

저희는 오늘 최첨단 로봇 구현 추론 모델인 Gemini Robotics-ER 1.5를 모든 개발자가 사용할 수 있도록 제공합니다. 이것은 널리 이용 가능한 첫 번째 Gemini Robotics 모델로, 로봇용 고차원 추론 모델로서 역할을 합니다.
이 모델은 시각적 이해, 공간적 이해, 작업 계획, 진행률 추정 등 로봇 공학에 필수적인 기능에 특화되어 있습니다. 또한 Google 검색과 같은 도구를 기본적으로 호출하여 정보를 찾을 수 있으며, VLA(vision-language-action: 시각 언어 행동) 모델이나 기타 타사 사용자 정의 함수를 호출해 작업을 실행할 수 있습니다.
오늘 바로 Google AI Studio와 Gemini API를 통해 미리보기에서 Gemini Robotics-ER 1.5로 개발을 시작할 수 있습니다.
이 모델은 로봇이 수행하기에 어렵기로 잘 알려진 작업을 위해 설계되었습니다. 로봇에게 "이 물건들을 음식물 쓰레기통, 재활용품통, 일반 쓰레기통으로 올바르게 분류해 줄 수 있어?"라고 물어본다고 상상해 보세요. 이 작업을 완수하려면 로봇은 인터넷에서 해당 지역의 재활용 지침을 검색하고, 앞에 있는 물건이 무엇인지 이해하고, 지역의 규정에 따라 분류하는 방법을 파악한 다음, 모든 단계를 수행해 물건을 치우는 작업을 완료해야 합니다. 이와 같은 대부분의 일상적인 작업을 완료하기 위해서는 상황에 맞는 정보가 필요하고 여러 단계를 거쳐야 합니다.
