
強力な大規模言語モデル(LLM)をユーザーのデバイス上で直接実行すると、さまざま機能が利用可能となり、製品体験を大幅に向上させることができます。LLM をオフラインで利用可能なため、いつでもすぐに利用でき、さらにコスト効率が高いため(API 呼び出しごとのコストが不要)、文章要約や校正といった高頻度のタスクに役立ちます。
しかし、ギガバイト規模のモデルを幅広いエッジ ハードウェアにデプロイしつつ、最初のトークンが出力されるまでの時間(TTFT)のレイテンシ速度を 1 秒未満に抑えながら必要な出力品質を実現することは、大きな技術的課題です。LiteRT-LM では、これらの課題に対応しました。
この度 Google では、デベロッパー向けに、これまで Google のプロダクトに最も広くデプロイされてきた Gemini Nano を支えるプロダクション レディな推論フレームワーク LiteRT-LM への直接アクセスの提供を開始いたしました。この実績豊富なエンジンにより、Chrome、Chromebook Plus、Google Pixel Watch といったプロダクトにおいて、オンデバイスで Gemini Nano や Gemma を動作させられるほか、MediaPipe LLM Inference API を通じて他のオープンモデルも利用できるようになります。
すでに、MediaPipe LLM Inference API、Chrome の組み込み AI API、Android AICore などの高レベル API を活用して、デバイス上で LLM を実行できますが、今回初めて、LiteRT-LM エンジンの基礎となる C++インターフェース(プレビュー版)の提供を開始いたしました。この低レベルのアクセスにより、独自のアプリケーションに合わせた、カスタムかつ高性能の AI パイプラインを構築でき、実績あるテクノロジーと最適化された性能をお好みのプラットフォームで活用できます。これらの API を活用して、LLM を利用したアプリケーションの構築を開始し、この最適化された性能をぜひお試しください。
具体的には、次のプロダクトで LiteRT-LM が活用されています。
LiteRT-LM は、さまざまなエッジデバイスで、Gemini Nano や Gemma のような大規模言語モデルを高性能に実行するために設計された、本番環境でテスト済みの推論フレームワークです。LiteRT-LM は、完全なオープンソース プロジェクトであり、簡単に統合できる API と再利用可能なモジュールのセットを備えています。これにより、デベロッパーはプロダクトの機能要件に合わせて正確にカスタマイズされた LLM パイプラインを構築できます。
LiteRT-LM の位置付けを理解するために、Google AI Edge のスタック全体を、抽象度の低いものから高いものまで見てみましょう。
このレイヤ構造により、プロジェクトのニーズに最も適した抽象度のレイヤで作業できる柔軟性が得られます。そして LiteRT-LM が、ユーザーのデバイス上に大規模言語モデル(LLM)をスケーラブルにデプロイするためのコア性能と適応性を提供します。
LiteRT-LM の主な特長は次のとおりです。
LiteRT-LM の多用途性を示すために、Chrome ブラウザ、Chromebook、最新の Google Pixel Watch にわたる、数億台のデバイスへのスケーラブルなデプロイに焦点を当てた 2 つの事例をご紹介します。
ギガバイト規模の最新の LLM は、デプロイにおいて特有の課題を抱えています。通常数メガバイト規模の従来の機械学習モデルと異なり、LLM は非常に大きいため、同じエッジデバイスで異なる機能を動作させるために、数十億のパラメータを持つ専用モデル(要約用やチャット用など)を複数デプロイすることは現実的ではありません。
