

最初の Gemma モデルがリリースされたのは昨年の初めでした、それ以来、このモデルは合計で 1 億 6000 万回ダウンロードされ、活気ある Gemmaverse へと成長を遂げています。このエコシステムには、安全性から医療までをカバーする 12 以上の専用モデルのファミリーが含まれています。そして一番感動的なのは、コミュニティから数え切れないほどのイノベーションが生まれていることです。Roboflow のようなエンタープライズ コンピュータ ビジョンを開発したイノベーター、高性能な日本語 Gemma バリアントを作成した東京科学大学など、皆さんの成果が今後進むべき道を示してくれました。
この信じられないほどの勢いを基に、Gemma 3n の完全リリースを発表できることをうれしく思います。先月のプレビュー版で先行してお試しいただきましたが、本日より、このモバイルファースト アーキテクチャのパワーを最大限に活用できるようになります。Gemma 3n は、Gemma の開発に貢献したデベロッパー コミュニティ向けに設計されています。Hugging Face Transformers、llama.cpp、Google AI Edge、Ollama、MLX など、皆さんのお気に入りのツールがサポートされているので、特定のオンデバイス アプリケーション向けに簡単にファインチューニングしてデプロイできます。この投稿では、デベロッパーの皆さん向けに、Gemma 3n を支えるいくつかのイノベーション、新しいベンチマークの結果、そして今すぐ開発を始める方法を詳しく説明します。
Gemma 3n は、オンデバイス AI の大きな進歩を表しています。強力なマルチモーダル機能をエッジデバイスにもたらし、昨年発表されたクラウドベースの最先端モデルでしか得られなかったパフォーマンスを発揮できるようにします。
Link to Youtube Video (visible only when JS is disabled)
この飛躍的なオンデバイス パフォーマンスを実現するため、モデルをゼロから見直しました。その基盤となったのは Gemma 3n 独自のモバイルファースト アーキテクチャであり、そのすべては MatFormer から始まりました。
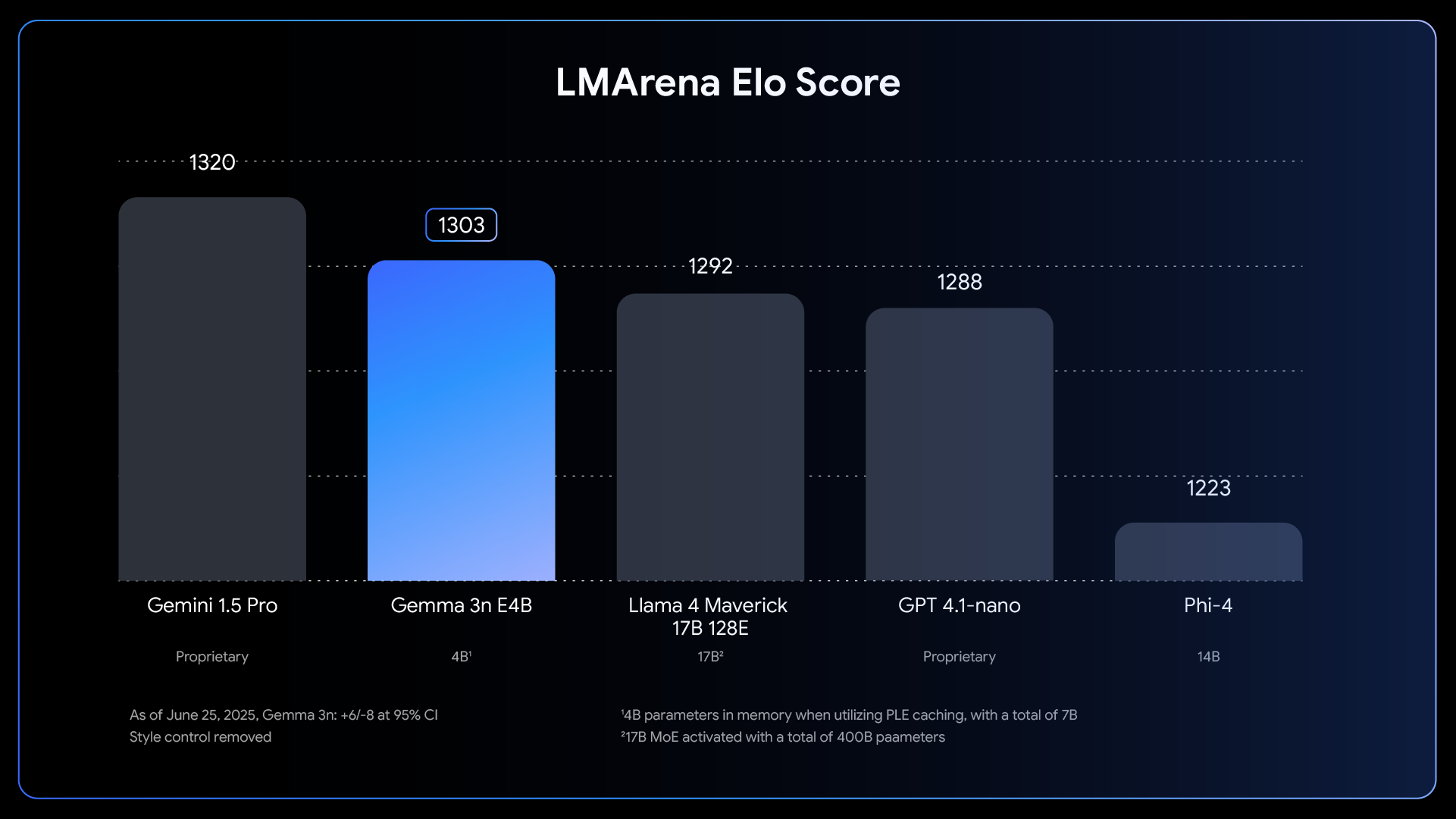
Gemma 3n の中核部は、柔軟な推論を行うために作られた革新的な入れ子型トランスフォーマーである MatFormer(🪆Matryoshka Transformer)アーキテクチャです。これはマトリョーシカ人形のようなものだと考えてください。大きなモデルの中に、小さいながらも完全に動作するバージョンが含まれています。このアプローチにより、マトリョーシカ特徴表現学習の考え方を、単なる埋め込みだけでなく、すべてのトランスフォーマー コンポーネントに拡張できるようになります。

上の図で示すように、実効パラメータ数が 4B(E4B)のモデルの MatFormer をトレーニングするときに、内部で実効パラメータ数 2B(E2B)のサブモデルが同時に最適化されます。この仕組みにより、2 つの強力な機能とユースケースが実現します。
1: 事前抽出済みモデル: メインの E4B モデルを直接ダウンロードして最高の機能を実現することも、事前抽出済みのスタンドアロンの E2B サブモデルを使うこともできます。後者は最大 2 倍高速に推論できます。