Gemini Robotics-ER 1.5는 이러한 종류의 구현된 추론에 최적화된 최초의 사고 모델입니다. 신뢰할 수 있는 테스터 프로그램의 실제 사용 사례에서 영감을 받아 학술 및 내부 벤치마크 모두에서 최첨단 성능을 달성했습니다.
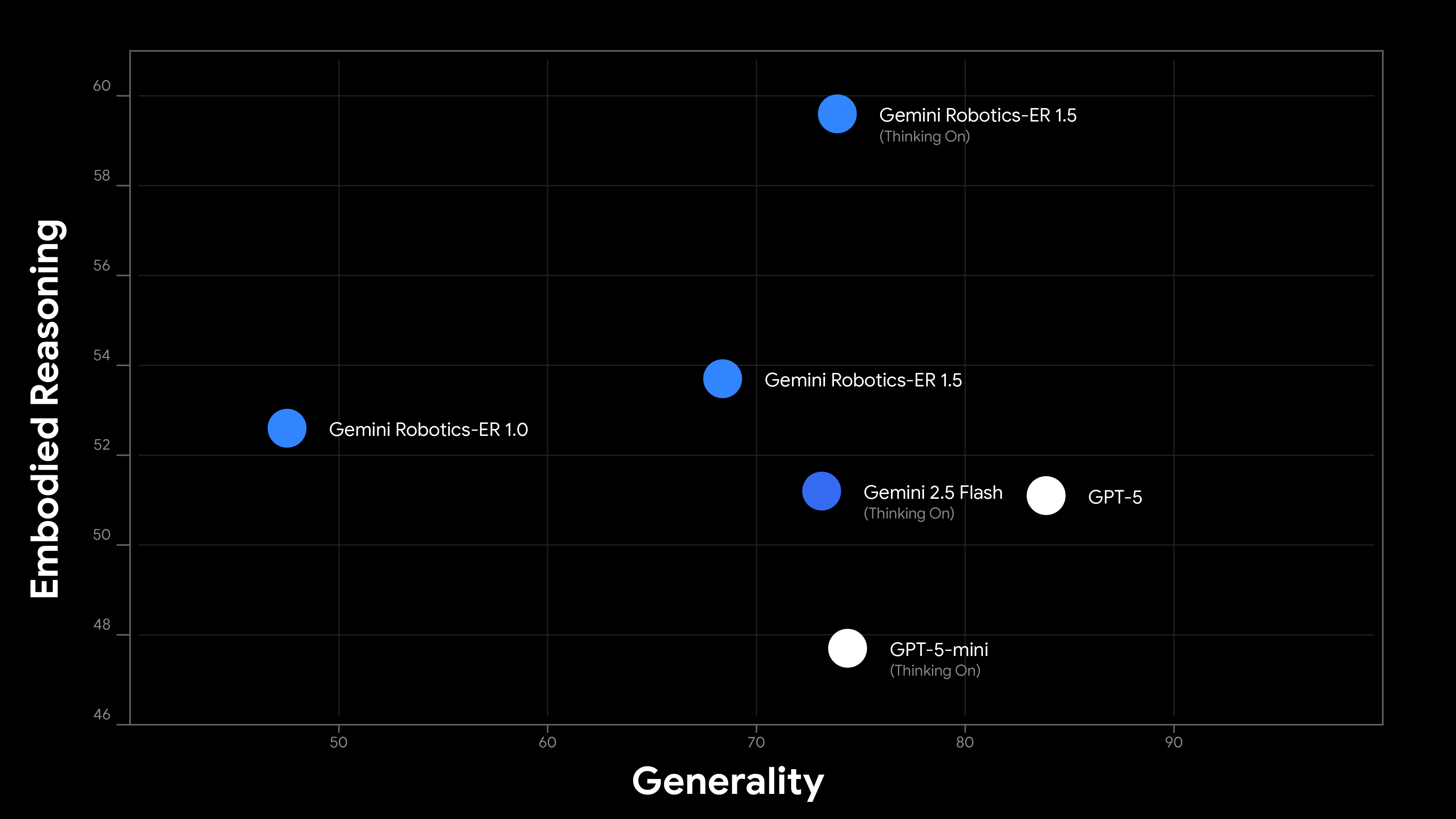
Gemini Robotics-ER 1.5는 로보틱스 애플리케이션에 맞춰 특별히 조정되었으며 다음과 같은 여러 새로운 기능을 도입했습니다.
Gemini Robotics-ER 1.5를 로봇의 고차원적 두뇌로 생각할 수 있습니다. 이 모델은 복잡한 자연어 명령을 이해하고, 장기적인 작업을 추론하며, 정교한 행동을 조율할 수 있습니다. 이는 단순한 인식을 넘어 장면에 무엇이 있는지, 그에 따라 무엇을 해야 하는지까지 파악하는 능력도 뛰어남을 의미합니다.
Gemini Robotics-ER 1.5는 "테이블을 정리하세요"와 같은 복잡한 요청을 분석해 세부 계획을 세우고, 로봇의 하드웨어 API, 특화된 파지 모델 또는 모터 제어를 위한 VLA(vision-language-action) 모델 등 관련 작업에 적합한 도구를 호출할 수 있습니다.
