
사용자의 기기에서 직접 강력한 LLM(대규모 언어 모델)을 실행하면 제품 경험을 크게 향상시킬 수 있는 기능을 사용할 수 있습니다. 오프라인으로도 제공되므로 언제든지 쉽게 사용할 수 있으며, 비용 효율성(API 호출당 비용 없음)이 뛰어나서 텍스트 요약이나 교정 같은 실행 빈도가 높은 작업에 실용적입니다.
하지만 이러한 기가바이트 규모의 모델을 광범위한 에지 하드웨어에 배포하는 동시에 1초 미만의 TTFT(Time-to-First-Token) 지연 시간 및 요구되는 출력 품질 달성은 주요한 기술적 과제입니다. LiteRT-LM에서 바로 이러한 문제를 해결했습니다.
오늘, LiteRT-LM에 개발자가 직접 액세스할 수 있도록 하는 서비스를 제공하게 되어 기쁩니다. LiteRT-LM은 지금까지 Google 제품 전반에서 가장 광범위한 Gemini Nano 배포를 지원해온 프로덕션급 추론 프레임워크입니다. 검증 완료된 이 엔진은 Chrome, Chromebook Plus, Pixel Watch와 같은 제품에서 온디바이스 Gemini Nano 및 Gemma를 구동할 뿐만 아니라 MediaPipe LLM Inference API를 통해 다른 개방형 모델도 실행할 수 있도록 지원합니다.
이미 MediaPipe LLM Inference API, Chrome 기본 제공 AI API, Android AICore와 같은 상위 수준 API를 활용하여 LLM을 온디바이스로 실행할 수 있지만, 이제는 최초로 LiteRT-LM 엔진의 기본 C++ 인터페이스를 (미리보기로) 제공합니다. 이 하위 수준 액세스를 통해 자체 애플리케이션에 적합하게 맞춤 설정한 고성능 AI 파이프라인을 만들어, 선택한 플랫폼에서 엔진의 검증된 기술과 최적화된 성능을 활용할 수 있습니다. 오늘 바로 Google의 API를 활용하여 LLM 기반 애플리케이션 개발을 시작하고 최적화된 성능을 경험해 보세요.
특히 LiteRT-LM은 다음을 구동합니다.
LiteRT-LM은 Gemini Nano와 Gemma 같은 대규모 언어 모델을 실행하기 위해 설계되어 프로덕션 환경에서 테스트를 거친 추론 프레임워크로, 다양한 에지 기기에서 우수한 성능을 제공합니다. 본질적으로 LiteRT-LM은 통합하기 쉬운 API와 재사용 가능한 모듈 세트를 제공하는 완전 오픈소스 프로젝트입니다. 개발자는 LiteRT-LM을 사용하여 제품의 기능 요구 사항에 대해 정확하게 맞춤화된 사용자 설정 LLM 파이프라인을 구축할 수 있습니다.
LiteRT-LM이 어디에 적합한지 파악하려면 추상화의 최저 수준부터 최상 수준까지, 전체 Google AI Edge 스택을 살펴보면 도움이 됩니다.
이렇게 계층화된 구조는 프로젝트의 요구 사항에 가장 적합한 추상화 레이어에서 작업할 수 있는 유연성을 제공하는 한편, LiteRT-LM은 사용자 기기에 LLM(대규모 언어 모델)을 직접 대규모로 배포하려는 개발자에게 핵심 성능과 적응성을 제공합니다.
LiteRT-LM의 주요 특징은 다음과 같습니다.
저희는 Chrome 브라우저, Chromebook, 최신 Pixel Watch 등에서 수억 대의 기기에 달하는 대규모 배포를 강조하는 두 가지 우수사례를 통해 이러한 다재다능함을 입증합니다.
기가바이트 규모의 첨단 LLM에는 고유한 배포 과제가 따라옵니다. 일반적으로 메가바이트 단위인 기존 머신러닝 모델과 달리, LLM은 규모가 워낙 크기 때문에 동일한 에지 기기에서 여러 기능을 제공하기 위해 매개변수가 수십억 개인 여러 특화된 모델(예: 요약용 모델과 채팅용 모델)을 따로 배포한다는 것은 비현실적입니다.
이 문제를 극복하고자, LiteRT-LM은 여러 기능이 하나의 기반 모델을 공유할 수 있도록 설계되었으며 기능별 맞춤 설정을 위해 가벼운 LoRA를 사용합니다. 이는 무거운 공유 리소스를 사용자 상호작용의 구성 가능한 상태 저장 요소로부터 분리하는 명확한 아키텍처 패턴 덕분에 가능합니다. 이러한 분리는 엔진과 세션이라는 두 가지 핵심 클래스를 통해 이루어집니다.
