

Gemma は最先端かつ軽量のオープンモデル ファミリーで、Gemini モデルと同じ研究技術で構築されています。
Gemma にはさまざまなバリエーションがあり、次のようなさまざまなユースケースやモダリティに対応できるように設計されています。
どのモデルも同じ DNA を共有しているため、Gemma ファミリーは、現在の LLM システムで使われるさまざまなアーキテクチャやデザインについて学ぶうえで、格好の題材となります。この投稿が、オープンモデル エコシステムのさらなる活性化と、LLM システムの動作の深い理解につながれば幸いです。
このシリーズでは、以下について説明します。
このシリーズでは、以下の内容を扱います。
モデルに関する情報を提供する際は、Hugging Face Transformers のモデルを print で出力します。次に簡単なコードを示します。
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
print(model)モデルの内部を調べたい場合は、Keras の Model クラスの API である torchinfo や summary() を使うこともできます。
このガイドは AI を紹介するものではありません。ニューラル ネットワークやトランスフォーマー、そしてそれに関連するトークンなどの用語について、実用的な知識を持っている方を対象としています。これらの概念についての復習が必要な方は、以下のリソースをご覧ください。
ブラウザで動作する実践的なニューラル ネットワーク学習ツール
トランスフォーマー入門
Gemma は重みが公開されている LLM です。インストラクション チューニング版と基本モデルのそれぞれに、異なるパラメータ サイズのトレーニング済みバリアントがあります。ベースとなっているのは、Google Research が Attention Is All You Need という論文で紹介した LLM アーキテクチャです。主な機能として、ユーザーが提供するプロンプトに基づくトークン単位でのテキスト生成が挙げられます。翻訳のようなタスクでは、Gemma はある言語の文を入力として受け取り、同等の文を別の言語で出力します。
すぐにおわかりいただけると思いますが、Gemma はそれ自体が優れたモデルであるだけでなく、さまざまなユーザーのニーズを満たすカスタム拡張機能も持ち合わせています。
