

AI가 시각적으로 이미지를 파악하는 방식은 엄청난 발전을 거듭해 왔습니다. 초기 AI는 경계 상자를 사용하여 객체가 '어디'에 있는지 알려주었죠. 이후 객체의 형태를 정밀하게 잡아내는 분할 모델이 도래했고, 보다 최근에는 open-vocabulary 모델이 등장하여 카테고리 목록을 사전에 정의하지 않아도 '파란색 스키 부츠', '실로폰' 같은 덜 흔한 라벨을 사용하여 객체를 분할할 수 있게 되었습니다.
이전 모델은 픽셀을 명사와 매칭했습니다. 하지만 진정한 과제는 문헌의 지시 표현 분할과 밀접한 관련이 있는 대화형 이미지 분할 기능으로, 복잡한 서술 구문을 분석하는 것과 같은 더욱 심층적인 이해입니다. 단순히 '차'를 인식하는 대신 '가장 멀리 있는 차'를 인식할 수 있다면 어떨까요?
오늘날, Gemini의 발전된 시각적 이해는 새로운 수준의 대화형 이미지 분할을 지원합니다. 이제 Gemini는 '보라고' 요청받은 것을 '이해'합니다.
이 기능의 비밀은 물을 수 있는 질문의 유형에 있습니다. 단순한 한 단어 라벨을 넘어선 더 직관적이고 강력한 방법으로 시각적 데이터와 상호작용을 할 수 있습니다. 아래의 5가지 쿼리 카테고리를 살펴보세요.
Gemini는 이제 주변에 있는 객체들과의 복잡한 관계에 기반하여 객체를 인식합니다.
1: 관계적 이해: '우산을 들고 있는 사람'
2: 순서: '왼쪽에서 세 번째 책'