この課題を解決するために、LiteRT-LM は複数の機能が単一の基盤モデルを共有できるよう設計されており、機能ごとのカスタマイズには軽量な LoRA を使用します。これを可能にしているのが、重い共有リソースと、ユーザー インタラクションに関わる設定可能でステートフルな要素とを分離する、明確なアーキテクチャ パターンです。この分離は、エンジンとセッションという 2 つのコアクラスによって行われています。
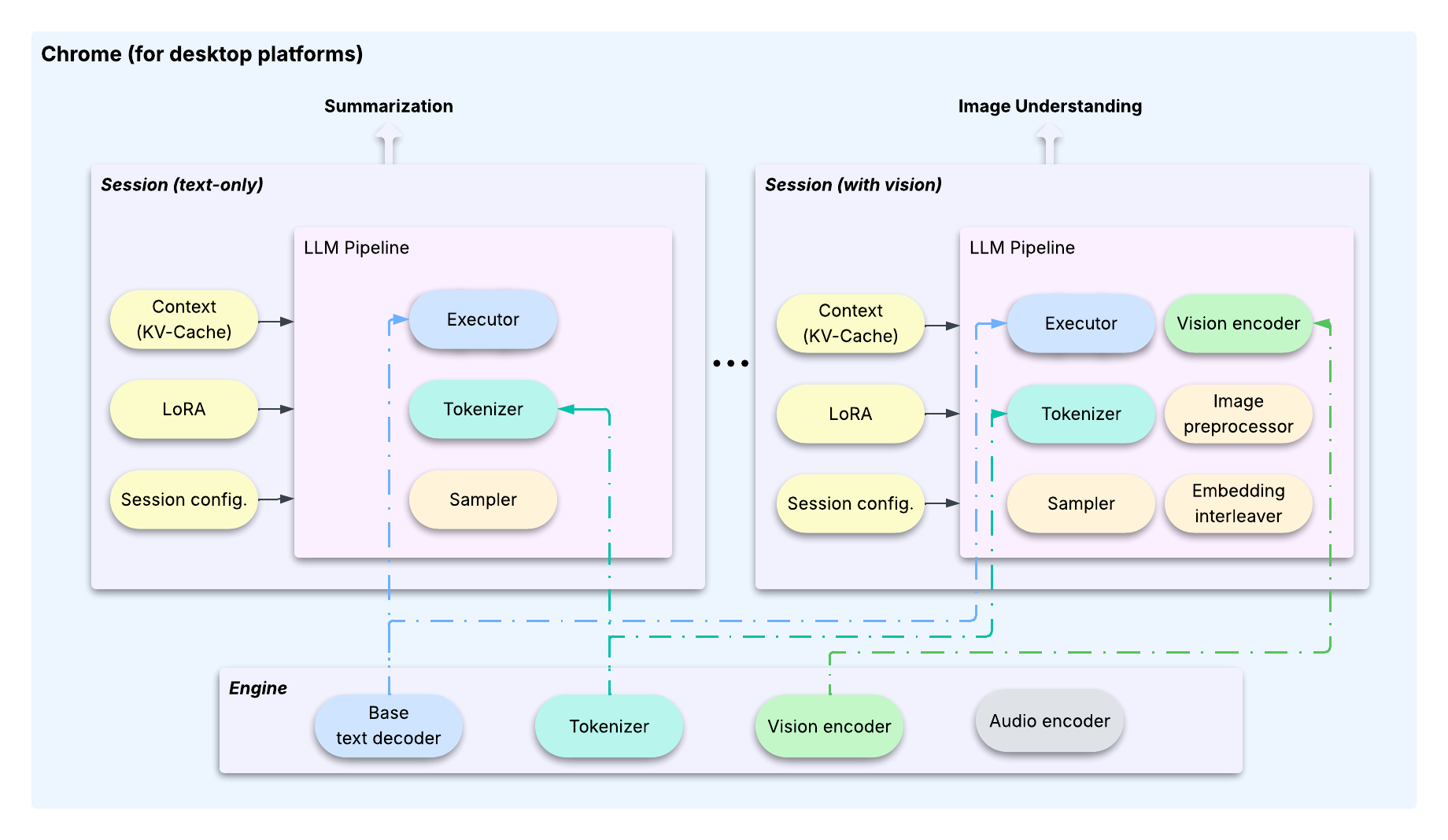
このアーキテクチャは、効率的でフットプリントの少ないタスク切り替えを可能にする最適化の工夫によって支えられています1。
セッションは、Transformer の KV キャッシュ、LoRA weight など、完全な「コンテキスト」をカプセル化します。OS と同様に、タスクを切り替える際、LiteRT-LM は、送信セッションの状態を保存し、受信セッションの状態を復元します。これにより、共有 LLM は常にアクティブなタスクの正しい状態を保持できます。セッションのクローンを作成できます。これにより、特定の時点で計算済みの KV キャッシュの状態が効率的にキャッシュ保存され、複数の新しいタスクがその状態から分岐できるようになり、計算量が大幅に削減されます。セッションはすぐに KV キャッシュをコピーせず、元のバッファへの参照を作成します。実際のコピーは、セッションが他のセッションのコンテンツと一致しない新しいデータを上書きしようとする際に行われます。この設計により、クローンの作成が非常に高速になり(<10ms)、KV キャッシュのバッファを再利用することでメモリ使用量も最小化されます。これらのアーキテクチャと最適化の機能は、Chrome や Chromebook Plus において、複数の高性能オンデバイス LLM 機能を正常に実用化するための鍵です。
また、同時並行のタスク管理に加えて、断片化したデバイス SKU 全体に ML モデルをスケーリングすることも、大きな技術的課題です。各 SoC は CPU、GPU、NPU にわたって、コンポーネントや機能が異なるため、モデル推論を高いパフォーマンスで行うにはカスタムの最適化が求められます。LiteRT-LM は、低レベルランタイムとして LiteRT を活用してバックエンドでの委任を行っているため、複数のハードウェア アクセラレータに効率的にスケーリングできます。さらに、LiteRT-LM は、プラットフォーム固有のコンポーネント(ファイル記述子や mmap など)を抽象化するコア設計によって幅広いプラットフォームの互換性を実現しており、必要に応じてネイティブ実装を提供します。
1ここで紹介されている最適化の一部は、この早期プレビュー版には含まれていませんが、今後のバージョンで段階的に提供される予定です。
Google Pixel Watch のようにリソースが極端に制限されたデバイスに LLM をデプロイする際には、まったく異なる課題が生じます。こうしたプラットフォームでは、共有モデルで複数の機能をサポートすることよりも、可能な限り小さなバイナリサイズとメモリ使用量で単一の専用機能をデプロイすることが優先されます。
ここで LiteRT-LM のモジュール設計が重要になります。エンジンおよびセッションのアーキテクチャは、複雑かつマルチタスクのデプロイを管理するには最適ですが、ウェアラブル デバイスの厳しい制約に対しては、バイナリ フットプリントが大きすぎます。
そこで、このフレームワークでは、デベロッパーがコア コンポーネントから直接カスタム パイプラインを構築できるようになっています。ここでは Google Pixel Watch 向けに、エグゼキュータ、トークナイザー、サンプラーといった必要最小限のモジュールを選択し、専用のパイプラインを作成しました。このアプローチにより、下図に示すように、バイナリサイズとメモリ使用量を最小化し、デバイスのリソース制約に対応することができました。
