

Today, we're making our state-of-the-art robotics embodied reasoning model, Gemini Robotics-ER 1.5, available to all developers. This is the first Gemini Robotics model to be made broadly available. It acts as a high-level reasoning model for a robot.
This model specializes in capabilities critical for robotics, including visual and spatial understanding, task planning, and progress estimation. It can also natively call tools, like Google Search to find information, and can call a vision-language-action model (VLA) or any other third-party user-defined functions to execute the task.
You can get started building with Gemini Robotics-ER 1.5 today in preview via Google AI Studio and the Gemini API.
This model is designed for tasks that are notoriously challenging for robots. Imagine asking a robot, “Can you sort these objects into the correct compost, recycling and trash bins?" To complete this task, the robot needs to look up the local recycling guidelines on the internet, understand the objects in front of it and figure out how to sort them based on local rules, then do all the steps to complete putting them away. Most daily tasks, like this one, take contextual information and multiple steps to complete.
Gemini Robotics-ER 1.5 is the first thinking model optimized for this kind of embodied reasoning. It achieves state-of-the-art performance on both academic and internal benchmarks, inspired by real-world use cases from our trusted tester program.
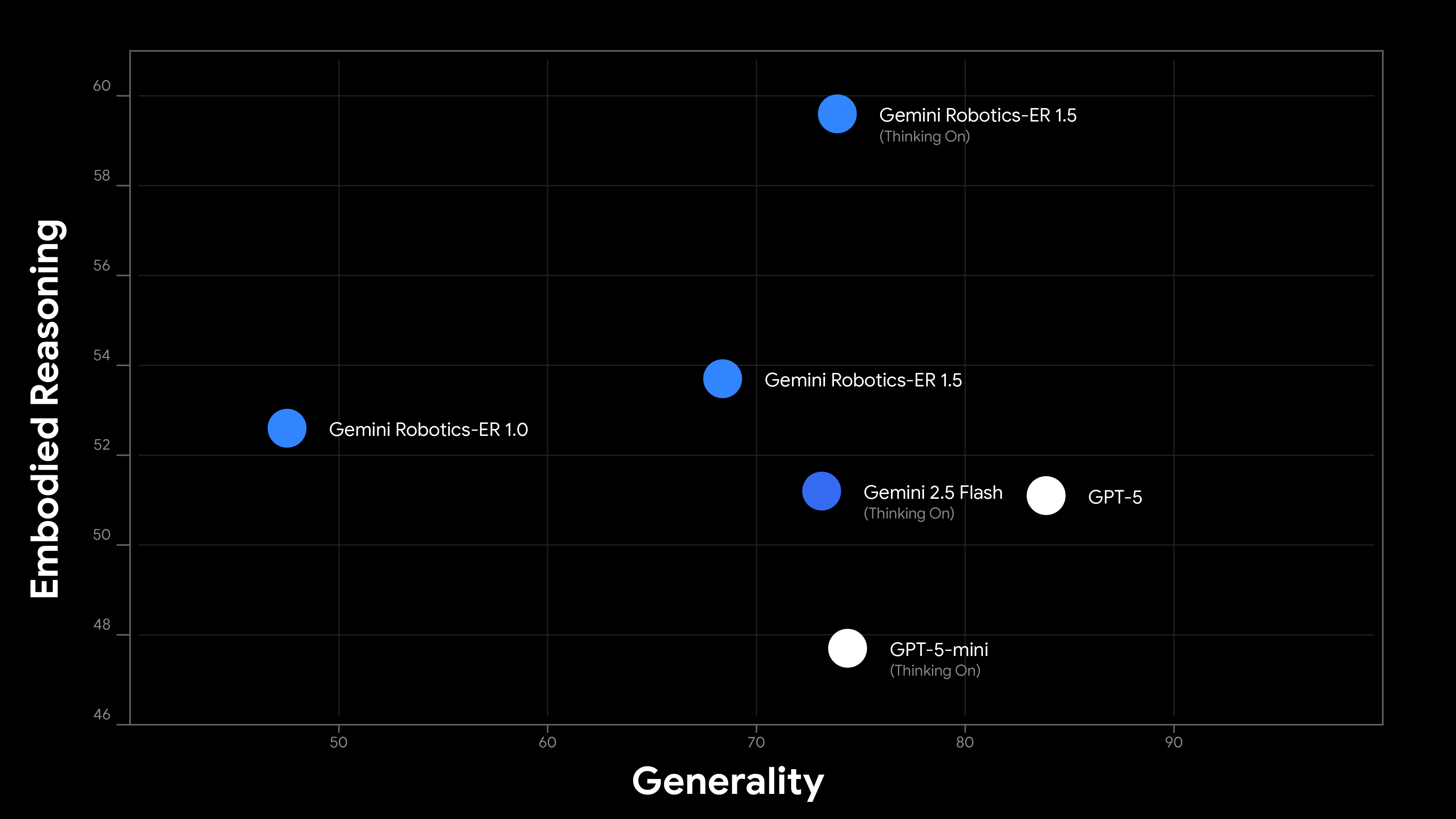
Gemini Robotics-ER 1.5 is purpose-tuned for robotics applications and introduces several new capabilities:
You can think of Gemini Robotics-ER 1.5 as the high level brain for your robot. It can understand complex natural language commands, reason through long-horizon tasks, and orchestrate sophisticated behaviors. This means it excels not just at perception, understanding what is in a scene and what to do about it.
Gemini Robotics-ER 1.5 can break down a complex request like "clean up the table" into a plan and call the right tools for the job, whether that's a robot's hardware API, a specialized grasping model, or a vision-language-action model (VLA) for motor control.
In order for robots to be able to interact with the physical world around them, they need to be able to perceive and understand the environment where they exist. Gemini Robotics-ER 1.5 is fine-tuned for producing high quality spatial results, allowing the model to generate precise 2D points for objects. Let’s take a look at a few examples using the Gemini GenAI SDK for Python to help you get started using this model in your own applications.
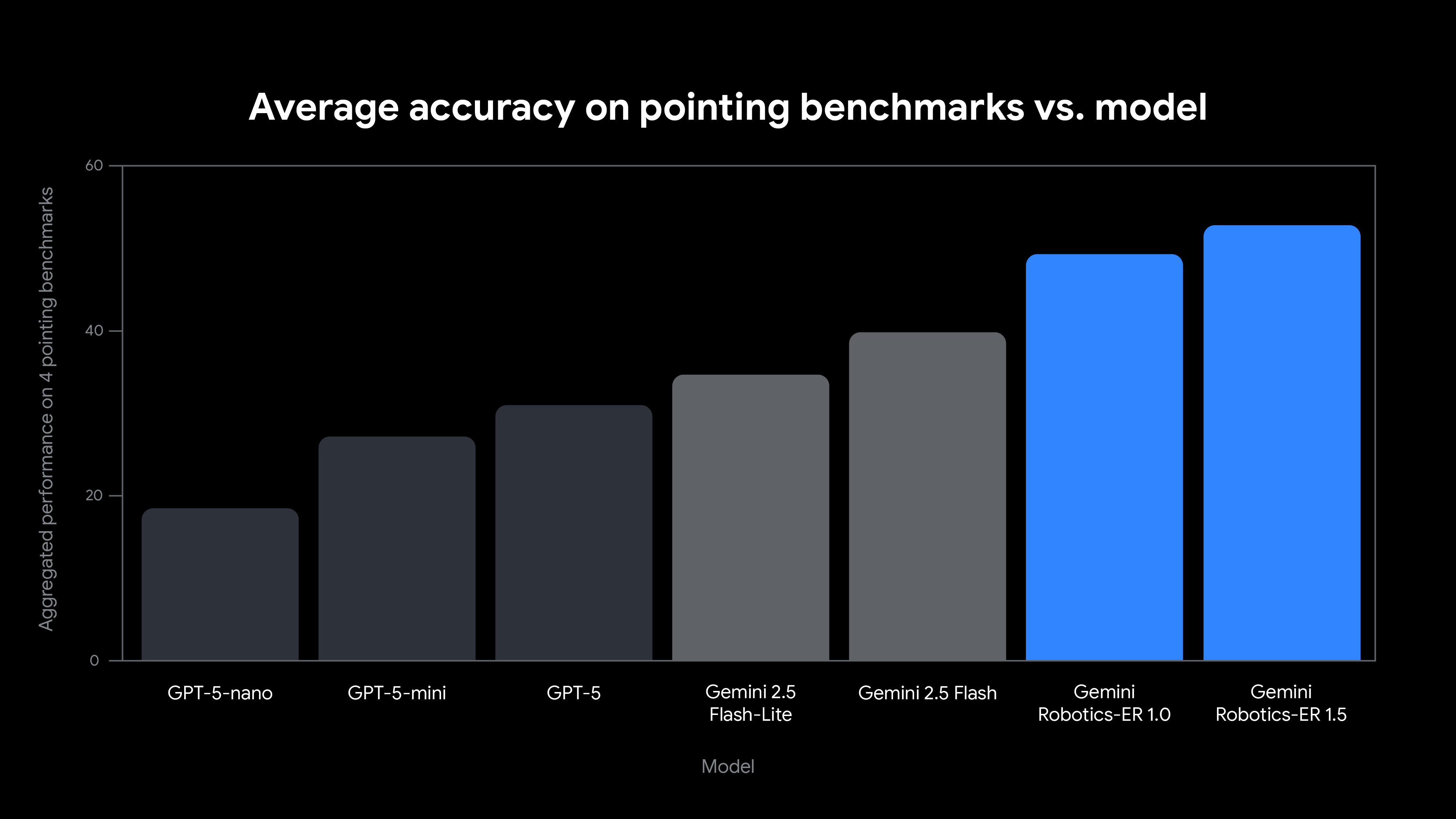
Given an image of a kitchen scene, Gemini Robotics-ER 1.5 can provide the location of every object (or part of an object). This information can then be combined with the robot's 3D sensors to determine the object's precise location in space, enabling your planning library to generate an accurate motion plan.

Prompt:
Point to the following items in the image: dish soap, dish rack, faucet, rice cooker, unicorn. The points are in [y, x] format normalized to 0-1000. Only include objects that are actually present in the image."Note how we’ve asked the model to only include requested items that appear within the image - this prevents hallucinations, such