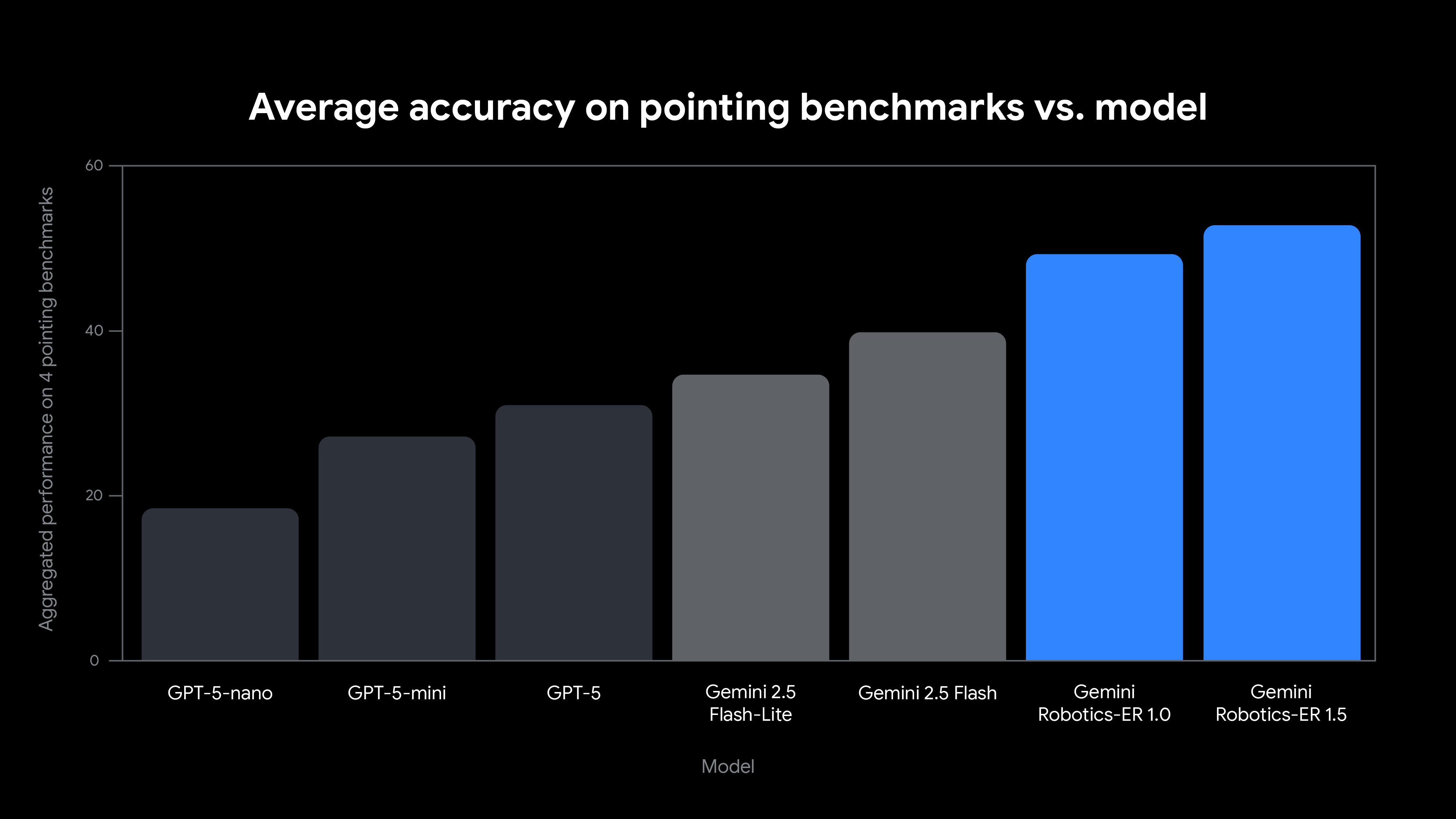
로봇이 주변의 물리적 세계와 상호작용하려면 로봇 자신이 존재하는 환경을 인식하고 이해할 수 있어야 합니다. Gemini Robotics-ER 1.5는 고품질의 공간 결과를 생성하기 위해 미세 조정되어 모델이 물체에 대한 정밀한 2D 점을 생성할 수 있도록 합니다. 자체 애플리케이션에서 이 모델을 사용하여 시작하는 데 도움이 되도록 Gemini GenAI SDK for Python을 사용하는 몇 가지 예를 살펴보겠습니다.
주방 장면의 이미지를 받으면 Gemini Robotics-ER 1.5는 모든 물체(또는 물체의 일부)의 위치를 제공할 수 있습니다. 그런 다음 이 정보를 로봇의 3D 센서와 결합하여 공간에서 물체의 정확한 위치를 결정할 수 있고, 이를 통해 계획 라이브러리가 정확한 모션 계획을 생성하도록 할 수 있습니다.