2: Mix-n-Match によるカスタムサイズ: 特定のハードウェア制約に合わせて細かく制御したい場合は、Mix-n-Match と呼ばれる方法で E2B と E4B の間でカスタムサイズのモデルを自由に作成できます。この手法を使うと、主に、レイヤごとにフィード フォワード ネットワークの隠れ次元(8,192 から 16,384 まで)を調整し、一部のレイヤを選んでスキップすることで、E4B モデルのパラメータを正確にスライスできます。最適なモデルを得る方法を示すツールとして、MatFormer Lab をリリースします。MMLU などのベンチマークでさまざまな設定を評価することで、最適なモデルを特定できます。
将来に目を向ければ、MatFormer アーキテクチャは柔軟な実行を実現する道を開くものでもあります。本日のリリースには実装されていませんが、この機能を利用すると、1 つの E4B モデルをデプロイするだけで、E4B と E2B の推論パスを動的に切り替えることができるので、現在のタスクやデバイスの負荷に応じて、パフォーマンスやメモリ使用量をリアルタイムで最適化できます。
Gemma 3n モデルには、Per-Layer Embeddings(PLE)が導入されています。このイノベーションは、デバイスのアクセラレータ(GPU/TPU)が必要とする高速メモリ フットプリントを増やすことなく、モデルの品質を劇的に向上させることができるので、オンデバイス デプロイに最適です。
Gemma 3n の E2B および E4B モデルは、総パラメータ数はそれぞれ 5B と 8B ですが、PLE のおかげで、大多数のパラメータ(各層の埋め込み)を CPU に効率的に読み込んで計算できるようになっています。そのため、コアとなるトランスフォーマーの重み(E2B の場合は約 2B、E4B の場合は約 4B)だけをアクセラレータのメモリ(VRAM)に格納するだけで済みます。通常、このメモリにはさまざまな制約があります。

多くの高度なオンデバイス マルチモーダル アプリケーションでは、音声や動画のストリームで生成されるシーケンスなど、長い入力を処理することが不可欠です。Gemma 3n には KV キャッシュ共有機能が導入されています。この機能は、ストリーミング応答アプリケーションで、最初のトークンが生成されるまでの時間を大幅に短縮するように設計されています。
KV キャッシュ共有は、モデルが初期入力処理段階(多くの場合、「プレフィル」段階と呼ばれます)にある際の処理方法を最適化します。ローカル アテンションとグローバル アテンションの中間レイヤのキーと値が、すべての最上位レイヤと直接共有されるので、Gemma 3 4B と比較してプレフィルのパフォーマンスが 2 倍向上しています。つまり、長いプロンプト シーケンスでも、以前よりはるかに速く取り込んで理解できます。
Gemma 3n では、Universal Speech Model(USM)に基づいた高度な音声エンコーダが使われています。エンコーダは 160ms の音声(毎秒約 6 トークン)ごとにトークンを生成し、それが言語モデルへの入力に組み込まれて、詳細な音声コンテキストを提供します。
音声機能が内蔵されているので、次のような主要機能をオンデバイス開発に利用できます。
英語とスペイン語、フランス語、イタリア語、ポルトガル語の間の翻訳では、特に AST が威力を発揮します。これらの言語のアプリケーションをターゲットとするデベロッパーにとって、大きな可能性となるはずです。音声翻訳などのタスクでは、思考の連鎖プロンプトを活用すると、結果を大幅に向上させることができます。次の例をご覧ください。