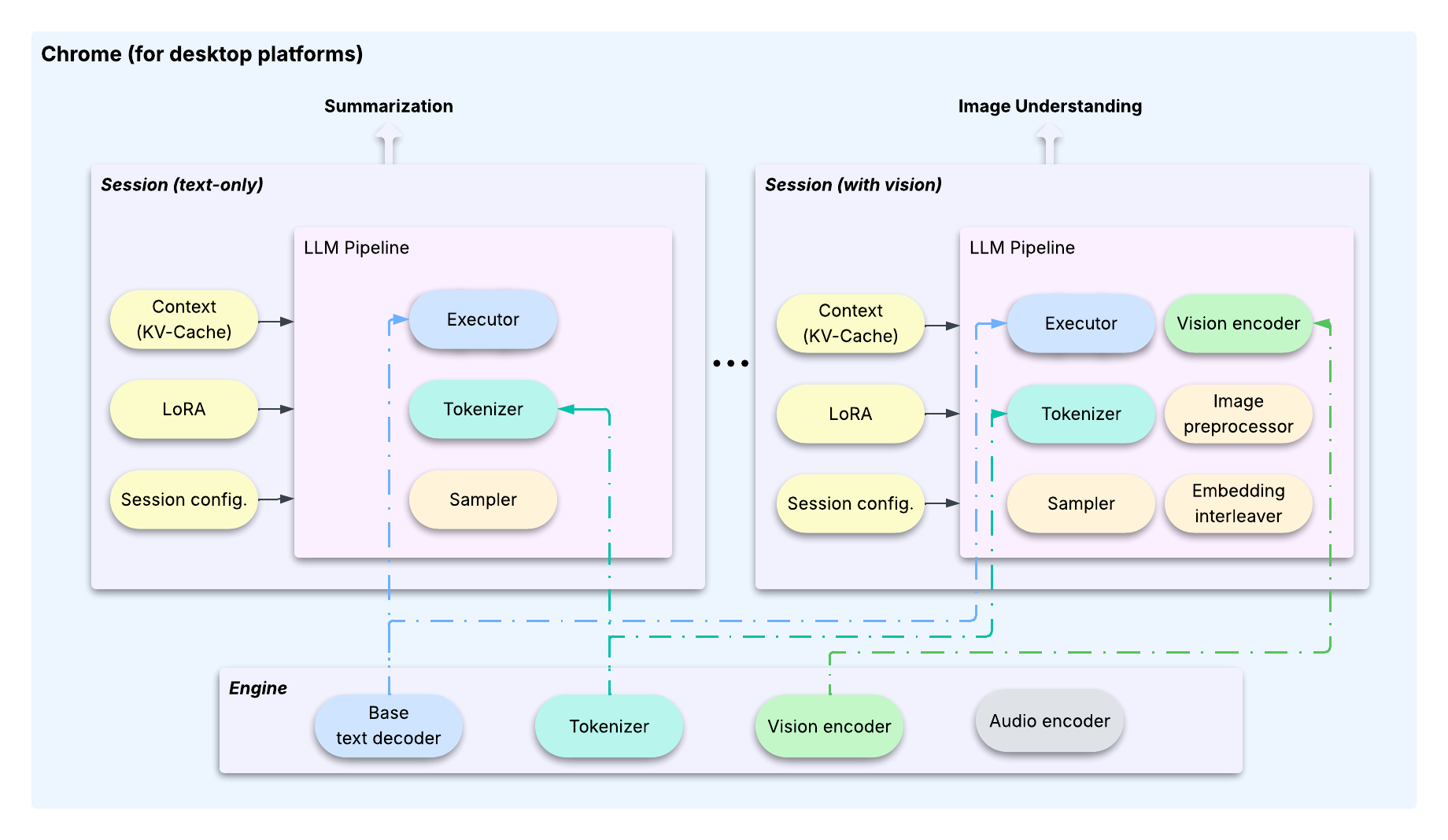
이 아키텍처는 효율적이고 리소스 사용량이 적은 작업 전환을 가능하게 하는 주요 최적화 기법에 의해 지원됩니다.1
세션은 Transformer의 KV 캐시, LoRA 가중치 등을 포함하여 전체 '컨텍스트'를 캡슐화합니다. OS와 마찬가지로, 작업 간 전환할 때 LiteRT-LM은 나가는 세션의 상태를 저장하고 들어오는 세션을 복원합니다. 이를 통해 공유 LLM이 항상 활성 작업에 대해 올바른 상태를 유지하도록 보장합니다.세션을 복제할 수 있습니다. 이렇게 하면 특정 시점의 계산된 KV 캐시 상태가 효과적으로 캐시되어 여러 새로운 작업이 해당 상태에서 분기할 수 있고 상당한 연산을 절약할 수 있습니다.세션은 KV 캐시를 즉시 복사하지 않고 원래 버퍼에 대한 참조를 생성합니다. 실제 복사는 세션이 다른 세션의 콘텐츠와 충돌하는 새 데이터를 덮어쓰려고 할 때만 수행됩니다. 이러한 설계 덕분에 복제 속도가 극히 빨라지고 (10ms 미만) kv 캐시 버퍼를 재사용하여 메모리 사용량을 최소화할 수 있습니다.이러한 아키텍처 기능과 최적화 기능은 Chrome과 Chromebook Plus에서 여러 고성능 온디바이스 LLM 기능을 성공적으로 생산화하는 데 핵심적인 역할을 합니다.
