

첫 번째 Gemma 모델은 작년 초에 출시된 이후 1억 6천만이 넘는 총 누적 다운로드 수를 기록하며 활발한 Gemmaverse로 성장했습니다. 이 생태계에는 보안부터 의료 애플리케이션까지 모든 분야에 특화된 12개가 넘는 모델이 포함되어 있고, 무엇보다도 커뮤니티에서 나온 수많은 혁신이 매우 고무적입니다. 엔터프라이즈 컴퓨터 비전을 개발하는 Roboflow와 같은 혁신 기업부터 고성능 일본 Gemma 대안 모델을 만드는 Institute of Science Tokyo까지, 개발자 여러분의 노력이 저희가 앞으로 나아갈 길을 보여주었습니다.
이 놀라운 추진력에 힘입어 Gemma 3n의 정식 출시를 발표하게 되어 기쁩니다. 지난달 미리보기를 통해 살짝 엿보았지만, 오늘은 이 모바일 우선 아키텍처의 모든 기능을 소개합니다. Gemma 3n은 Gemma를 개발하는 데 도움을 준 개발자 커뮤니티를 위해 설계되었습니다. Hugging Face Transformer, llama.cpp, Google AI Edge, Ollama, MLX 등 여러분이 선호하는 여러 도구가 Gemma 3n을 지원하므로 특정 온디바이스 애플리케이션에 맞게 쉽게 미세 조정하고 배포할 수 있습니다. 이 게시물은 개발자를 위한 심층 분석 자료입니다. Gemma 3n에 숨겨진 혁신에 대해 살펴보고, 새로운 업계 기준치 결과를 공유하고, 오늘 바로 개발을 시작하는 방법을 알려드리겠습니다.