3: 상대적 속성: '꽃다발에서 가장 시든 꽃'
종종 조건부 로직을 사용하여 쿼리해야 할 때가 있습니다. 예를 들어 '채식주의자용 음식'과 같은 쿼리를 필터링할 수 있습니다. Gemini는 '앉아 있지 않은 사람'과 같은 부정이 포함된 쿼리도 처리할 수 있습니다.

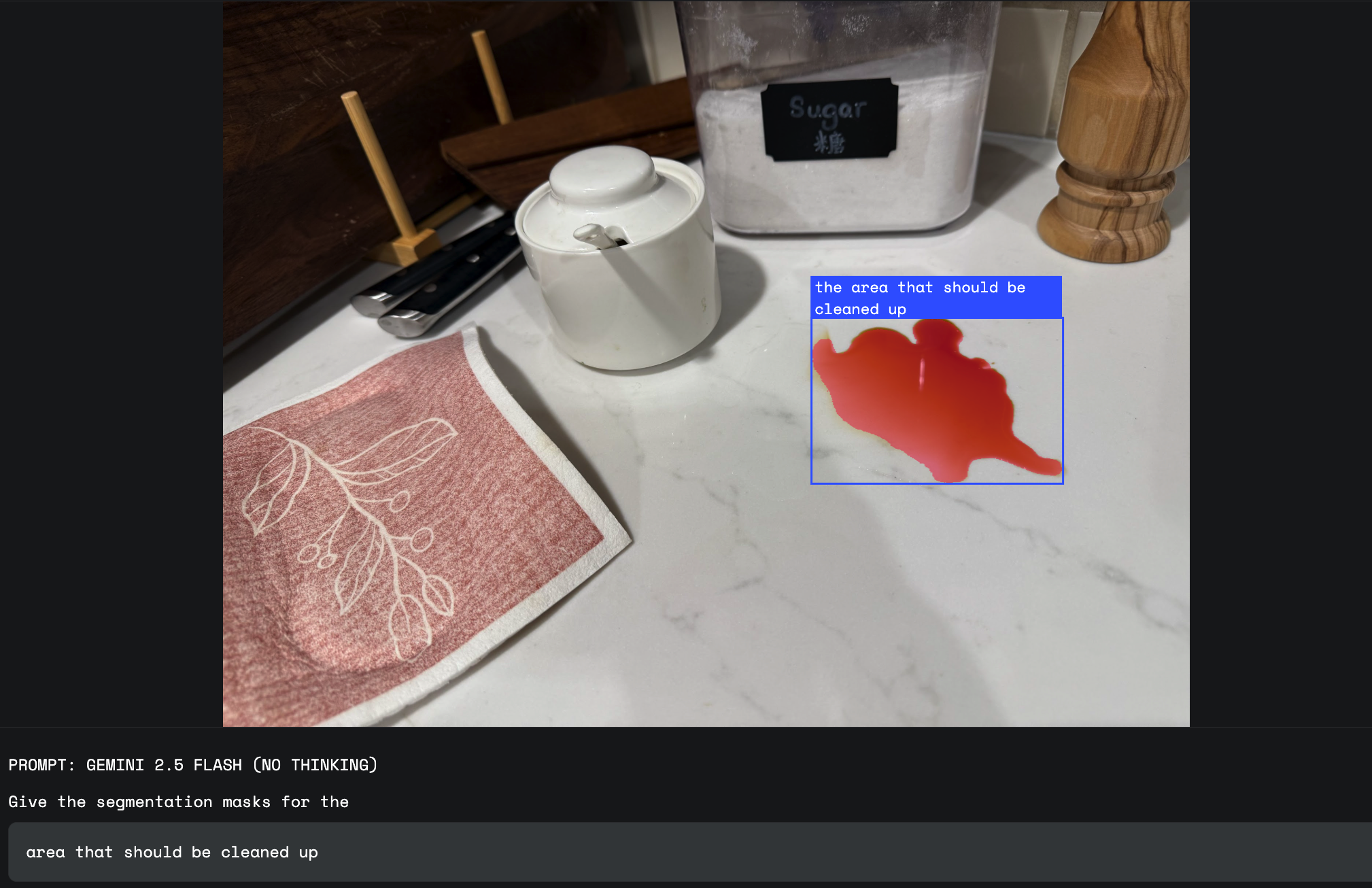
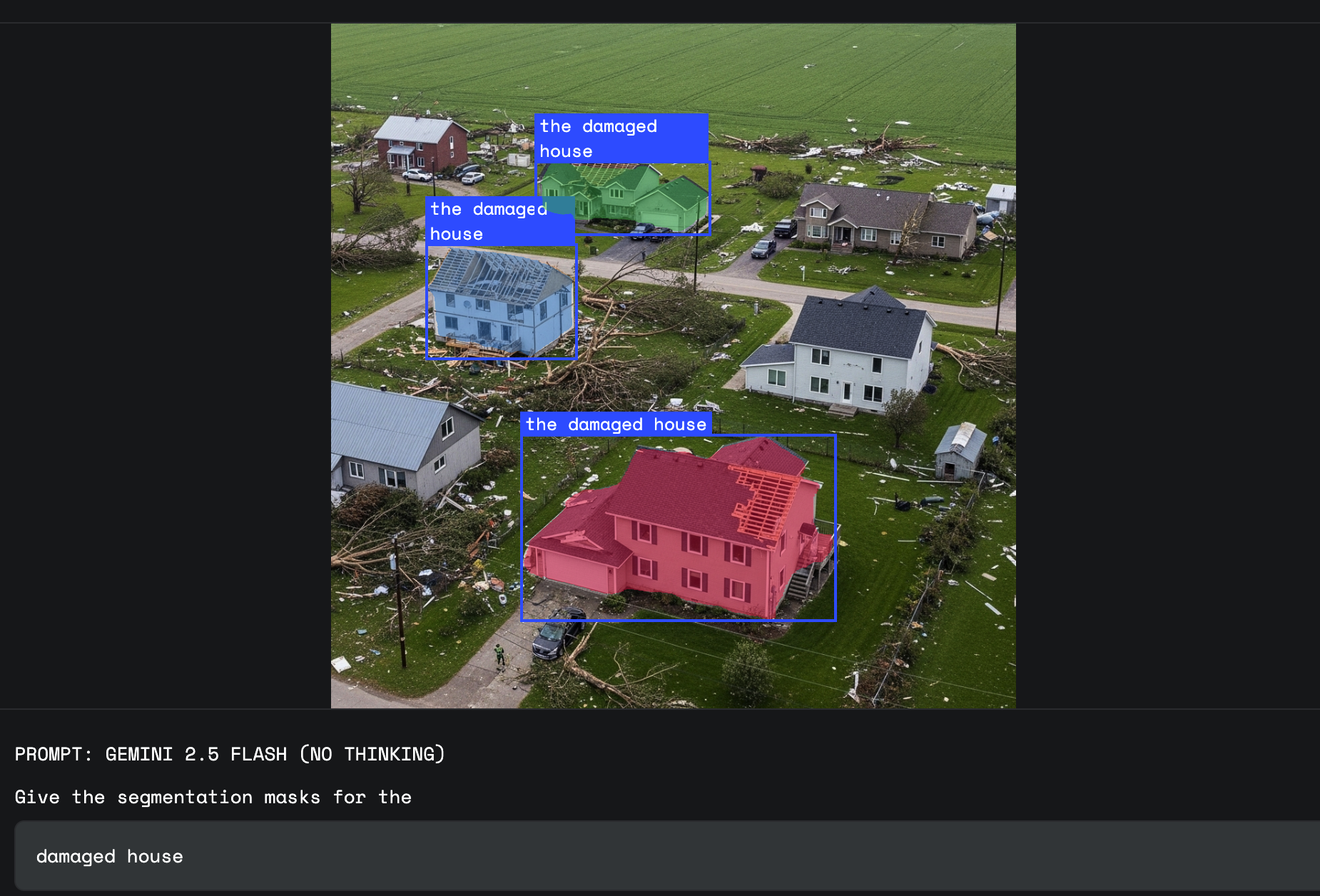
이 카테고리는 Gemini가 지닌 세계에 대한 지식이 빛을 발하는 영역입니다. Gemini에게 단순하고 고정된 시각적 정의를 지니지 않는 대상을 분할하라고 요청할 수 있습니다. 여기에는 '손해', '엉망' 또는 '기회'와 같은 개념이 포함됩니다.