동시 작업 관리 외에도, 파편화된 기기 SKU 전반에서 ML 모델을 확장하는 것은 두 번째 주요한 기술적 장애물입니다. 각 SoC는 (CPU, GPU, NPU 전반에서) 구성 요소와 성능이 모두 다르므로, 모델 추론을 성능 기준에 맞춰 실행하기 위해서는 맞춤형 최적화가 필요합니다. LiteRT-LM은 LiteRT를 백엔드 위임을 위한 하위 수준의 런타임으로 활용하여 여러 하드웨어 가속기에서 확장성을 효율적으로 제공합니다. 더욱이, LiteRT-LM은 플랫폼별 구성요소(예: 파일 설명자 및 mmap)를 추상화하는 핵심 설계를 통해 폭넓은 플랫폼 호환성을 달성하며, 필요한 경우 네이티브 구현을 제공합니다.
1여기서 언급된 일부 최적화는 이 초기 미리보기에 포함되지 않지만 향후 버전에서 단계적으로 출시될 예정입니다.
Pixel Watch와 같이 리소스가 극도로 제한된 기기에 LLM을 배포하는 것은 완전히 다른 차원의 도전 과제를 안겨줍니다. 이러한 플랫폼에서는 하나의 공유 모델로 여러 기능을 지원하는 것보다 가능한 한 가장 작은 바이너리 크기와 메모리 공간을 유지하면서 단일한 특정 기능 전용 모델을 배포하는 것으로 우선순위가 바뀝니다.
바로 이 부분이 LiteRT-LM의 모듈식 설계가 필수적인 지점입니다. Google의 엔진/세션 아키텍처는 복잡한 다중 작업 배포를 관리하는 데 강력하지만, 바이너리 크기는 웨어러블 기기의 엄격한 요구 사항을 충족하기에 충분하지 않습니다.
대신, 개발자는 이 프레임워크를 통해 핵심 구성요소에서 직접 맞춤 설정 파이프라인을 만들 수 있습니다. Pixel Watch의 경우 실행기, 토크나이저, 샘플러와 같은 최소한의 필수 모듈을 선택하고 전문 파이프라인을 구성했습니다. 이러한 접근 방식을 통해 아래 그림과 같이 기기의 리소스 제약 사항을 충족하도록 바이너리 크기와 메모리 사용량을 최소화할 수 있었습니다.
이 우수사례는 LiteRT-LM의 유연성을 보여줍니다. 개발자는 LiteRT-LM의 모듈식 구성요소를 통해 고성능 스마트폰부터 제약이 있는 웨어러블 기기까지 모든 대상 기기의 특정 리소스 및 기능 요구 사항에 맞게 정확하게 맞춤화된 LLM 배포를 만들 수 있습니다.
지금 바로 시작해 사용자에게 강력하고 효율적인 온디바이스 생성형 AI를 제공하세요.
#include "YOUR_INCLUDE_DIRECTORY/engine.h"
// ...
// 1. Define model assets and engine settings.
auto model_assets = ModelAssets::Create(model_path);
CHECK_OK(model_assets);
auto engine_settings = EngineSettings::CreateDefault(
model_assets, litert::lm::Backend::CPU);
// 2. Create the main Engine object.
absl::StatusOr<std::unique_ptr<Engine>> engine = Engine::CreateEngine(engine_settings);
CHECK_OK(engine);
// 3. Create a Session for a new conversation.
auto session_config = SessionConfig::CreateDefault();
absl::StatusOr<std::unique_ptr<Engine::Session>> session = (*engine)->CreateSession(session_config);
CHECK_OK(session);
// 4. Generate content using the high-level API.
absl::StatusOr<Responses> responses = (*session)->GenerateContent(
{InputText("What is the tallest building in the world?")});
CHECK_OK(responses);
// 5. Print the response.
std::cout << *responses << std::endl;이 프로젝트의 기초 작업에 도움을 주신 주요 참여자 Advait Jain, Austin Sullivan, Clark Duvall, Haoliang Zhang, Ho Ko, Howard Yang, Marissa Ikonomidis, Mohammadreza Heydary, Ronghui Zhu, Tyler Mullen, Umberto Ravaioli, Weiyi Wang, Xu Chen, Youchuan Hu 님께 특별한 감사를 전하고 싶습니다.
또한 Agi Sferro, Chi Yo Tsai, David Massoud, Dillon Sharlet, Frank Barchard, Grant Jensen, Ivan Grishchenko, Jae Yoo, Jim Pollock, Majid Dadashi, Quentin Khan, Raman Sarokin, Ricky Liang, Tenghui Zhu, Terry (Woncheol) Heo, Yi-Chun Kuo, Yishuang Pang 등 팀원들의 큰 기여에도 감사드립니다.
Cormac Brick, Etienne Noël, Juhyun Lee, Lu Wang, Matthias Grundmann, Sachin Kotwani 등 저희 지도부의 지도와 지원에 힘입어 이 프로젝트를 성공리에 수행할 수 있었습니다.