as including a point for the requested non-existent unicorn, and keeps the model grounded in the reality of what it can view. We can extend this technique to outputting states of objects in a video stream, only highlighting objects of a specific state, such as a container being opened or closed, when it’s visible within the frame. Below is a video of promoting the model to point to “green marker, brown tray, green notebook, laptop (open), laptop (closed), glasses case (open), glasses case (closed)”, which is a query that combines spatial understanding and state estimation.
While locating objects is essential, true spatial-temporal reasoning involves understanding the relationship between objects and actions as they unfold over time. Gemini Robotics-ER 1.5 excels at this by processing video to understand cause and effect in the physical world. For example, in the following video, a pair of robotic arms moves a green marker into a wooden tray, then moves the blue and red pens into the cylindrical container. When we ask the model to review the sequence and tell us which tasks were done in what order, as well as what tasks happened between two timestamps, we receive the correct answer. This demonstrates an ability to reason about what happened in a scene, not just what is in it.
Prompt:
Describe in detail each step of finishing the task. Breaking it down by timestamp, output in json format with keys "start_timestamp", "end_timestamp" and "description".Response:
[
{
"start_timestamp": "00:02",
"end_timestamp": "00:13",
"description": "The left robotic arm picks up the green marker from the table and places it into the wooden tray."