프롬프트:
이미지에서 주방용 세제, 접시 정리대, 수도꼭지, 밥솥, 유니콘을 찾아 점으로 표시해 보세요. 점의 좌표는 [y, x] 형식이고 0~1000 범위로 정규화되어 있습니다. 이미지에 실제로 존재하는 물체만 포함하세요."표시하라고 요청된 물건 중 이미지에 실제로 있는 물건만 포함하도록 모델에 요청한 방식에 주목하세요. 이런 식으로 요청하면 요청하긴 했지만 실제로는 존재하지 않는 유니콘에 대한 점을 포함하는 것 같은 환각을 방지하고 계속해서 모델이 실제로 볼 수 있는 것에 대해서만 기반하도록 할 수 있습니다. 이 기법을 동영상 스트림에서 객체의 상태를 출력하는 데 확장할 수 있으며, 프레임 내에 나타나는 특정 상태의 객체만 강조해서 표시할 수 있습니다. 예를 들면, 열려있거나 닫혀있는 용기의 상태만 표시하는 식입니다. 아래는 '녹색 마커, 갈색 쟁반, 녹색 공책, 노트북(열림), 노트북(닫힘), 안경집(열림), 안경집(닫힘)'을 가리키도록 모델에게 요청한 동영상으로, 공간 이해와 상태 추정을 결합한 쿼리입니다.
물체의 위치 파악은 필수적이지만, 진정한 시공간적 추론에는 시간이 지남에 따라 전개되는 물체와 동작 사이의 관계에 대한 이해가 포함됩니다. Gemini Robotics-ER 1.5는 동영상을 처리하여 물리적 세계에서의 인과 관계를 이해하므로 이 부분에서 탁월한 능력을 발휘합니다. 예를 들어, 다음 동영상에서는 한 쌍의 로봇 팔이 녹색 마커를 나무 쟁반으로 옮긴 다음 파란색 펜과 빨간색 펜을 원통형 용기 안으로 옮깁니다. 모델에 시퀀스를 검토하고 어떤 작업이 어떤 순서로 수행되었는지, 두 타임스탬프 사이에 어떤 작업이 수행되었는지 알려달라고 요청하면 올바른 답을 얻을 수 있습니다. 이는 장면에 보이는 대상뿐 아니라 장면에서 일어난 일에 대해 추론하는 능력을 보여줍니다.
프롬프트:
작업을 완료하는 각 단계를 자세히 설명하세요. 타임스탬프별로 세분화하여 'start_timestamp', 'end_timestamp' 및 'description' 키를 사용해 json 형식으로 출력하세요.응답:
[
{
"start_timestamp": "00:02",
"end_timestamp": "00:13",
"description": "The left robotic arm picks up the green marker from the table and places it into the wooden tray."
},
{
"start_timestamp": "00:15",
"end_timestamp": "00:22",
"description": "The left robotic arm picks up the blue pen from the table and places it into the black mesh pen cup."
},
{
"start_timestamp": "00:23",
"end_timestamp": "00:28",
"description": "The right robotic arm picks up the red pen from the table and places it into the black mesh pen cup, completing the task of organizing the writing utensils."
}
]>15초에서 22초 구간을 확대해서 초 단위로 무슨 일이 일어나는지 동일한 형식으로 세분화하여 제공해 주세요.
[
{
"start_timestamp": "00:15",
"end_timestamp": "00:16",
"description": "The left robotic arm begins moving towards the blue pen located on the table to the left of the pen cup."
},
... (removed for brevity, please take a look at the video below)
{
"start_timestamp": "00:21",
"end_timestamp": "00:22",
"description": "The arm lowers the pen into the cup and releases it, placing it upright inside the container."
}
]출력은 시간적으로 정확하며, 원본 동영상에 이 출력을 오버레이하면 모델이 로봇의 모션을 정확하게 이해하고 있음을 알 수 있습니다.
사고가 활성화되면 모델은 복잡한 포인팅 및 경계 상자 쿼리에 대해 추론할 수 있습니다. 다음은 커피 만들기 예시에서 이 모델을 사용하는 단계별 데모입니다. 인간이나 로봇이 작업을 완료하는 데 필요한 '방법'과 '위치'에 대한 이해를 보여줍니다.

