Running powerful large language models (LLMs) directly on a user's device unlocks capabilities that can significantly enhance product experiences. Their offline availability makes them readily available at all times, while their cost efficiency (no per-API-call costs) makes them practical for high-frequency tasks such as text summarization or proofreading.
However, deploying these gigabyte-scale models across a wide range of edge hardware while achieving sub-second time-to-first-token (TTFT) latency speeds and the required output quality is a major technical challenge. We have addressed these in LiteRT-LM.
Today, we're excited to offer developers direct access to LiteRT-LM, the production-ready inference framework that has been powering some of the widest deployments of Gemini Nano across Google products to date. This battle-tested engine enables on-device Gemini Nano and Gemma in products like Chrome, Chromebook Plus, and the Pixel Watch, as well as other open models via the MediaPipe LLM Inference API.
You can already leverage the high-level APIs such as the MediaPipe LLM Inference API, Chrome Built-in AI APIs, and Android AICore to run LLMs on-device, but now, for the first time, we are providing the underlying C++ interface (in preview) of our LiteRT-LM engine. This low-level access allows you to build custom, high-performance AI pipelines tailored for your own applications, unlocking the engine's proven technology and optimized performance on your platform of choice. Leverage our APIs to start building your LLM-powered applications today to experience this optimized performance.
Specifically, LiteRT-LM is powering:
LiteRT-LM is a production-tested inference framework designed for running large language models, like Gemini Nano, Gemma, with high performance across a wide variety of edge devices. At its core, LiteRT-LM is a fully open-source project that provides an easy-to-integrate API and a set of reusable modules. This allows developers to build customized LLM pipelines that are precisely tailored to their product's feature requirements.
To understand where LiteRT-LM fits, it helps to look at the full Google AI Edge stack, from the lowest to the highest level of abstraction:
This layered structure gives you the flexibility to work at the layer of abstraction that best suits your project's needs, while LiteRT-LM provides the core power and adaptability for a developer trying to deploy large language models (LLMs) at scale directly on user devices.
Key highlights of LiteRT-LM include:
We demonstrate this versatility with two case studies highlighting its deployment at scale—spanning the Chrome browser, Chromebooks, and the latest Pixel Watches—to reach hundreds of millions of devices.
The gigabyte-scale of modern LLMs presents a unique deployment challenge. Unlike conventional machine learning models, which are typically on the order of megabytes, the sheer size of LLMs makes it impractical to deploy multiple, specialized multi-billion parameter models—for instance, one for summarization and another for chat—to power different features on the same edge device.
To overcome this, LiteRT-LM is designed to allow multiple features to share a single foundation model, using lightweight LoRAs for feature-specific customization. This is made possible by a clear architectural pattern that separates heavy, shared resources from the configurable and stateful aspects of user interactions. This separation is achieved through two core classes, the Engine and the Session:
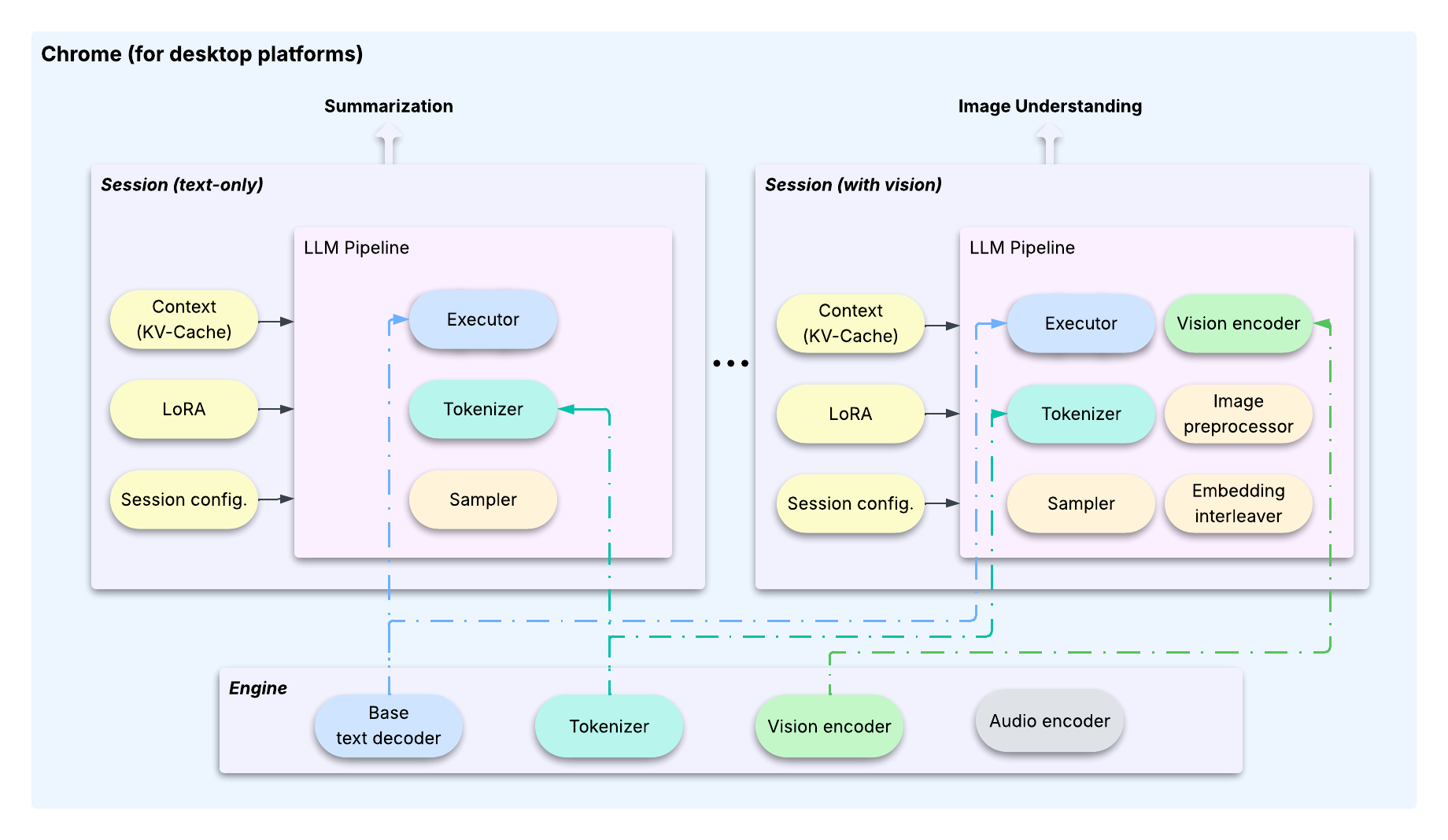
This architecture is supported by key optimizations that enable efficient, low-footprint task switching1:
Session encapsulates its full "context"—including the Transformer's KV-cache, LoRA weights..etc. Similar to an OS, when switching between tasks, LiteRT-LM saves the outgoing Session's state and restores the incoming one. This ensures the shared LLM always has the correct state for the active task.Session. This effectively caches the computed KV-cache state at a specific point, allowing multiple new tasks to branch off from that state and saving significant computation.Session doesn't immediately copy the KV-cache but creates a reference to the original buffer. An actual copy is only performed when a Session is about to overwrite new data that conflicts with another Sessions’ content. This design makes cloning extremely fast (<10ms) and minimizes the memory footprint by reusing the kv-cache buffers.Together, these architectural and optimization capabilities are key to successfully productionizing multiple high-performance, on-device LLM features in Chrome and Chromebook Plus.