},
{
"start_timestamp": "00:15",
"end_timestamp": "00:22",
"description": "The left robotic arm picks up the blue pen from the table and places it into the black mesh pen cup."
},
{
"start_timestamp": "00:23",
"end_timestamp": "00:28",
"description": "The right robotic arm picks up the red pen from the table and places it into the black mesh pen cup, completing the task of organizing the writing utensils."
}
]>zoom into second 15 to 22 and provide a per-second breakdown of what is happening in the same format
[
{
"start_timestamp": "00:15",
"end_timestamp": "00:16",
"description": "The left robotic arm begins moving towards the blue pen located on the table to the left of the pen cup."
},
... (removed for brevity, please take a look at the video below)
{
"start_timestamp": "00:21",
"end_timestamp": "00:22",
"description": "The arm lowers the pen into the cup and releases it, placing it upright inside the container."
}
]The output is temporally accurate, and overlaying it on the original video shows the model has a precise understanding of the robot’s motion.
When thinking is enabled, the model can reason about complex pointing and bounding box queries. Here is a step-by-step demonstration of using it in a coffee making example. It demonstrates understanding of the “how” and “where” needed for a human or robot to finish a task.

Prompt:
Identify where I should put my mug to make a cup of coffee. Return a list of JSON objects in the format: `[{"box_2d": [y_min, x_min, y_max, x_min], "label": <label>}]`, where the coordinates are normalized between 0-1000.Response:

Where should I put the coffee pod?Response:

Now, I need to close the coffee maker. Plot a trajectory of 8 points that indicates how the handle of the lid should move to close it. Start from the handle. Points are [Y,X] in normalized coordinates [0 - 1000]. Please output all points, including the trajectory points in the format. [{"point": [Y, X], "label": }, {"point": [Y, X], "label": }, ...].Response:

I finished my coffee. Where should I put my mug now to clean up? Return a list of JSON objects in the format: [{"point": [y, x], "label": <label>}], where the coordinates are normalized between 0-1000.
