

AI が画像を視覚的に理解する方法は飛躍的に進化してきました。当初、AI は境界ボックスを使用してオブジェクトの「位置」を回答できました。次に、セグメンテーション モデルが登場し、オブジェクトの形状について正確に輪郭を描けるようになりました。最近では、「オープン語彙」モデルが登場し、事前に定義されたカテゴリのリストを必要とせずに、「青いスキーブーツ」や「木琴」などのあまり一般的でないラベルを使用してオブジェクトをセグメント化できるようになりました。
以前のモデルでは、ピクセルと名詞が一致していましたが、実際の課題である会話型画像セグメンテーション(文献での「表現セグメンテーションの参照」に密接に関連している)は、より深い理解、つまり複雑で具体的なフレーズの解析が必要です。単に「車」を識別するだけではなく、「最も遠くにある車」を識別できたらどうでしょう?
現在、Gemini の高度な視覚理解機能により、会話型画像セグメンテーションが一段と向上しています。Gemini は、ユーザーが「見て」ほしいものを「理解」できるようになりました。
この機能の魅力は、質問の種類の多様さにあります。シンプルな 1 語のラベルにとらわれず、より直感的かつ効果的な方法で視覚データを操作できます。以下の 5 つのカテゴリのクエリを考えてみましょう。
