

AI coding agents are rapidly shifting from reactive assistants that complete tasks when prompted to proactive engines that continuously absorb context, spot emerging risks, and surface diagnostic insights before developers have to ask. At the center of this evolution is a shift from well-defined tasks to goals, which require the agent to explore the codebase, discover what is relevant, and surface diagnostic observations that help guide developers toward a higher-level objective.
Public benchmarks like SWE-Bench test an agent’s ability to complete tasks, like fixing a narrowly defined bug, but no benchmarks currently exist for goals. In our most recent paper, Agentic Coding Needs Proactivity, Not Just Autonomy, we argue that proactive agents must be graded on their insight policy—the ability to decide what matters, what evidence supports it, and whether to interrupt the developer or stay silent.
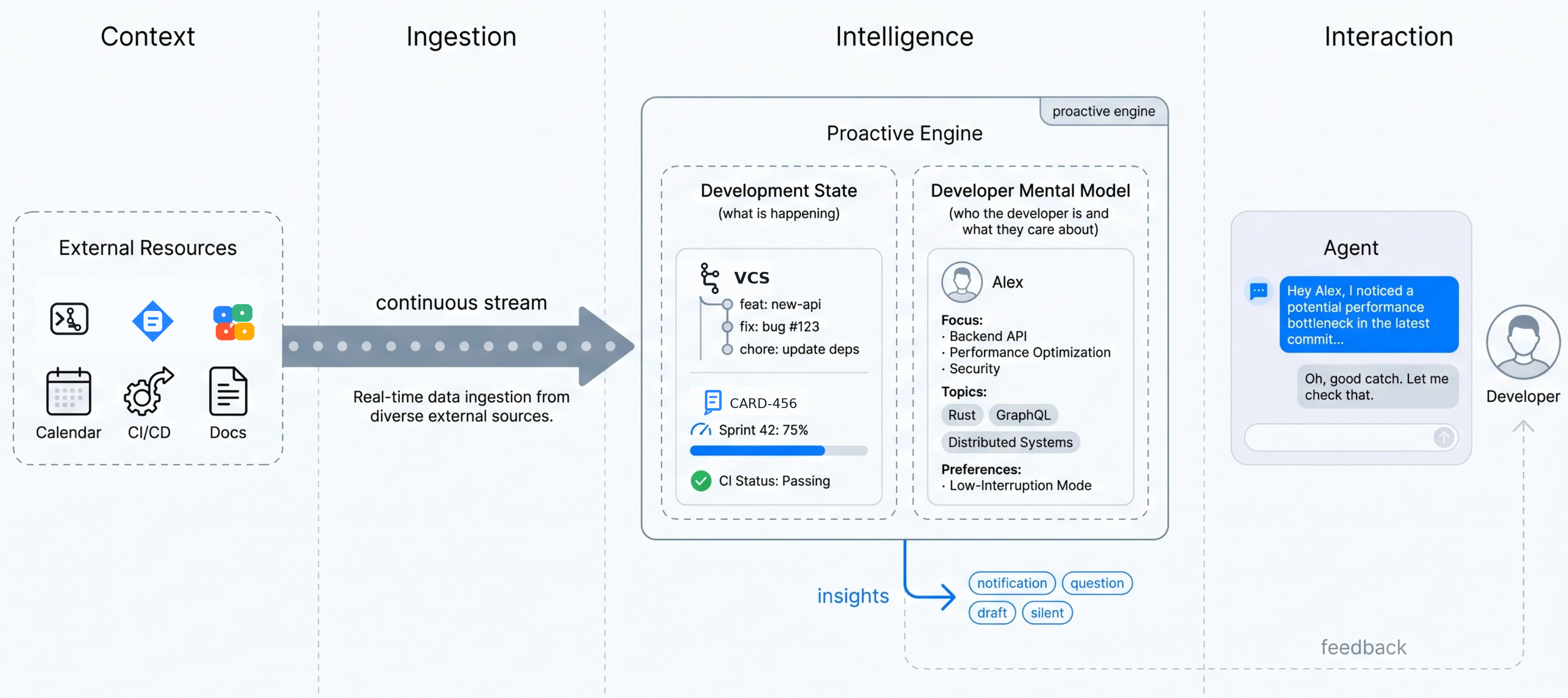
Based on our work on continuous AI systems at Google Labs, we’ve found that building evaluations capable of grading a proactive agent on its insight policy requires establishing a “ground truth.” One way to build this “ground truth” is to analyze a team’s real bug-fixing history along two heuristics we term temporal proximity and semantic similarity.
Our hypothesis is simple: when engineers file and fix several related bugs within a short time period, those bugs are often symptoms of a single underlying engineering effort. A cluster of bugs around "sandbox timeout errors," "broker config failures," and "network isolation flaky tests" all point toward a common aspirational goal like "Strengthen sandbox execution reliability." Individually, each bug is too task-specific to serve as a goal. Together, they reveal the higher-level objective.
To build our preliminary benchmark and test our hypothesis, we used 705 bugs (1,178 CLs) from internal Google codebases to:
The preliminary results of our testing are exciting for two primary reasons.
The core diagnostic logic works: Given a single exploration round, the agent consistently identified a highly relevant insight (averaging 4.5 out of 5). It successfully captured the primary signal for straightforward engineering problems.
Exploration budgets matter: Complex, multi-faceted problems are naturally harder, but giving the agent more resources to investigate pays off. By increasing the exploration budget from two rounds to three, the agent’s Hit@5 accuracy (defined as the rate at which a correct diagnostic insight appears within its top 5 recommendations) rebounded significantly from 33% to 57%. This proves that extra passes directly help the agent uncover secondary signals it initially missed.
These are preliminary results on an initial sample, and we are actively expanding coverage on multiple fronts. To start, we are expanding this evaluation to public GitHub data (issues and resolving PRs) to make this methodology broadly applicable to the wider AI community. We are also exploring how to ingest richer context streams like issue trackers, conversations, and design documents beyond just the codebase.
Read the full paper here and follow along with us at labs.google/code if you’re interested in learning more about our work on the future of coding at Google Labs.