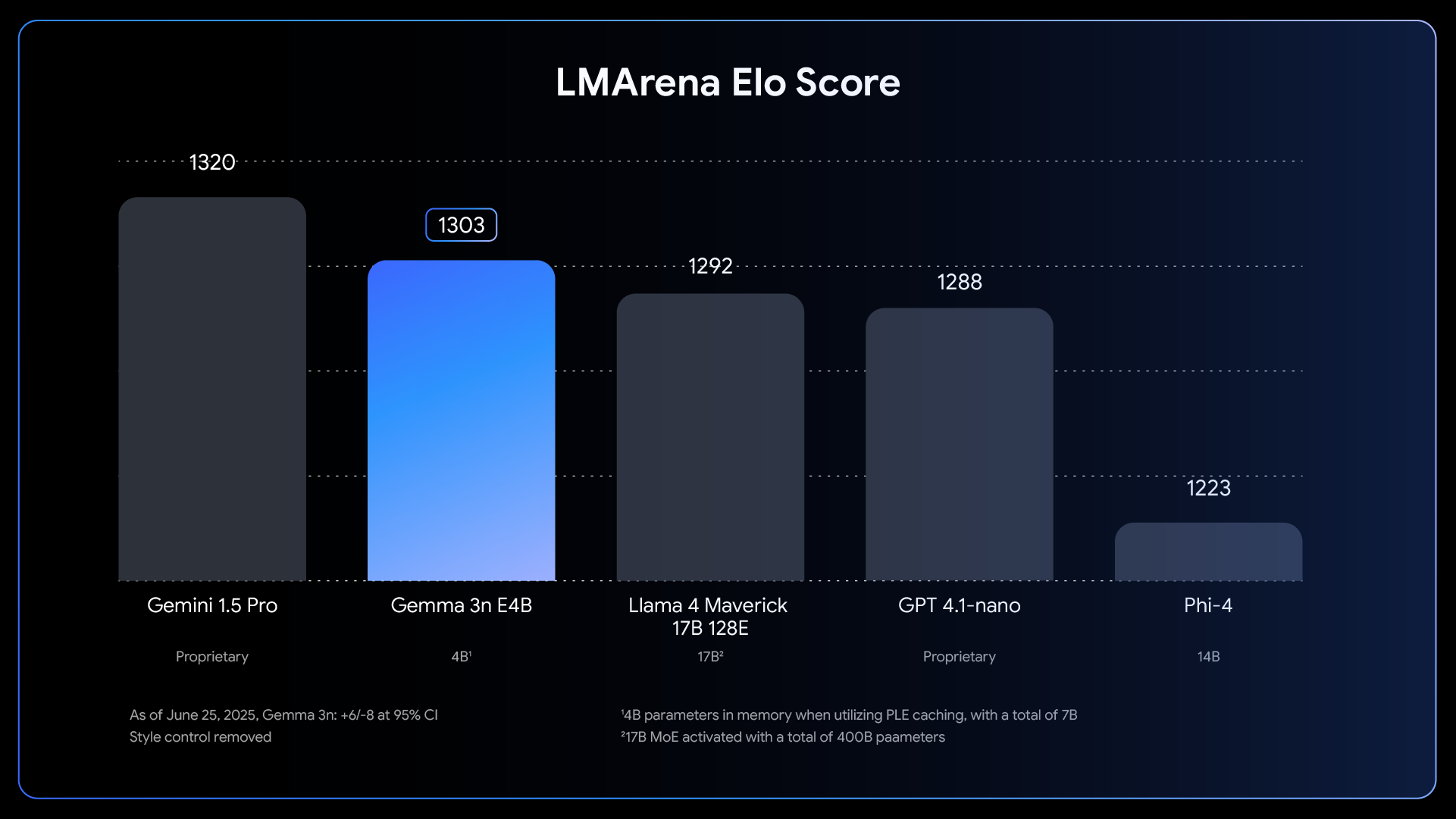
온디바이스 AI 분야에서의 중요한 발전을 상징하는 Gemma 3n은 작년 클라우드 기반 최첨단 모델에서만 가능했던 성능으로 에지 기기에도 강력한 멀티모달 기능을 제공합니다.
Link to Youtube Video (visible only when JS is disabled)
온디바이스 성능에서 이렇게 뛰어난 성과를 달성하기 위해서는 모델을 처음부터 다시 생각해야 했습니다. 그 기반은 Gemma 3n의 고유한 모바일 우선 아키텍처이며, 모든 것은 MatFormer에서 시작됩니다.
Gemma 3n의 핵심은 탄력적 추론을 위해 개발된 새로운 중첩 트랜스포머인 MatFormer(🪆Matryoshka Transformer) 아키텍처입니다. 마트료시카 인형과 같다고 생각해 보세요. 즉, 더 큰 모델 안에 더 작지만 완벽하게 기능하는 버전들이 포함되어 있습니다. 이 접근 방식은 마트료시카 표현 학습의 개념을 임베딩에서 모든 트랜스포머 구성요소로 확장합니다.

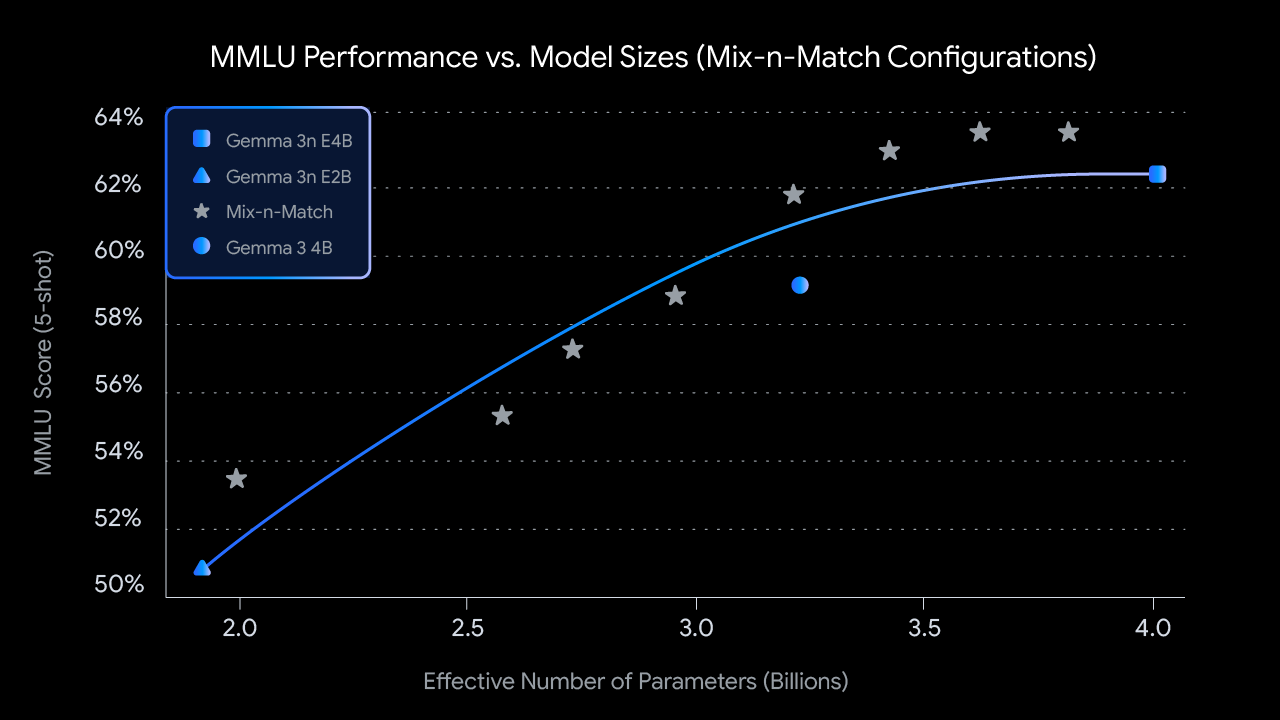
4B 유효 매개변수(E4B) 모델의 MatFormer 학습 중에 위의 그림과 같이 2B 유효 매개변수(E2B) 하위 모델이 그 내부에서 동시에 최적화됩니다. 이를 통해 현재 개발자는 다음 두 가지의 강력한 기능과 사용 사례를 얻을 수 있습니다.