まず、Gemma モデルのベースとなっているトランスフォーマー デコーダーに注目しましょう。
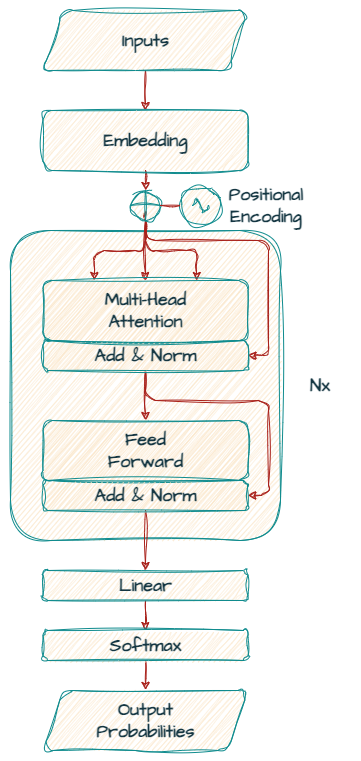
もともと「Attention Is All You Need」で触れられていたのは、エンコーダ - デコーダ トランスフォーマー モデル アーキテクチャでしたが、Gemma は「デコーダのみ」のモデルです。
このアーキテクチャのコアパラメータを次の表にまとめます。
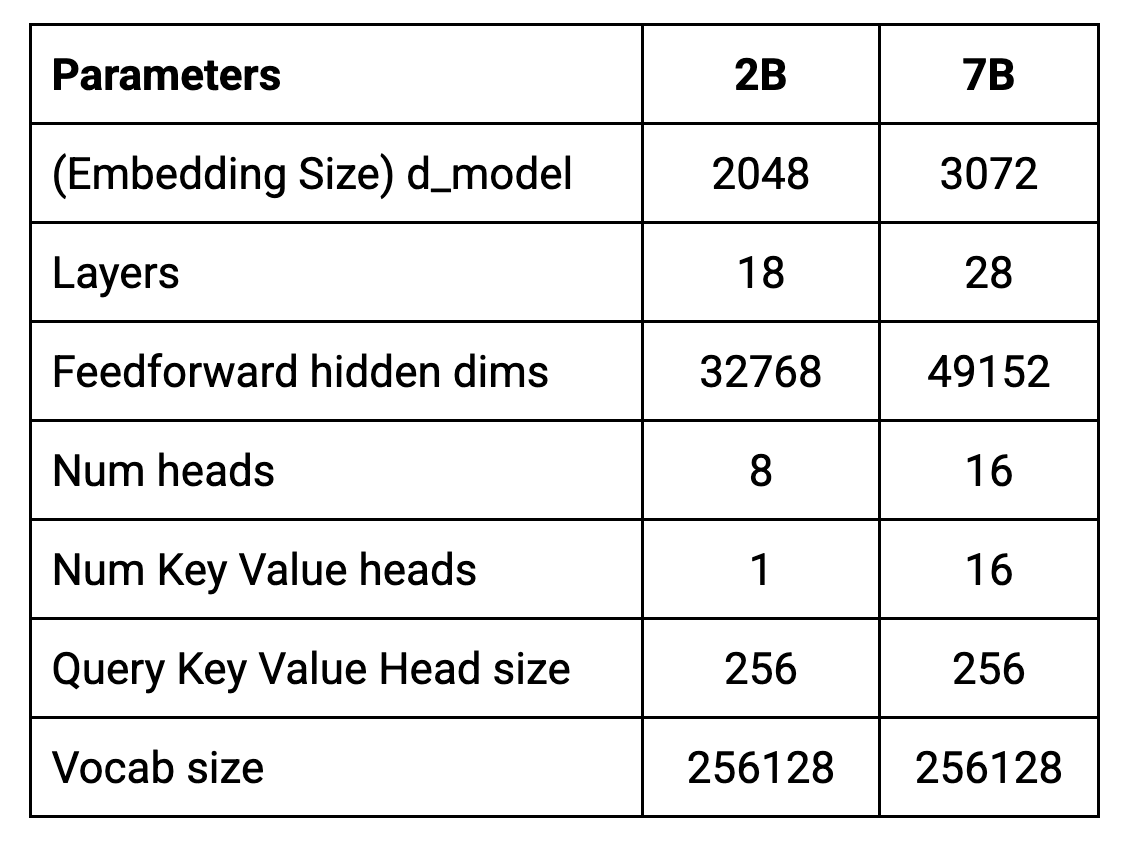
モデルのトレーニングは、8192 トークンのコンテキスト長で行います。つまり、最大で一度に約 6144 ワード(経験則によれば、100 トークンは約 75 ワード)を処理できることになります。
実際の入力の上限値は、タスクや用法によって異なる可能性があることに注意しましょう。つまり、生成されたテキストもコンテキスト ウィンドウのトークンを消費するので、実質的に新しい入力に利用できる領域が減ることになります。厳密な意味での入力の上限値は一定ですが、生成された出力が後続の入力の一部となるので、以降の生成に影響することになります。
d_model は、デコーダへの入力に使う埋め込み(単語またはサブワード、すなわちトークンのベクトル表現)のサイズを表します。デコーダレイヤの内部表現のサイズも、これによって決まります。
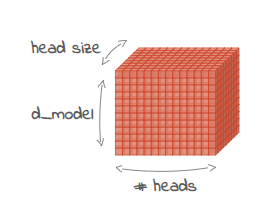
d_model 値が大きくなるほど、モデルがさまざまな単語のニュアンスとその関係を表現できる「余地」が増えることになり、とりわけ複雑な言語タスクでパフォーマンスが向上する可能性があります。しかしながら、d_model が大きくなると、モデルも大きくなり、トレーニングや利用に必要な計算量も増えることになります。
トランスフォーマーは、複数のレイヤを積み重ねた構造になっています。深いモデルにはそれだけ多くのレイヤがあるので、パラメータの数も多くなり、複雑なパターンを学べるようになります。ただし、パラメータ数が増えると過学習が起こりやすくなり、必要な計算リソースも増加します。
モデルの表現力が向上すると、ノイズやトレーニング データの特定のパターンを学習し、汎用化して新しい例に対応する能力が低下する場合もあります。