このケーススタディは、LiteRT-LM の柔軟性を示しています。LiteRT-LM のモジュール コンポーネントにより、デベロッパーは高性能なスマートフォンから制約の厳しいウェアラブルまで、あらゆる対象デバイスのリソースや機能要件に正確に合わせた LLM デプロイを作成できます。
強力かつ効率的なオンデバイス生成 AI を、ユーザーに届けましょう。
#include "YOUR_INCLUDE_DIRECTORY/engine.h"
// ...
// 1. Define model assets and engine settings.
auto model_assets = ModelAssets::Create(model_path);
CHECK_OK(model_assets);
auto engine_settings = EngineSettings::CreateDefault(
model_assets, litert::lm::Backend::CPU);
// 2. Create the main Engine object.
absl::StatusOr<std::unique_ptr<Engine>> engine = Engine::CreateEngine(engine_settings);
CHECK_OK(engine);
// 3. Create a Session for a new conversation.
auto session_config = SessionConfig::CreateDefault();
absl::StatusOr<std::unique_ptr<Engine::Session>> session = (*engine)->CreateSession(session_config);
CHECK_OK(session);
// 4. Generate content using the high-level API.
absl::StatusOr<Responses> responses = (*session)->GenerateContent(
{InputText("What is the tallest building in the world?")});
CHECK_OK(responses);
// 5. Print the response.
std::cout << *responses << std::endl;このプロジェクトの基盤となる作業に尽力してくださった次の主要な貢献者の皆様に心より感謝いたします。Advait Jain、Austin Sullivan、Clark Duvall、Haoliang Zhang、Ho Ko、Howard Yang、Marissa Ikonomidis、Mohammadreza Heydary、Ronghui Zhu、Tyler Mullen、Umberto Ravaioli、Weiyi Wang、Xu Chen、Youchuan Hu
また、次のチームメンバーによる多大な貢献にも深く感謝いたします。Agi Sferro、Chi Yo Tsai、David Massoud、Dillon Sharlet、Frank Barchard、Grant Jensen、Ivan Grishchenko、Jae Yoo、Jim Pollock、Majid Dadashi、Quentin Khan、Raman Sarokin、Ricky Liang、Tenghui Zhu、Terry (Woncheol) Heo、Yi-Chun Kuo、Yishuang Pang
さらに、本取り組みは、リーダーシップによる支援と指導なくしては成し得ませんでした。Cormac Brick、Etienne Noël、Juhyun Lee、Lu Wang、Matthias Grundmann、Sachin Kotwani に心より感謝いたします。