1: 사전 추출 모델: 최고의 성능을 위해서는 메인 E4B 모델을, 최대 2배 빠른 추론 속도를 위해서는 독립형 E2B 서브 모델을 직접 다운로드하여 사용할 수 있습니다. 서브 모델은 사용자를 위해 사전에 추출해 두었습니다.
2: Mix-n-Match를 사용한 맞춤 설정 크기: 특정 하드웨어 제약 조건에 맞게 더욱 세밀한 제어를 하려면, Mix-n-Match라는 방법을 사용하여 E2B와 E4B 사이의 다양한 크기의 맞춤 모델을 만들 수 있습니다. 이 기법을 사용하면 E4B 모델의 매개변수를 정밀하게 슬라이스할 수 있는데, 이는 주로 각 레이어당 피드 포워드 네트워크에 숨겨진 차원 수를 조정(8192에서 16384로)하고 일부 레이어를 선택적으로 생략하는 방식으로 이루어집니다. MMLU 같은 업계 기준치에서 다양한 설정을 평가함으로써 최적의 모델을 식별한 후 이러한 모델을 불러오는 방법을 보여주는 도구인 MatFormer Lab을 출시합니다.
앞으로 MatFormer 아키텍처는 탄력적인 실행을 위한 기반을 마련할 것입니다. 오늘 출시되는 구현에는 포함되지 않지만, 이 기능을 사용하면 배포된 단일 E4B 모델이 E4B 추론 경로와 E2B 추론 경로를 신속하게 동적으로 전환하여 현재 작업 및 기기 부하에 따라 성능과 메모리 사용량을 실시간으로 최적화할 수 있습니다.
Gemma 3n 모델에는 PLE(Per-Layer Embeddings)가 포함되어 있습니다. 이 혁신적인 기술은 기기 가속기(GPU/TPU)에 필요한 고속 메모리 공간을 늘리지 않고도 모델 품질을 획기적으로 향상시키므로 온디바이스 배포에 매우 적합합니다.
Gemma 3n E2B 및 E4B 모델의 총 매개변수의 개수는 각각 5B(50억) 및 8B(80억)개이지만, PLE를 사용하면 이러한 매개변수(각 레이어와 관련된 임베딩)의 상당 부분을 CPU에 효율적으로 로드하고 계산할 수 있습니다. 이는 코어 트랜스포머 가중치(E2B의 경우 약 2B, E4B의 경우 약 4B)만 일반적으로 더 제한된 가속기 메모리(VRAM)에 저장하면 된다는 뜻입니다.

오디오 및 동영상 스트림에서 파생된 시퀀스 같은 긴 입력 데이터의 처리는 많은 고급 온디바이스 멀티모달 애플리케이션에 필수적입니다. Gemma 3n은 스트리밍 응답 애플리케이션의 최초 토큰까지의 시간을 크게 가속화하도록 설계된 기능인 KV Cache Sharing을 도입했습니다.
KV Cache Sharing은 모델이 초기 입력 처리 단계(종종 '프리필' 단계라고 함)를 다루는 방식을 최적화합니다. 로컬 및 글로벌 어텐션에서 중간 레이어의 키와 값은 모든 최상위 레이어와 직접 공유되어 Gemma 3 4B에 비해 프리필 성능이 2배나 향상되었습니다. 즉, 모델이 전보다 훨씬 빠르게 긴 프롬프트 시퀀스를 수집하고 이해할 수 있습니다.