さらに、多くの場合は、モデルが深くなるほど、過学習を回避するためにトレーニング データを増やさなければならなくなります。利用できるデータが限られている場合、十分なサンプルがないために汎用表現を学習することができず、トレーニング データを覚えるだけになってしまうこともあります。
トランスフォーマーの各レイヤには、アテンション メカニズムの後にフィードフォワード ネットワークが含まれています。このネットワークには独自の次元があります。モデルの表現力を高めるため、ほとんどの場合は d_model よりも大きなサイズになっています。
これは、ニューラル ネットワークの一種である多層パーセプトロン(MLP)として実装されています。多層パーセプトロンは、埋め込みを再変換し、さらに複雑なパターンを抽出します。
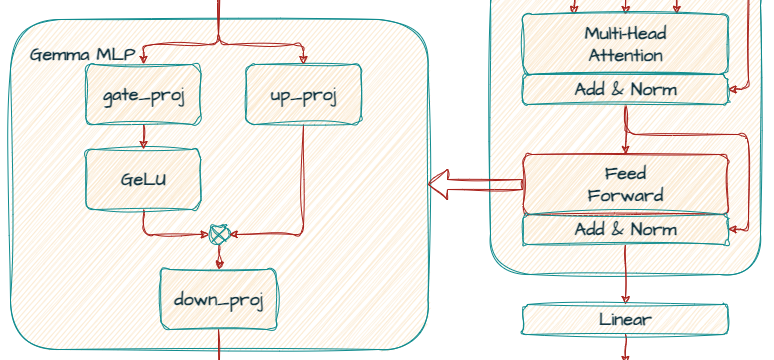
Gemma では、標準的な ReLU 非線形関数の代わりに、GeGLU 活性化関数が使われています。GeGLU は GLU(ゲート リニア ユニット)の一種で、活性化をシグモイド部分と線形射影という 2 つの部分に分割しています。シグモイド部分の出力を要素ごとに線形射影と掛け合せることで、非線形活性化関数が得られます。
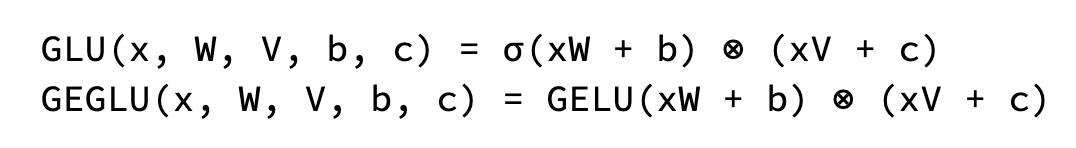
トランスフォーマーの各レイヤには、並列に動作する複数のアテンション メカニズムが含まれています。これを「ヘッド」と言い、これによってモデルが入力シーケンスの異なる特徴に同時に注目することができます。ヘッドの数を増やせば、モデルがデータの多様な関係を理解できるようになります。
7B モデルはマルチヘッド アテンション(MHA)を、2B モデルはマルチクエリ アテンション(MQA)を利用します。MQA では、同じキーと値の射影が共有されます。つまり、各ヘッドは同じ基礎表現に注目しますが、クエリの射影は異なります。
オリジナルの MHA の方が高度な特徴表現学習が可能ですが、計算コストは高くなります。MQA は効率的な代替手段を提供します。この手法の効率性は証明されています。
マルチヘッド アテンション機構の各アテンション ヘッドの次元を表します。埋め込みの次元数をヘッド数で割って計算します。たとえば、埋め込み次元数が 2048、ヘッド数が 8 の場合、各ヘッドのサイズは 256 になります。