Here is another example of combining planning and spatial grounding to generate a “spatially grounded” plan. It can be elicited with a simple prompt “Explain how to sort the trash into the bins. Point to each object that you refer to. Each point should be in the format: [{"point": [y, x], "label": }], where the coordinates are normalized between 0-1000.” The response contains interleaved text and points and it can be rendered out to create this animation.
This chart shows a series of examples of changing the thinking budget when using the Gemini Robotics-ER 1.5 model and how that affects latency and performance. Model performance increases with an increasing thinking token budget. For simple spatial understanding tasks like object detection, performance is high with a very short thinking budget, while more complex reasoning benefits from a larger budget. This allows developers to balance the need for low-latency responses with high-accuracy results for more challenging tasks.
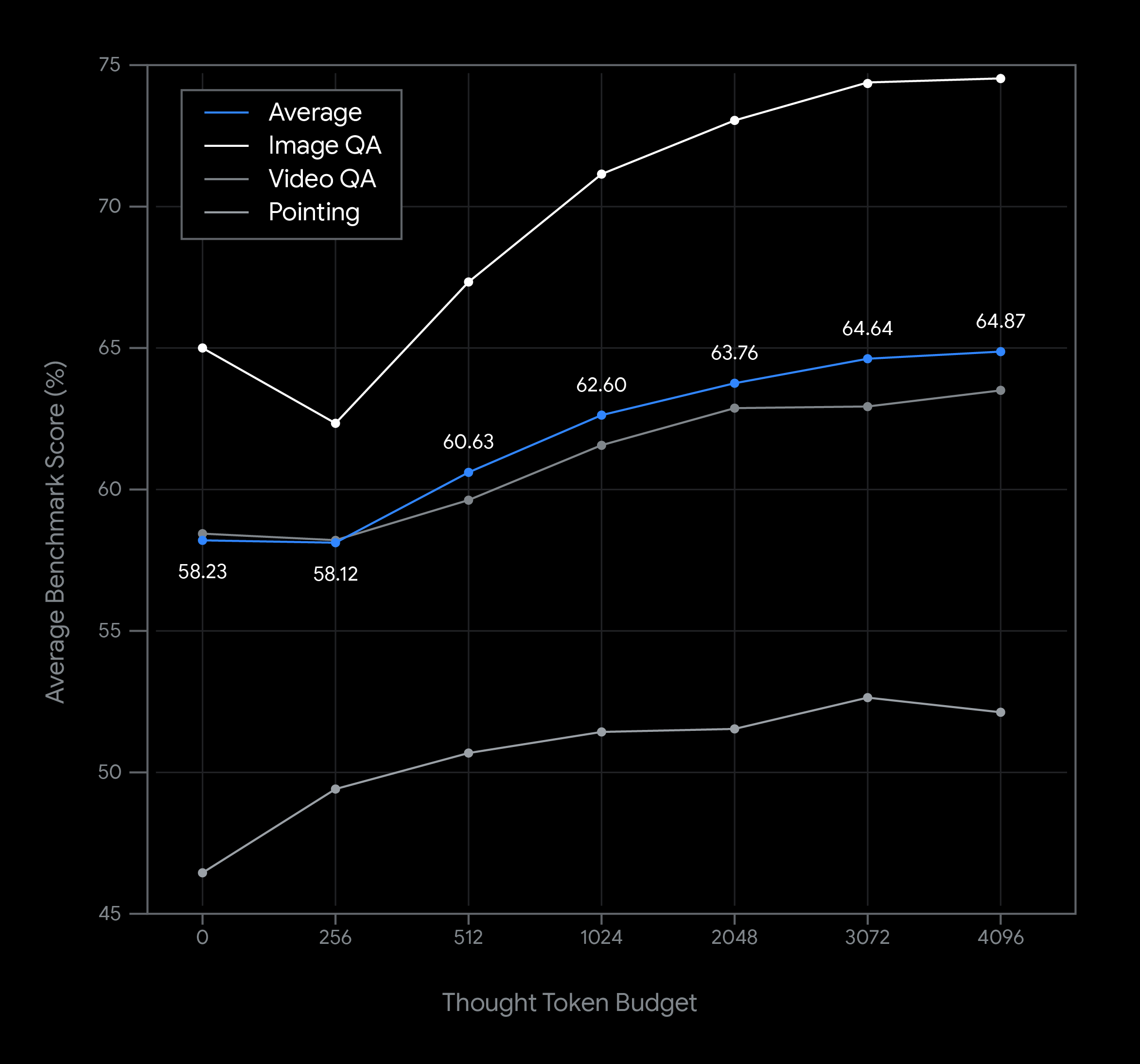
While thinking is enabled by default with the Gemini Robotics-ER 1.5 model, you can set a thinking budget, or even disable thinking, by including the thinking_config option with your request. You can find more information about Gemini thinking budgets here.
We are committed to building a responsible foundation for your robotics applications. Gemini Robotics-ER 1.5 has made significant improvements in safety, with enhanced filters for both:
However, these model-level safeguards are not a substitute for the rigorous safety engineering required for physical systems. We advocate for a "Swiss cheese approach" to safety, where multiple layers of protection work together. Developers are responsible for implementing standard robotics safety best practices, including emergency stops, collision avoidance, and thorough risk assessments.
Gemini Robotics-ER 1.5 is available in preview today. It provides the perception and planning capabilities you need to build a reasoning engine for your robot.
This model is the foundational reasoning component of our broader Gemini Robotics system. To understand the science behind our vision for the future of robotics, including end-to-end action models (VLA) and cross-embodiment learning, read the research blog and full technical report.
Introducing Agent Development Kit for TypeScript: Build AI Agents with the Power of a Code-First Approach

Tailor Gemini CLI to your workflow with hooks
Don't Trust, Verify: Building End-to-End Confidential Applications on Google Cloud
Beyond the Chatbot: A Blueprint for Trustable AI