<bos><start_of_turn>user
Transcribe the following speech segment in Spanish, then translate it into English:
<start_of_audio><end_of_turn>
<start_of_turn>modelリリース時点では、Gemma 3n のエンコーダは、最大 30 秒の音声クリップを処理する実装となっています。ただし、これは必須の制限ではありません。ベースとなる音声エンコーダはストリーミング エンコーダなので、長い形式の音声で追加トレーニングを行うことで、任意の長さの音声を処理できるようになります。今後の実装で、低遅延、長時間のストリーミング用途に対応する予定です。
Gemma 3n には、音声機能だけでなく、非常に効率的な新型ビジョン エンコーダ MobileNet-V5-300M が搭載されています。そのため、エッジデバイスのマルチモーダル タスクを最先端のパフォーマンスで実行できます。
MobileNet-V5 は、制約の強いハードウェアでも柔軟性とパワーを発揮できるように設計されているので、デベロッパーは次のようなメリットを活用できます。
このレベルのパフォーマンスは、次のような複数のアーキテクチャのイノベーションによって実現しています。
MobileNet-V5-300M は、革新的なアーキテクチャ設計と高度な蒸留手法のおかげで、Gemma 3(SigLip でトレーニング、蒸留なし)のベースライン SoViT を大幅に上回っています。Google Pixel Edge TPU では、ビジョン言語タスクで大幅に高い精度を維持したまま、量子化ありで 13 倍高速化(量子化なしでは 6.5 倍)、必要なパラメータ数を 46% 削減、メモリ フットプリントを4分の1に削減しています。
このモデルを支える作業について、さらに詳しく説明することを楽しみにしています。近日公開予定の MobileNet-V5 テクニカル レポートで、モデルのアーキテクチャ、データ スケーリング戦略、高度な蒸留手法について詳細に説明します。
最初の日から Gemma 3n を利用できるようにすることが優先事項でした。私たちは、多くのすばらしいオープンソース デベロッパーと連携して、AMD、Axolotl、Docker、Hugging Face、llama.cpp、LMStudio、MLX、NVIDIA、Ollama、RedHat、SGLang、Unsloth、vLLM などのチームからの貢献を含め、人気のツールやプラットフォームで幅広くサポートされるようにしています。これは私たちの誇りです。
しかし、このエコシステムは開始点に過ぎません。この技術が真の力を発揮するのは、皆さんがこれを使って開発するときです。そこで、Gemma 3n Impact Challenge を開催します。Gemma 3n ならではのオンデバイス、オフライン、マルチモーダル機能を使って、世界を進化させる作品を開発してください。賞金は 15 万ドルです。私たちは、魅力的な動画ストーリーと、現実世界にインパクトを与える「すごい」デモを求めています。チャレンジに参加して、より良い未来を築きましょう。
さっそく Gemma 3n の可能性を探ってみたい方は、次の方法をお試しください。