Gemma 3n은 USM(Universal Speech Model) 기반의 고급 오디오 인코더를 사용합니다. 이 인코더는 160ms의 오디오마다 토큰을 생성하며 (초당 약 6개의 토큰), 이 토큰들은 언어 모델에 입력으로 통합되어 사운드 컨텍스트를 세밀하게 표현합니다.
이 통합 오디오 기능을 통해 다음을 포함한 온디바이스 개발을 위한 주요 기능을 활용할 수 있습니다.
영어와 스페인어, 프랑스어, 이탈리아어, 포르투갈어 간 번역에서 특히 뛰어난 성능을 보인 AST 결과를 확인했습니다. 이는 해당 언어로 된 애플리케이션을 목표로 하는 개발자에게 큰 잠재력을 선사합니다. 음성 번역과 같은 작업의 경우, Chain-of-Thought 프롬프트를 활용하면 결과를 크게 향상시킬 수 있습니다. 예를 들면 다음과 같습니다.
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>model출시 시점에 Gemma 3n 인코더는 최대 30초 길이의 오디오 클립을 처리하도록 구현되었습니다. 그러나 이것은 원천적인 제한은 아닙니다. 기본 오디오 인코더는 스트리밍 인코더로, 추가적인 긴 형식의 오디오 학습을 통해 얼마든 긴 오디오를 처리할 수 있습니다. 후속 구현에서는 지연 시간이 짧고 길이는 긴 스트리밍 앱을 선보일 예정입니다.
Gemma 3n은 통합 오디오 기능과 더불어 새로운 고효율 비전 인코더 MobileNet-V5-300M을 탑재하여 에지 기기에서 멀티모달 작업을 위한 최첨단 성능을 제공합니다.
제한된 하드웨어에서 유연성과 강력한 성능을 발휘하도록 설계된 MobileNet-V5는 개발자에게 다음을 제공합니다.
이러한 수준의 성능은 다음을 포함한 다양한 아키텍처 혁신을 통해 달성되었습니다.
새로운 아키텍처 설계와 고급 증류 기법의 이점을 활용하는 MobileNet-V5-300M은 Gemma 3의 기준선 SoViT(SigLip으로 학습, 증류 없음)를 크게 능가합니다. Google Pixel Edge TPU에서 MobileNet-V5-300M은 양자화로 속도를 13배 높이고 (없는 경우 6.5배), 필요한 매개변수 개수는 46% 더 적으며, 메모리 설치 공간은 4배 더 작은데, 동시에 비전 언어 작업에서 훨씬 높은 정확도를 제공합니다.
이 모델의 이면에서 이루어지는 작업에 대해 더 많은 내용을 알려드리게 되어 기쁩니다. 모델 아키텍처, 데이터 확장 전략, 고급 증류 기법을 심층적으로 살펴볼 예정인 MobileNet-V5 기술 보고서도 놓치지 말고 챙겨보세요.
Gemma 3n에 대한 접근성을 처음부터 높이는 것이 최우선 과제였습니다. AMD, Axolotl, Docker, Hugging Face, llama.cpp, LMStudio, MLX, NVIDIA, Ollama, RedHat, SGLang, Unsloth, vLLM의 여러 팀의 참여를 비롯해, 다양한 인기 도구와 플랫폼 전반에 걸친 광범위한 지원을 보장하기 위해 많은 뛰어난 오픈소스 개발자와 협력하게 되어 자랑스럽습니다.
하지만 이 생태계는 시작에 불과합니다. 이 기술의 진정한 힘은 개발자 여러분이 이 기술을 활용해 만들어낼 결과물에 있습니다. 이에 저희는 Gemma 3n Impact Challenge를 시작합니다. 개발자 여러분의 임무는 Gemma 3n의 고유한 온디바이스, 오프라인 및 멀티모달 기능을 사용하여 더 나은 세상을 위한 제품을 개발하는 것입니다. 150,000달러의 상금을 걸고 강렬한 동영상 스토리와 실제 세상에 미치는 영향을 보여주는 '놀라운' 요소가 있는 데모를 찾고 있습니다. 챌린지에 동참하여 더 나은 미래를 만드는 데 힘을 보태 주세요.
오늘 바로 Gemma 3n의 잠재력을 탐색할 준비가 되셨나요? 방법은 다음과 같습니다.