Gemini は、周囲のオブジェクトとの複雑な関係に基づいてオブジェクトを識別できるようになりました。
1: 関係理解: "傘を持っている人"
2: 順序: "左から 3 冊目の本"
3: 比較属性: "花束の中で最もしおれた花"
条件付きロジックによるクエリが必要になる場合があります。たとえば、"ベジタリアンの食べ物" などのクエリでフィルタできます。また、"座っていない人" のような否定を含むクエリも処理できます。

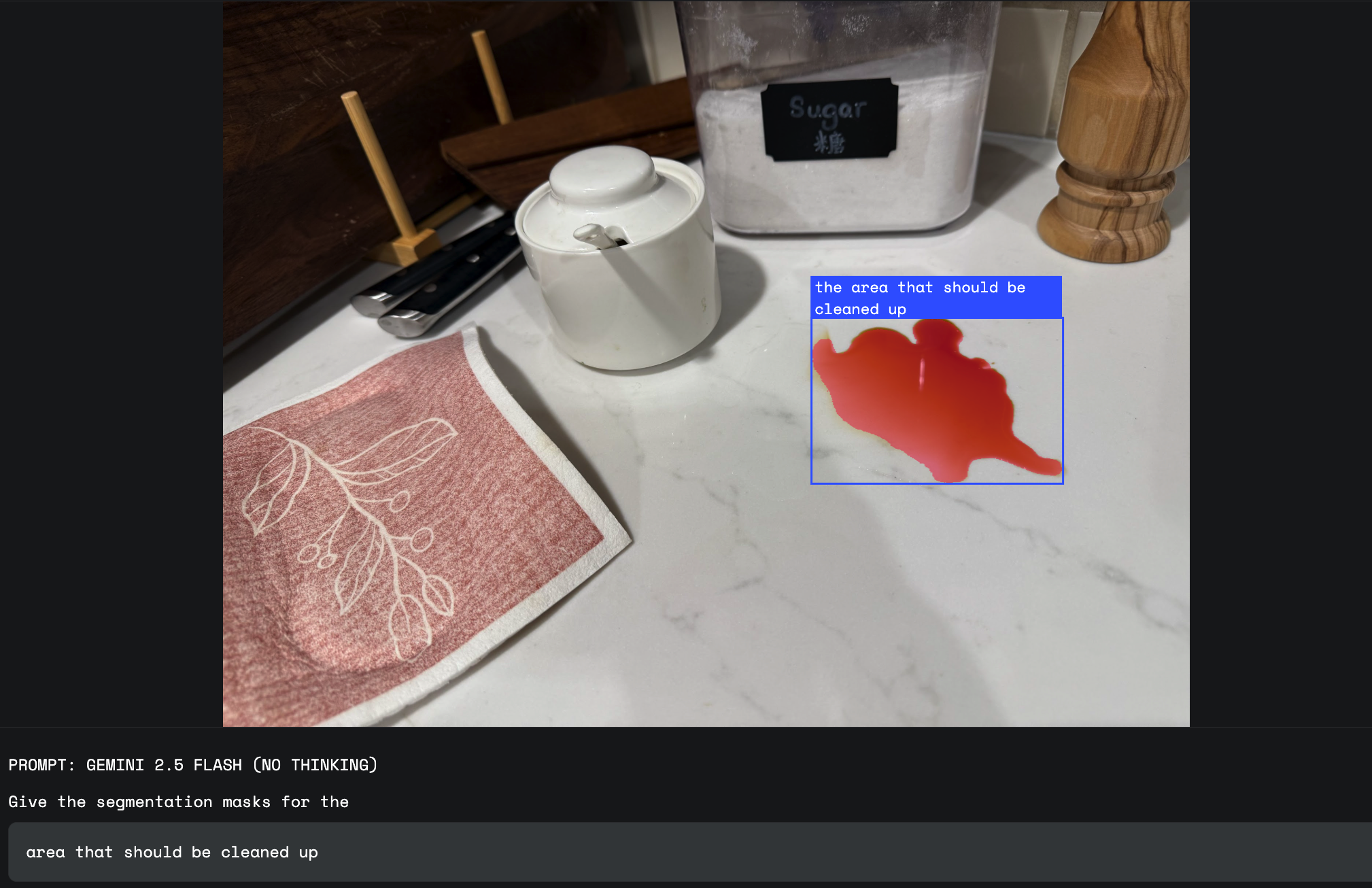
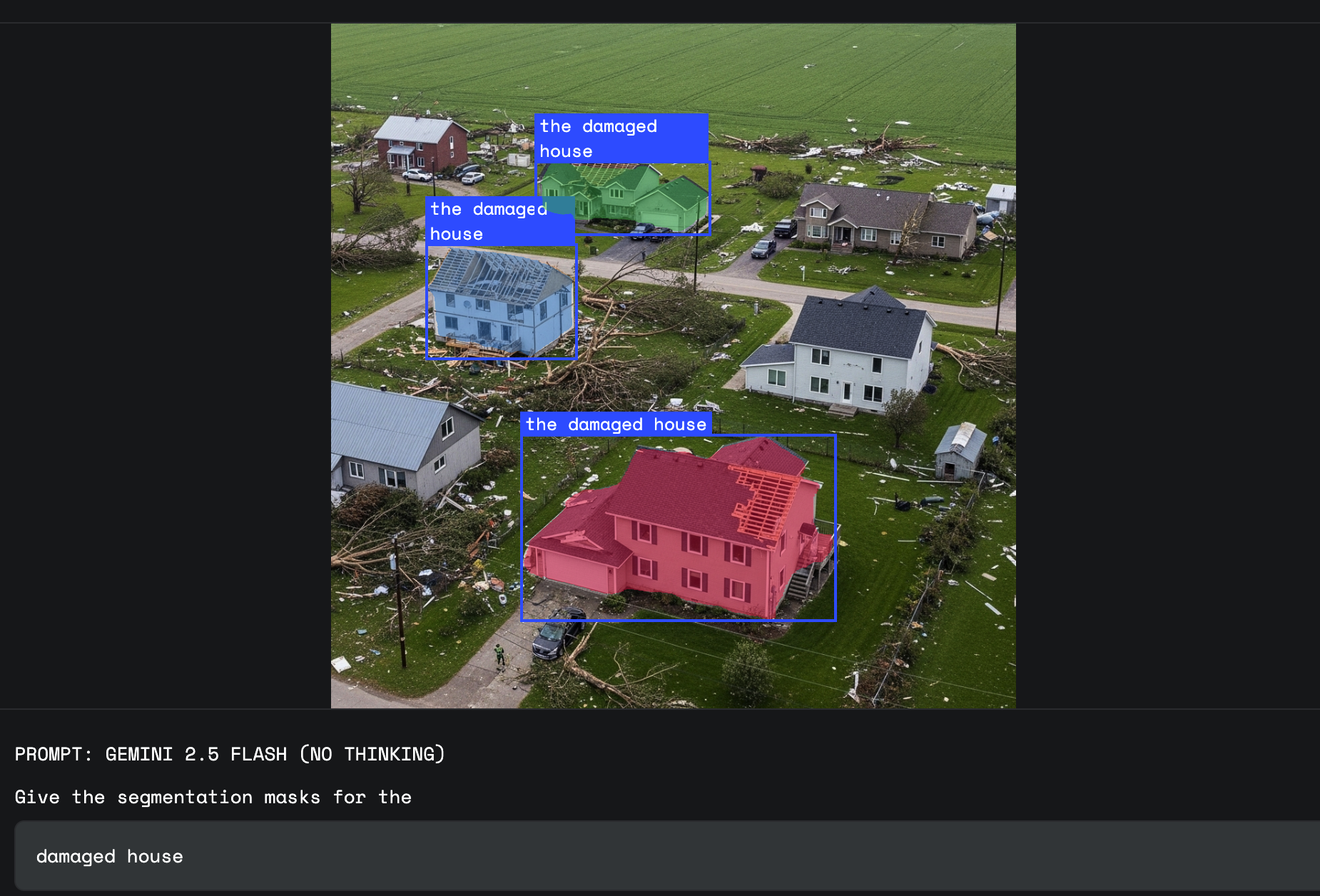
ここで、Gemini の世界知識が役立ちます。シンプルで固定された視覚定義がないものをセグメント化するように依頼できます。これには、「損傷」、「混乱」、「機会」などの概念が含まれます。
外観だけではオブジェクトの正確なカテゴリを区別できない場合、ユーザーは、画像内に表示されたテキストラベルを参照することがあります。この場合、モデルに OCR 機能が必要です。これは Gemini 2.5 の強みの一つです。