Beyond managing concurrent tasks, scaling ML models across fragmented device SKUs presents a second major technical hurdle. Every SoC varies in components and capabilities (across CPU, GPU, and NPU), demanding custom optimization for running model inference performantly. LiteRT-LM leverages LiteRT as the lower-level runtime for backend delegation, enabling it to scale efficiently across multiple hardware accelerators. Furthermore, LiteRT-LM achieves broad platform compatibility through a core design that abstracts platform-specific components (like file descriptors and mmap), providing native implementations when necessary.
1Note that some optimizations mentioned are not included in this early preview, but will be gradually released in future versions.
Deploying LLMs on severely resource-constrained devices, such as the Pixel Watch, presents an entirely different set of challenges. On these platforms, the priority shifts from supporting multiple features with a shared model to deploying a single, dedicated feature with the smallest possible binary size and memory footprint.
This is where the modular design of LiteRT-LM becomes essential. While our Engine/Session architecture is powerful for managing complex, multi-task deployments, its binary footprint is not lean enough for the strict requirements of a wearable device.
Instead, the framework allows developers to build a custom pipeline directly from its core components. For the Pixel Watch, we selected the minimum required modules—such as the executor, tokenizer, and sampler—and assembled a specialized pipeline. This approach allowed us to minimize the binary size and memory usage to satisfy the device's resource constraints, as shown in the figure below.
This case study demonstrates the flexibility of LiteRT-LM. Its modular components empower developers to create LLM deployments that are precisely tailored to the specific resource and feature requirements of any target device, from powerful smartphones to constrained wearables.
Get started and bring powerful, efficient on-device generative AI to your users.
#include "YOUR_INCLUDE_DIRECTORY/engine.h"
// ...
// 1. Define model assets and engine settings.
auto model_assets = ModelAssets::Create(model_path);
CHECK_OK(model_assets);
auto engine_settings = EngineSettings::CreateDefault(
model_assets, litert::lm::Backend::CPU);
// 2. Create the main Engine object.
absl::StatusOr<std::unique_ptr<Engine>> engine = Engine::CreateEngine(engine_settings);
CHECK_OK(engine);
// 3. Create a Session for a new conversation.
auto session_config = SessionConfig::CreateDefault();
absl::StatusOr<std::unique_ptr<Engine::Session>> session = (*engine)->CreateSession(session_config);
CHECK_OK(session);
// 4. Generate content using the high-level API.
absl::StatusOr<Responses> responses = (*session)->GenerateContent(
{InputText("What is the tallest building in the world?")});
CHECK_OK(responses);
// 5. Print the response.
std::cout << *responses << std::endl;We'd like to extend a special thanks to our key contributors for their foundational work on this project: Advait Jain, Austin Sullivan, Clark Duvall, Haoliang Zhang, Ho Ko, Howard Yang, Marissa Ikonomidis, Mohammadreza Heydary, Ronghui Zhu, Tyler Mullen, Umberto Ravaioli, Weiyi Wang, Xu Chen, Youchuan Hu
We also gratefully acknowledge the significant contributions from the following team members: Agi Sferro, Chi Yo Tsai, David Massoud, Dillon Sharlet, Frank Barchard, Grant Jensen, Ivan Grishchenko, Jae Yoo, Jim Pollock, Majid Dadashi, Quentin Khan, Raman Sarokin, Ricky Liang, Tenghui Zhu, Terry (Woncheol) Heo, Yi-Chun Kuo, Yishuang Pang
This effort was made possible by the guidance and support from our leadership: Cormac Brick, Etienne Noël, Juhyun Lee, Lu Wang, Matthias Grundmann, and Sachin Kotwani.