외양만으로는 객체의 정확한 카테고리를 구분할 수 없는 경우 사용자는 이미지에 적힌 텍스트 라벨을 통해 해당 객체를 나타낼 수 있습니다. 이를 위해서는 모델에 OCR 기능이 있어야 합니다. 이 기능은 Gemini 2.5의 강점 중 하나입니다.
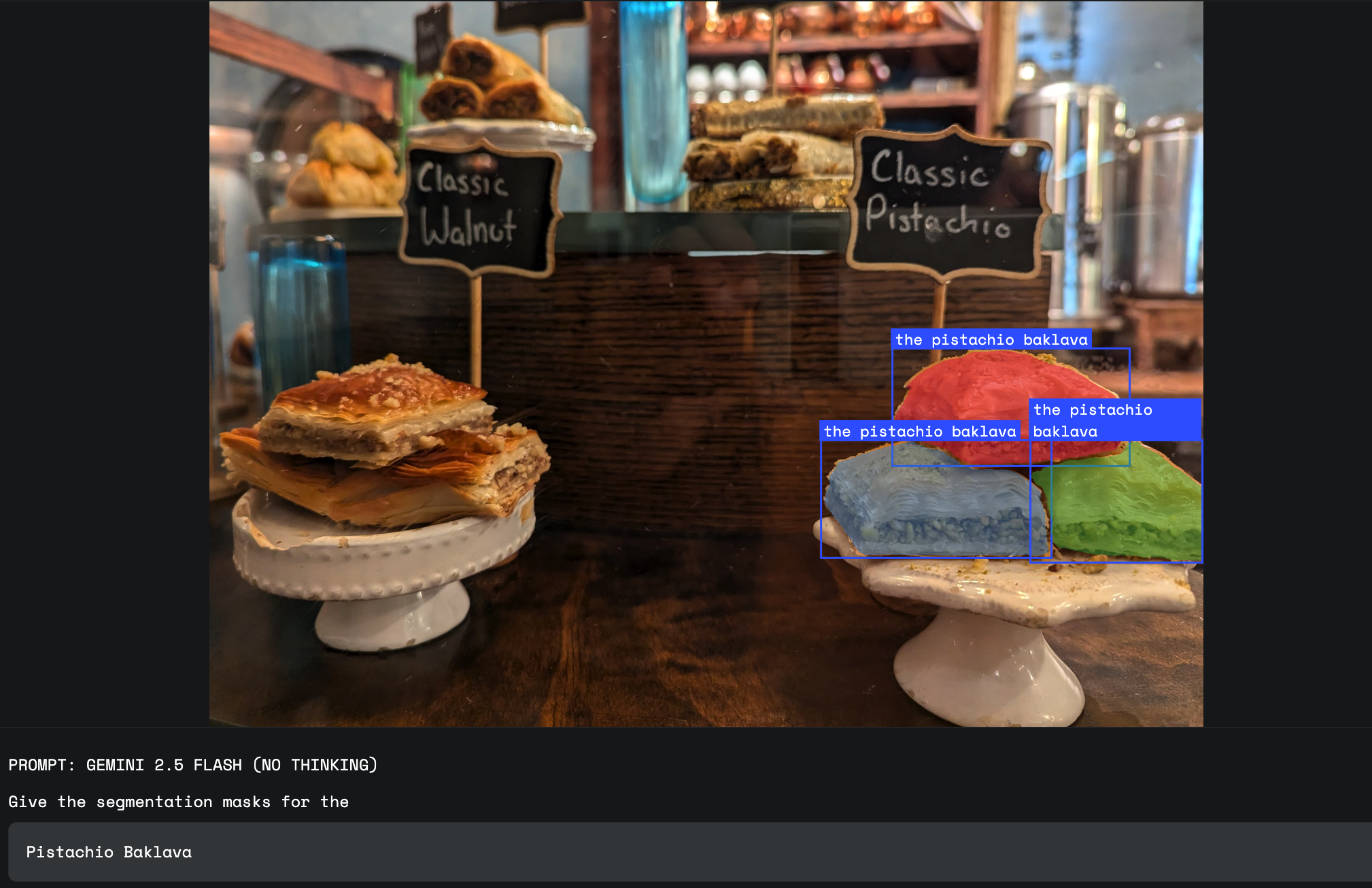
Gemini는 단일 언어에 국한되지 않으며 다양한 언어로 쓰인 라벨을 처리할 수 있습니다.

이러한 쿼리 유형이 새로운 이용 사례를 지원하는 방식을 알아보세요.
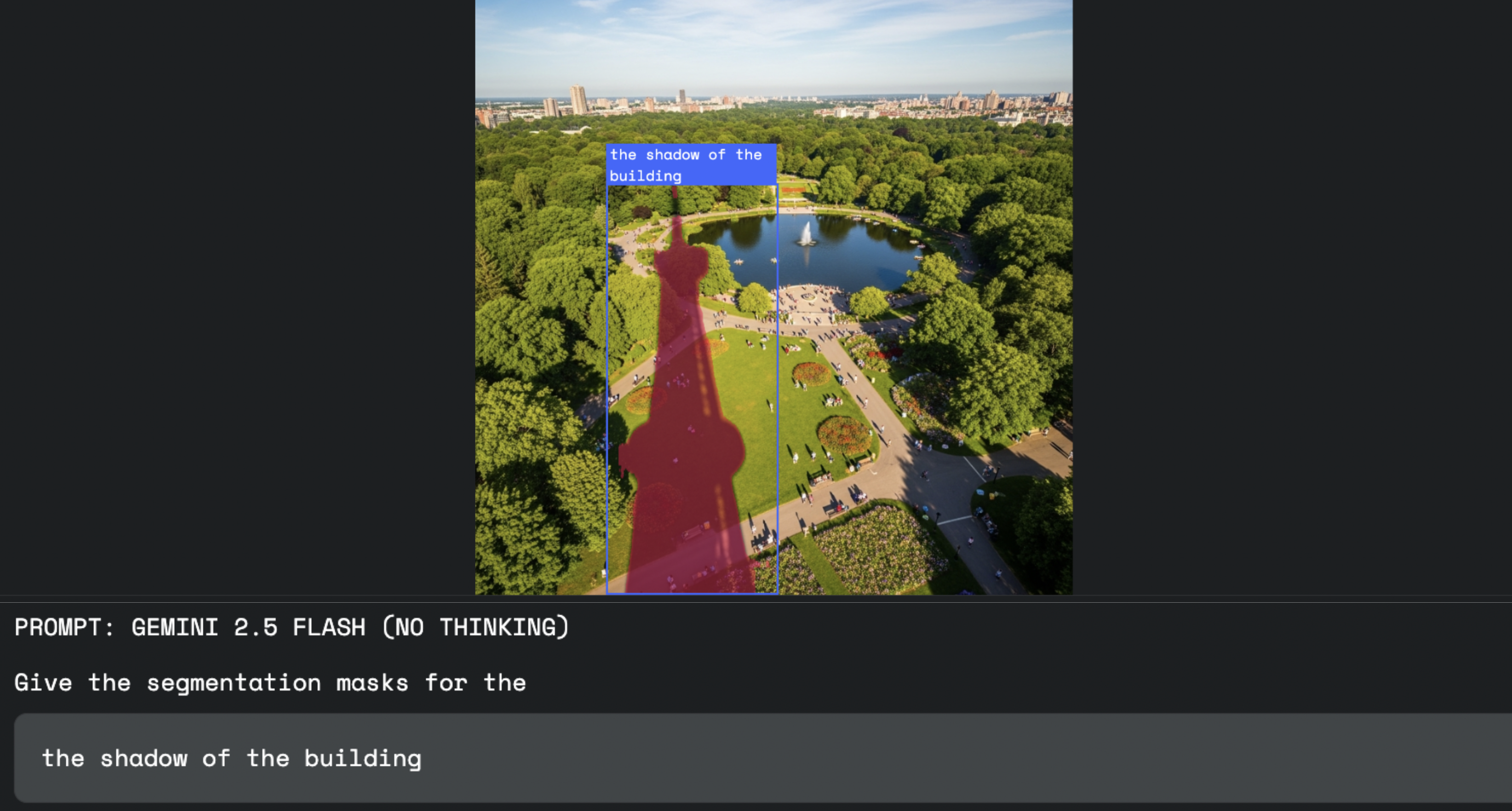
