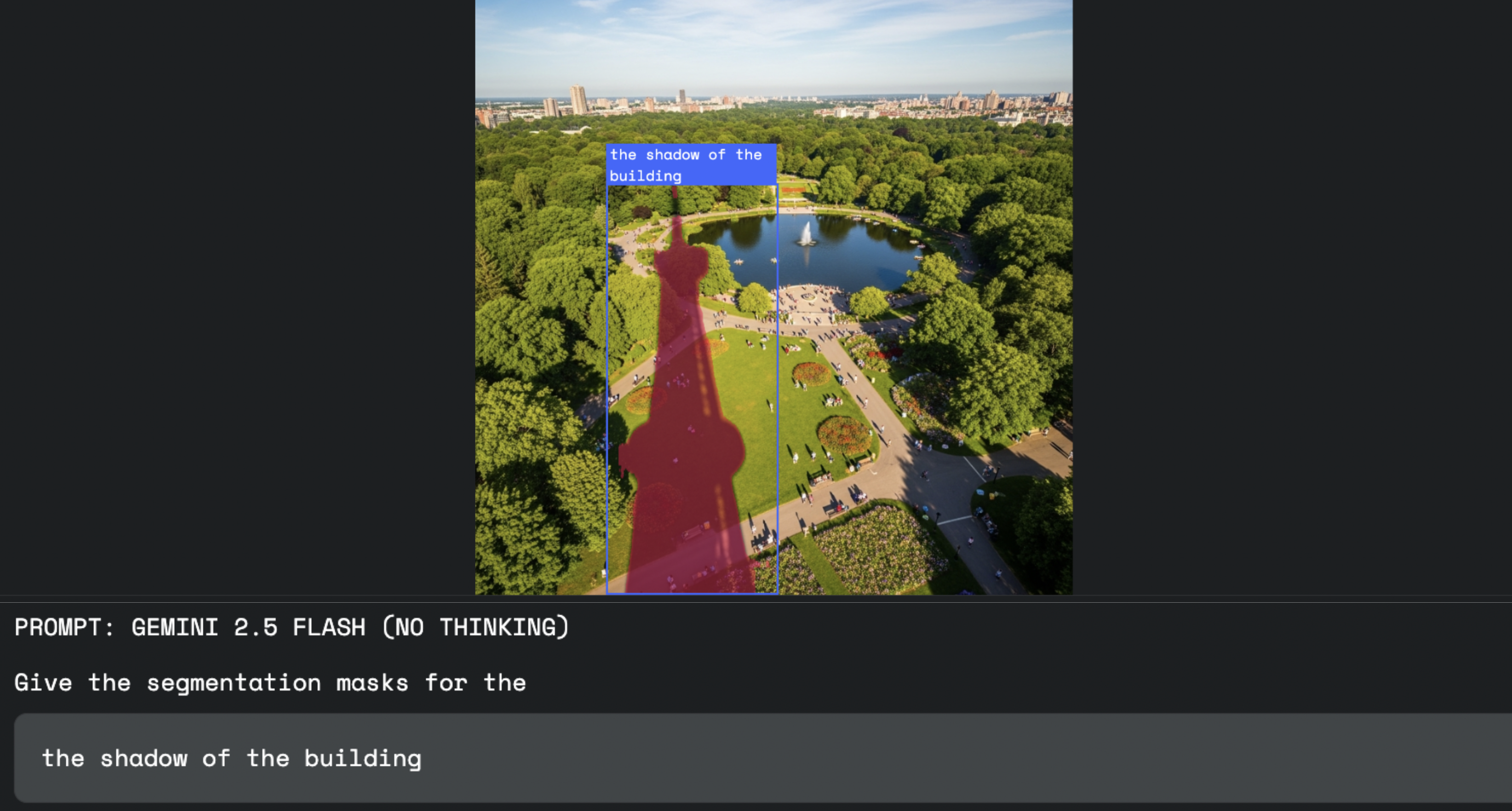
This capability transforms creative workflows. Instead of using complex selection tools, a designer can now direct software with words. This allows for a more fluid and intuitive process, like when asking to select "the shadow cast by the building".
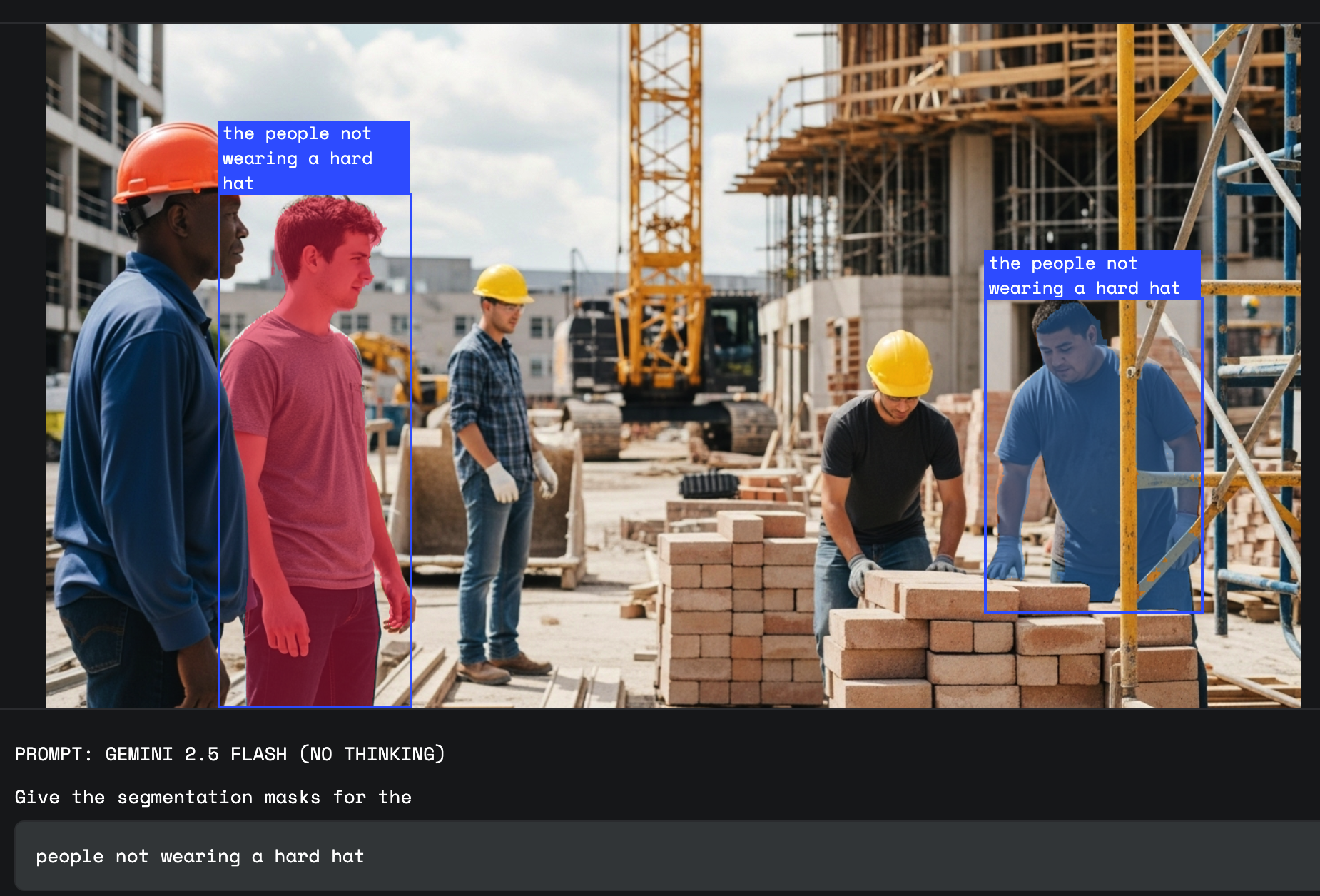
For workplace safety, you need to identify situations, not just objects. With a prompt like, "Highlight any employees on the factory floor not wearing a hard hat", Gemini comprehends the entire conditional instruction as a single query, producing a final, precise mask of only the non-compliant individuals.
"Damage" is an abstract concept with many visual forms. An insurance adjuster can now use prompts like, "Segment the homes with weather damage” and Gemini will use its world knowledge to identify the specific dents and textures associated with that type of damage, distinguishing it from a simple reflection or rust.
1: Flexible Language: Move beyond rigid, predefined classes. The natural language approach gives you the flexibility to build solutions for the "long tail" of visual queries that are specific to your industry and users.
2: Simplified Developer Experience: Get started in minutes with a single API. There is no need to find, train, and host separate, specialized segmentation models. This accessibility lowers the barrier to entry for building sophisticated vision applications.
We believe that giving language a direct, pixel-level connection to vision will unlock a new generation of intelligent applications. We are incredibly excited to see what you will build.