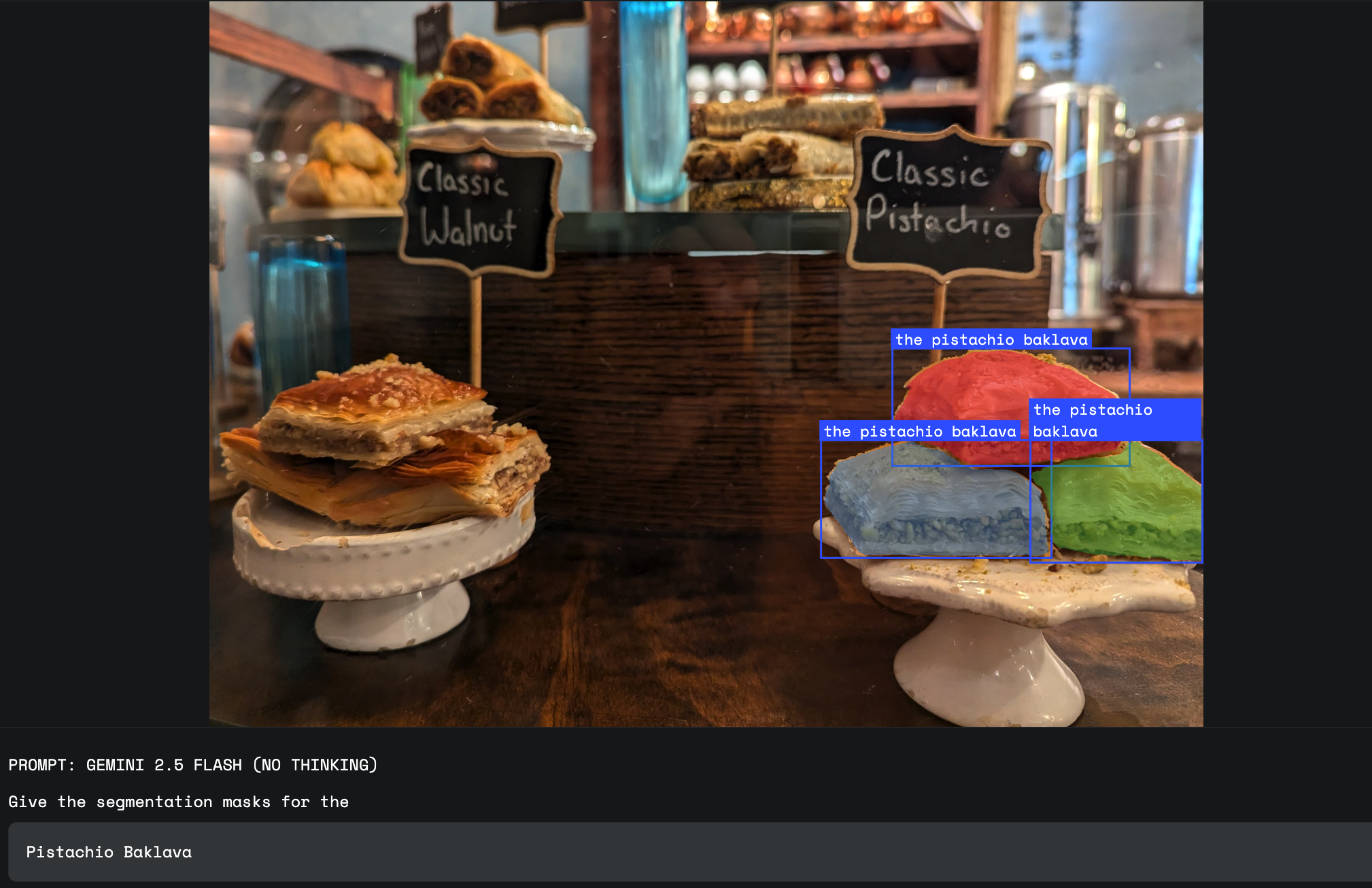
Gemini は単一の言語に限定されず、多くの異なる言語のラベルを扱うことができます。

それでは、これらのクエリタイプが新しいユースケースをどのように実現するかを見ていきましょう。
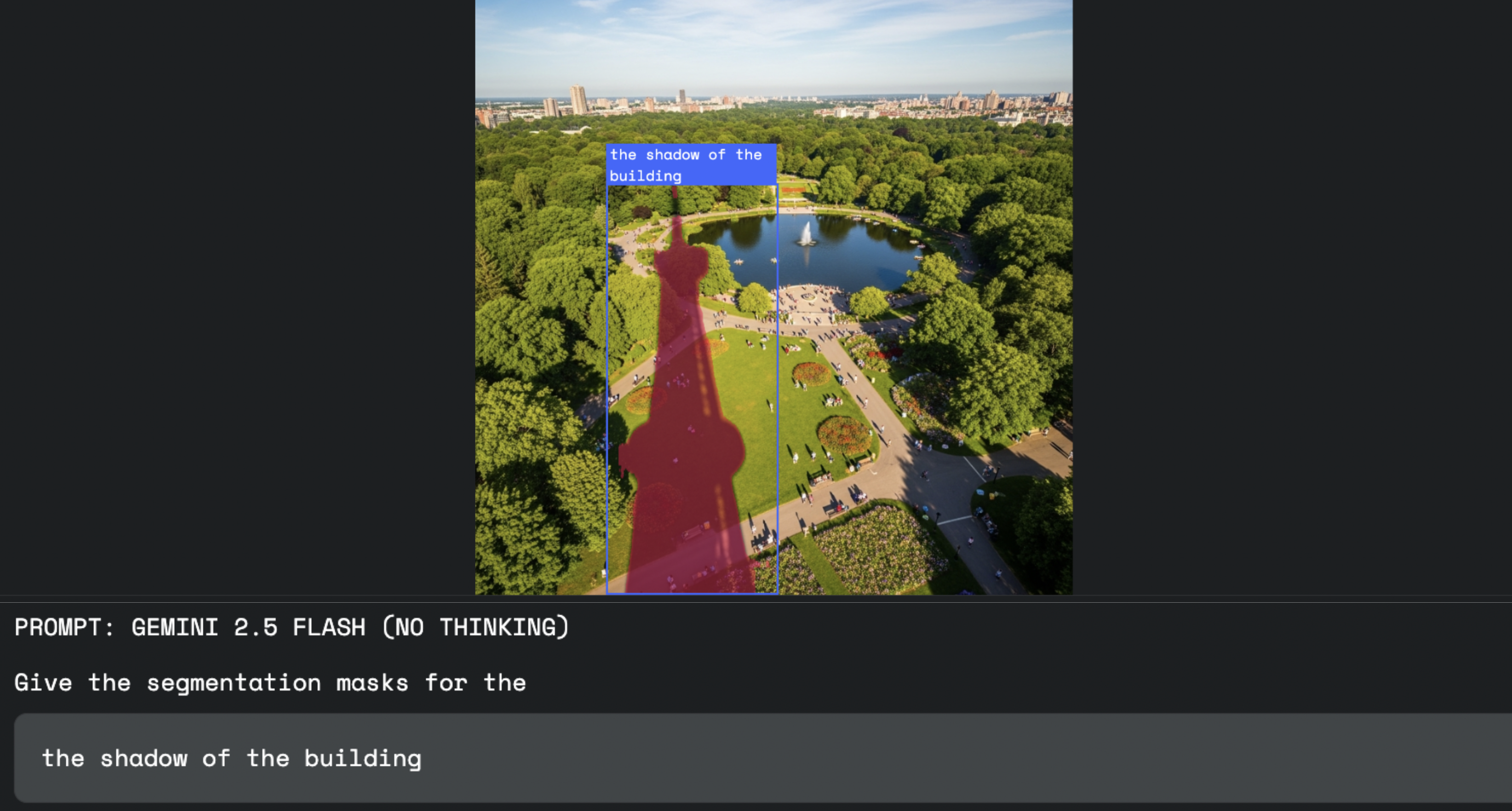
この機能は、クリエイティブなワークフローを変革します。複雑な選択ツールを使用する代わりに、デザイナーは言葉でソフトウェアに指示できるようになりました。これにより、"建物によってできる影"を選択するよう指示する場合と同様に、より流動的で直感的なプロセスが可能になります。
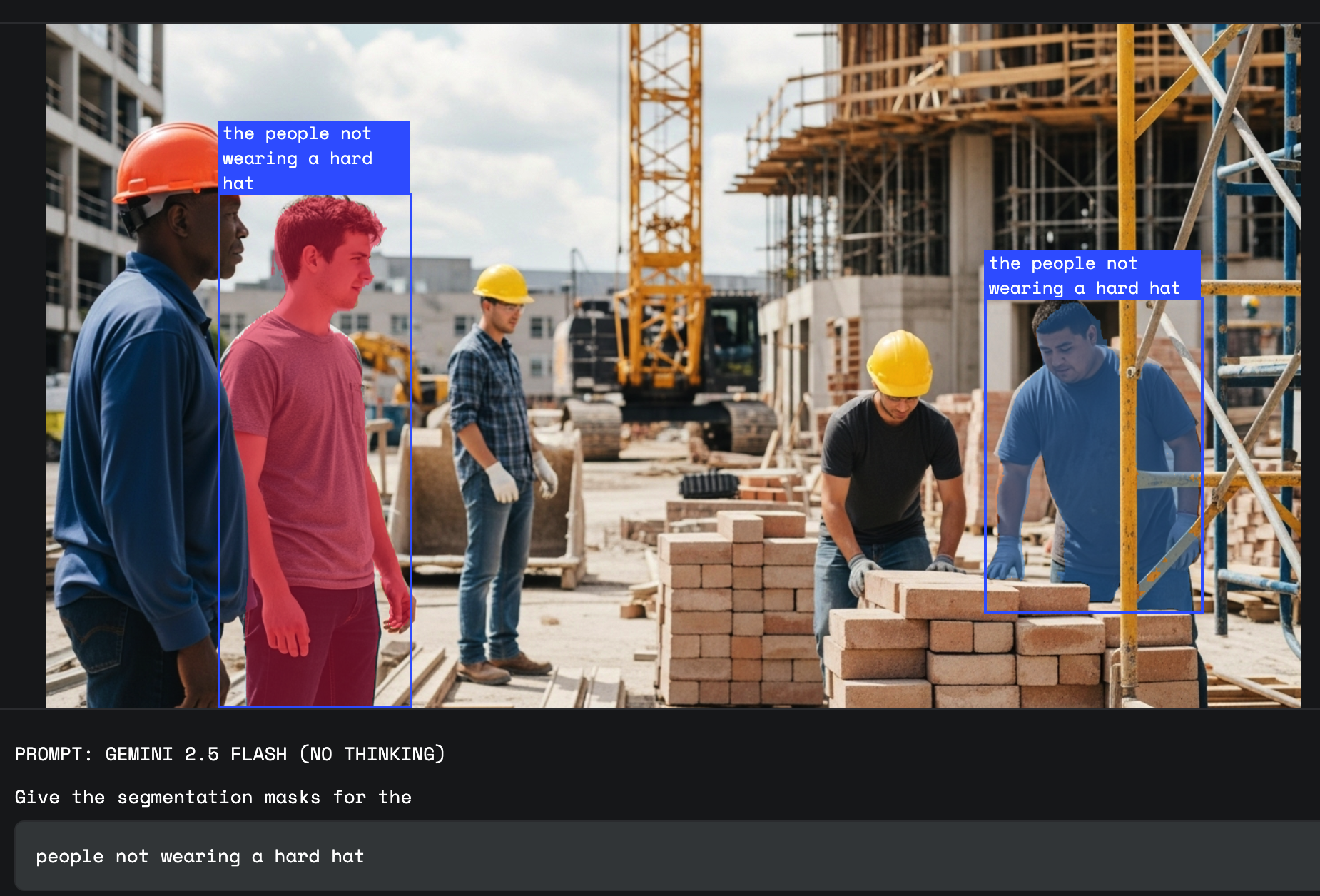
職場の安全のためには、オブジェクトだけでなく、状況も識別する必要があります。"ヘルメットを着用していない工場の従業員をハイライト表示して"のようなプロンプトに対し、Gemini は条件付き命令全体を単一のクエリとして理解し、コンプライアンス違反者のみを正確にマスクした最終結果を生成します。