이 기능은 창의력이 필요한 워크플로를 탈바꿈합니다. 디자이너는 이제 복잡한 선택 도구를 사용하는 대신 단어로 소프트웨어를 지휘할 수 있습니다. 이로써 '건물이 드리운 그림자'를 선택하라고 요청하는 것처럼 과정이 더욱 유연하고 이해하기 쉬워집니다.
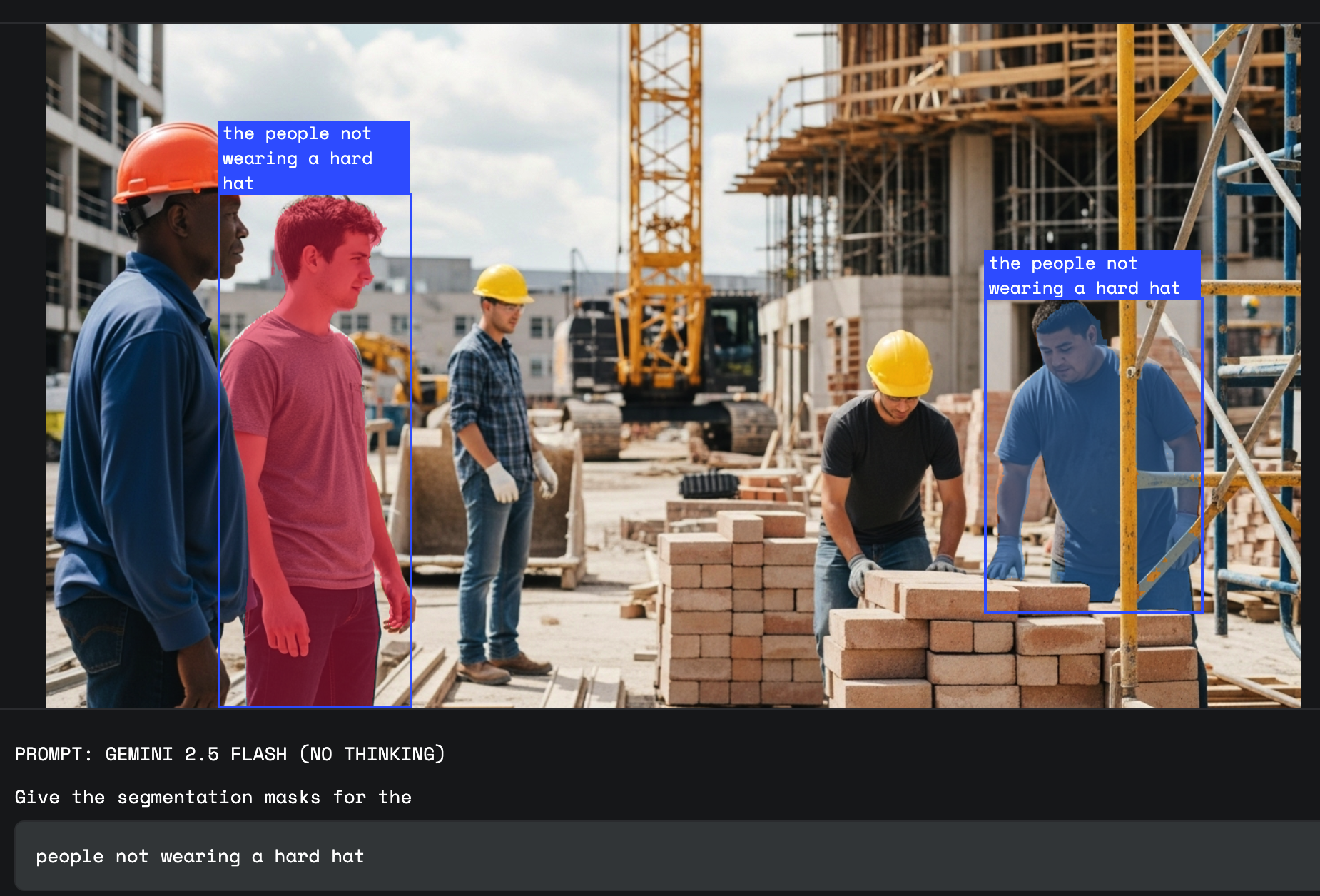
일터의 안전을 유지하려면 객체가 아닌 상황을 인식해야 합니다. '안전모를 쓰지 않고 작업 현장에 있는 모든 직원 강조표시'와 같은 프롬프트를 사용하면 Gemini가 전체 조건부 지시를 단일 쿼리로 인식하고 규정을 준수하지 않은 개인만 표시한 정밀한 최종 마스크를 생산합니다.