Get started right away in Google AI Studio via our interactive:
Or if you’d prefer a Python environment, feel free to start with our interactive Spatial Understanding colab.
To start building with the Gemini API, visit our developer guide and read more about starting with segmentation. You can also join our developer forum to meet other builders, discuss your use cases, and get help from the Gemini API team.
For best results, we recommend following the following best practices:
1: Use the gemini-2.5-flash model
2: Disable thinking set (thinkingBudget=0)
3: Stay close to the recommended prompt, and request JSON as output format.
Give the segmentation masks for the objects.
Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d", the segmentation mask in key "mask", and the text label in the key "label".
Use descriptive labels.We thank Weicheng Kuo, Rich Munoz, and Huizhong Chen for their work on Gemini segmentation, Junyan Xu for work on infrastructure, Guillaume Vernade for work on documentation and code samples, and the entire Gemini image understanding team, culminating in this release. Finally, we would like to thank image understanding leads Xi Chen and Fei Xia and multimodal understanding lead Jean-Baptiste Alayrac.

Introducing Gemini 2.5 Flash Image, our state-of-the-art image model

Architecting efficient context-aware multi-agent framework for production

Beyond the terminal: Gemini CLI comes to Zed
Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Announcing the Data Commons Gemini CLI extension

Announcing User Simulation in ADK Evaluation