「損害」は、多くの視覚的な形状を含む抽象的な概念です。保険査定員は、"天候による損害を受けた住宅を分類して"のようなプロンプトを使用できるようになりました。Gemini は、世界知識を使用して、その種類の損害に関連する特定のへこみや質感を識別し、単純な反射や錆と区別します。
1: 柔軟な言語: 自然言語アプローチを使用すると、厳格で事前定義されたクラスにとどまらず、業界やユーザーに固有の「ロングテール」の視覚クエリに対応したソリューションを柔軟に構築できます。
2: 簡素化されたデベロッパー エクスペリエンス: 単一の API で数分で開始できます。別個の特殊なセグメンテーション モデルを見つけ、トレーニングし、ホストする必要はありません。このアクセシビリティにより、高度なビジョン アプリケーションを構築するための障壁が低くなります。
言語と視覚をピクセルレベルで直接結び付けることで、新世代のインテリジェント アプリケーションが実現すると確信しています。どのようなものが構築されるか、今からとても楽しみです。
以下のインタラクティブなデモを使用して、Google AI Studio をすぐに利用できます。
Python 環境をご希望の場合は、インタラクティブな空間理解 Colab から始めてください。
Gemini API を使用した開発を始めるには、デベロッパー ガイドをご覧ください。セグメンテーションを始める方法については、こちらをご覧ください。また、デベロッパー フォーラムに参加して、他のビルダーと会ったり、ユースケースについて話し合ったり、Gemini API チームからサポートを受けたりすることもできます。
最良の結果を得るには、次のベスト プラクティスに沿って進めることをおすすめします。
1: gemini-2.5-flash モデルを使う
2: 思考セットを無効にする(thinkingBudget = 0)
3: 推奨されるプロンプトに近いプロンプトを使用し、JSON を出力形式としてリクエストする
Give the segmentation masks for the objects.
Output a JSON list of segmentation masks where each entry contains the 2D bounding box in the key "box_2d", the segmentation mask in key "mask", and the text label in the key "label".
Use descriptive labels.評価面について協力してくれた 今回のリリースに携わり、Gemini のセグメンテーションを担当した Weicheng Kuo、 Rich Munoz、 Huizhong Chen、 インフラストラクチャを担当した Junyan Xu、 ドキュメントとコードサンプルを担当した Guillaume Vernade、そして Gemini 画像理解チーム全体に感謝します。最後に、画像理解チームのリーダーである Xi Chen と Fei Xia、マルチモーダル理解チームのリーダーである Jean-Baptiste Alayrac に感謝します。

Announcing User Simulation in ADK Evaluation

ターミナルを超えて: Gemini CLI が Zed に登場

Building with Gemini 3 in Jules

最先端の画像処理モデル Gemini 2.5 Flash Image のご紹介

Announcing the Data Commons Gemini CLI extension

Announcing the Agent Development Kit for Go: Build Powerful AI Agents with Your Favorite Languages