'손해'는 여러 시각적 형태를 가지는 추상적 개념입니다. 보험 청구 사정인은 이제 '기상 재해를 입은 집 분할하기'와 같은 프롬프트를 사용할 수 있으며, Gemini는 세계에 대한 지식을 사용하여 손해 유형과 관련된 특정 움푹 들어간 부분과 결을 인식하고 해당 부분을 단순 반사나 녹으로부터 구분합니다.
1: 유연한 언어: 엄격하고 사전 정의된 클래스를 뛰어넘을 수 있습니다. 자연어 접근 방식으로 업계와 사용자에 맞춘 시각적 쿼리의 '세부적인 부분'에 대한 솔루션을 유연하게 구축할 수 있습니다.
2: 간소화된 개발자 경험: 단일 API로 몇 분 만에 시작할 수 있습니다. 별도의 특수 분할 모델을 찾거나, 훈련하거나, 호스팅할 필요가 없습니다. 이러한 접근성은 정교한 비전 애플리케이션 개발의 진입 장벽을 낮춰 줍니다.
저희는 언어와 비전을 픽셀 수준으로 직접 연결하면 차세대 지능형 애플리케이션을 구현할 수 있을 것으로 생각합니다. 여러분이 어떤 애플리케이션을 개발할지 무척 기대되네요.
다음 대화형 데모를 통해 Google AI Studio에서 지금 바로 시작해 보세요.
Python 환경을 선호하는 경우 대화형 공간 이해 Colab으로 시작할 수도 있습니다.
Gemini API로 개발을 시작하려면 개발자 가이드를 참조하고 분할 시작하기에 대해 자세히 읽어보세요. 개발자 포럼에 참여하여 다른 개발자를 만나고, 이용 사례를 논의하고, Gemini API 팀의 도움을 받을 수도 있습니다.
최상의 결과를 위해 다음 모범 사례를 따르는 것을 권장합니다.
1: Gemini-2.5 Flash 모델을 사용하기
2: 사고 세트 비활성화하기(thinkingBudget=0)
3: 권장 프롬프트와 비슷하게 유지하고 출력 포맷으로 JSON 요청하기.
Give the segmentation masks for the objects.
Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d", the segmentation mask in key "mask", and the text label in the key "label".
Use descriptive labels.또한 Gemini 분할 담당 웨이청 궈(Weicheng Kuo), 리치 무노즈(Rich Munoz) 및 휘종 첸(Huizhong Chen), 인프라스트럭처 담당 쥔옌 쉬(Junyan Xu), 문서 및 코드 샘플 담당 귀욤 베르나데(Guillaume Vernade), 이번 출시로 대단원의 막을 내리는 Gemini 이미지 이해팀 전체에 감사의 말을 전합니다. 마지막으로 이미지 이해 팀 팀장 시 첸(Xi Chen) 및 페이 시야(Fei Xia)와 멀티모달 이해 팀 팀장 장바티스트 알레이락(Jean-Baptiste Alayrac) 연구원님께 감사드립니다.

Announcing the Data Commons Gemini CLI extension

최첨단 이미지 모델 Gemini 2.5 Flash Image 출시

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages

Building with Gemini 3 in Jules

Announcing User Simulation in ADK Evaluation

터미널 너머: Gemini CLI가 Zed로 오다