프롬프트:
커피 한 잔을 만들기 위해 머그컵을 어디에 놓아야 할지 위치를 식별해 주세요. 좌표는 0~1000 범위로 정규화되며, `[{"box_2d": [y_min, x_min, y_max, x_min], "label": <label>}]` 형식으로 JSON 객체 목록을 반환하세요.응답:

커피 캡슐은 어디에 두어야 할까요?응답:

이제 커피 메이커를 닫아야 합니다. 커피 메이커를 닫으려면 뚜껑의 손잡이를 어떻게 움직여야 하는지 보여주는 궤적을 8개의 점으로 그려 주세요. 손잡이부터 시작하세요. 점의 좌표는 [Y, X] 형식이고, [0 - 1000] 범위로 정규화되어 있습니다. 궤적 상의 점을 포함해 모든 점을 [{"point": [Y, X], "label": }, {"point": [Y, X], "label": }, ...] 형식으로 출력해 주세요.응답:

커피를 다 마셨습니다. 이제 깔끔하게 정리하려면 머그컵을 어디에 놓아야 할까요? 좌표가 0~1000 범위에서 정규화되는 [{"point": [y, x], "label": <label>}] 형식으로 JSON 객체 목록을 반환하세요.
다음은 계획 수립과 공간 그라운딩을 결합하여 '공간적으로 그라운딩된' 계획을 생성하는 또 다른 예시를 살펴보겠습니다. 다음의 간단한 프롬프트로 이런 계획을 유도할 수 있습니다. "쓰레기를 쓰레기통에 분류하는 방법을 설명해 주세요. 언급하는 각각의 물체를 점으로 표시하세요. 각 점은 0~1000 범위에서 정규화되는 [{"point": [y, x], "label": }] 형식이어야 합니다." 응답에는 인터리빙된 텍스트와 점이 포함되며 이를 렌더링하여 다음 애니메이션을 생성할 수 있습니다.
다음 차트는 Gemini Robotics-ER 1.5 모델 사용 시 사고 예산을 변경했을 때 그것이 지연 시간과 성능에 미치는 영향을 보여주는 일련의 예시입니다. 모델 성능은 사고 토큰 예산이 증가함에 따라 향상됩니다. 물체 탐지와 같은 간단한 공간 이해 작업의 경우 짧은 사고 예산으로도 높은 성능을 발휘하지만, 더 복잡한 추론은 사고 예산이 더 많을수록 성능이 더 좋습니다. 이를 통해 개발자는 빠른 응답 속도와 높은 정확도 사이에서 균형을 찾으면서 보다 어려운 작업에도 잘 대응할 수 있습니다.
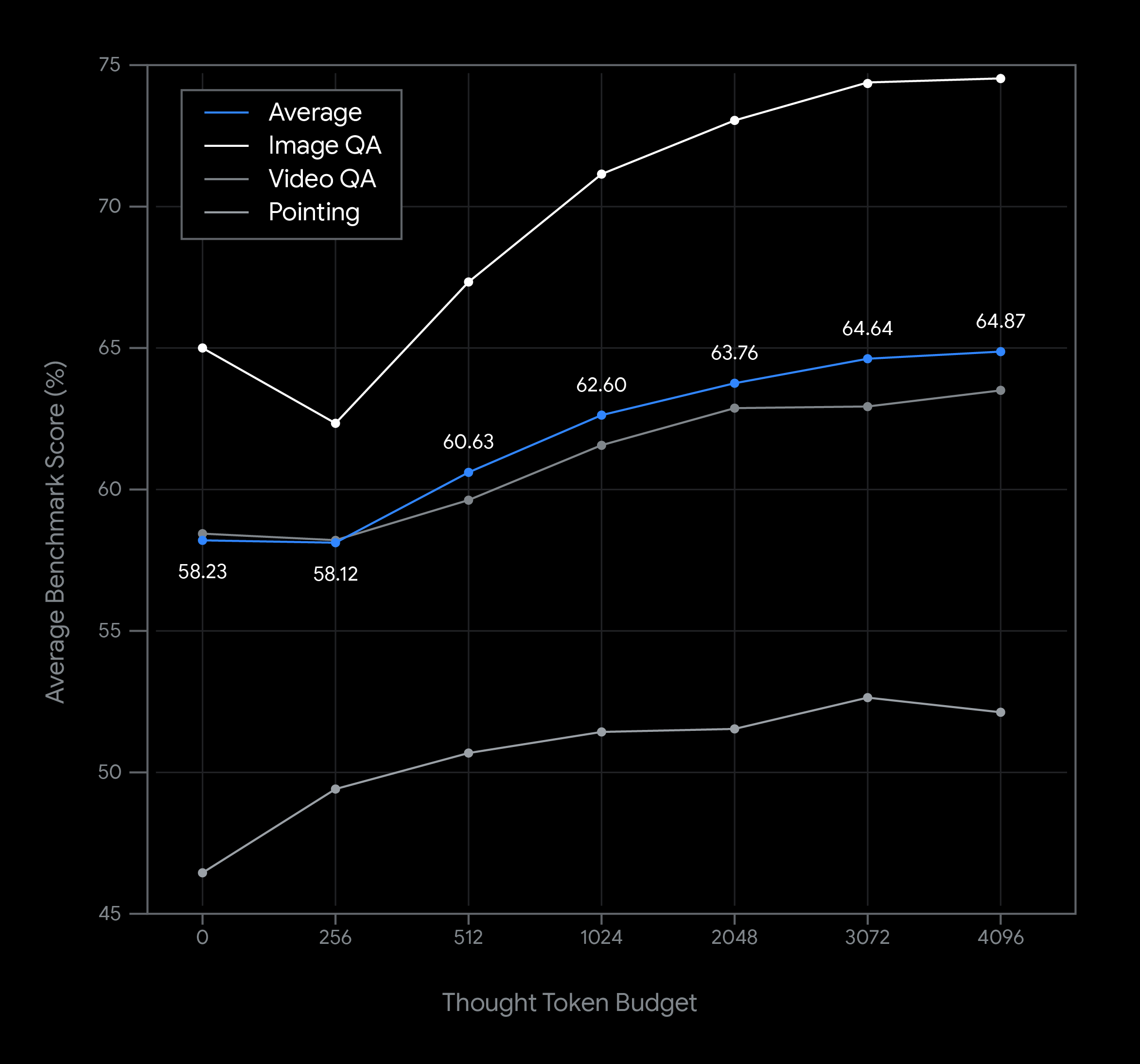
Gemini Robotics-ER 1.5 모델에서는 사고 기능이 기본적으로 활성화되지만, 요청 시 thinking_config 옵션을 포함하여 사고 예산을 설정하거나 사고 기능을 비활성화할 수도 있습니다. Gemini 사고 예산에 대한 자세한 내용은 여기에서 확인하실 수 있습니다.
저희는 여러분의 로보틱스 애플리케이션을 위한 책임감 있는 기반을 구축하기 위해 최선을 다하고 있습니다. Gemini Robotics-ER 1.5는 다음 두 가지 모두에 대한 필터를 강화하여 안전성을 크게 개선했습니다.
그러나 이러한 모델 수준의 안전장치는 물리적 시스템에 필요한 엄격한 안전 엔지니어링을 대체하지 못합니다. 저희는 여러 계층의 보호 장치가 함께 작동하는 안전에 대한 '스위스 치즈 접근 방식'을 지지합니다. 개발자는 비상 정지, 충돌 방지, 철저한 위험 평가를 포함한 표준 로보틱스 안전 권장사항을 구현할 책임이 있습니다.
Gemini Robotics-ER 1.5는 오늘 미리보기 버전으로 제공됩니다. 이 모델은 로봇의 추론 엔진 개발에 필요한 인식 및 계획 기능을 제공합니다.
이 모델은 더 광범위한 Gemini Robotics 시스템의 기본 추론 구성요소입니다. 엔드 투 엔드 액션 모델(VLA)과 교차 구현 학습 등 로보틱스의 미래에 대한 Google의 비전 뒤에 있는 과학적 근거를 이해하고 싶다면 연구 블로그와 기술 보고서 전문을 읽어보세요.