モデルが理解および処理できる固有のトークン(単語、サブワード、文字のいずれか)数を定義します。Gemma のトークナイザーは、SentencePiece がベースになっています。語彙のサイズは、トレーニング前にあらかじめ決められています。SentencePiece は、選択された語彙サイズとトレーニング データに基づいて、最適なサブワード分割を学習します。Gemma の語彙は大きく、256k のサイズなので、多様なテキスト入力を処理でき、多言語テキスト入力の処理などのさまざまなタスクのパフォーマンスが向上する可能性があります。
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)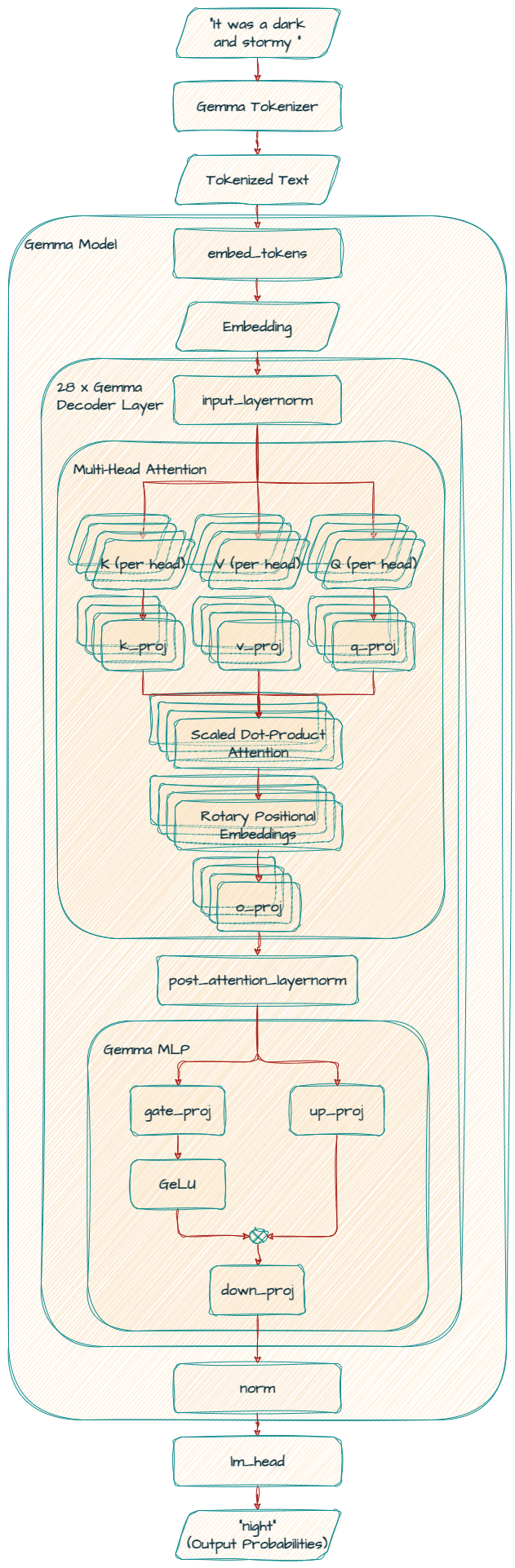
このレイヤは、入力トークン(単語またはサブワード)を、モデルが処理できる高密度数値表現(埋め込み)に変換します。語彙サイズは 256,000 で、3072 次元の埋め込みが作成されます。
これはモデルの中核で、28 層の GemmaDecoderLayer ブロックを積み重ねたものです。各レイヤでトークン埋め込みを処理し、単語とそのコンテキストとの間の複雑な関係を理解します。
セルフアテンション メカニズムでは、入力ワードに異なる重みを割り当てることで、次の単語を生成します。モデルは、スケーリング ドット積アテンション メカニズムと線形射影(q_proj、k_proj、v_proj、o_proj)を使って、クエリ、キー、値、出力表現を生成します。
このモデルはマルチヘッド アテンション(MHA)を使うため、q_proj、k_proj、v_proj のすべての out_features 値は同じ 4096 です。サイズ 256 のヘッド 16 個が並列に動作するので、合計の数は 4096 個(256 x 16)になります。
さらにモデルは、位置エンコーディング(別名 RoPE)に rotary_emb(GemmaRotaryEmbedding)を使うことで、位置情報を有効活用しています。
最後に o_proj レイヤで、アテンション出力を元の次元(3072)に射影します。
Gemma 2B モデルは、マルチクエリ アテンション(MQA)を使っていることに注意してください。
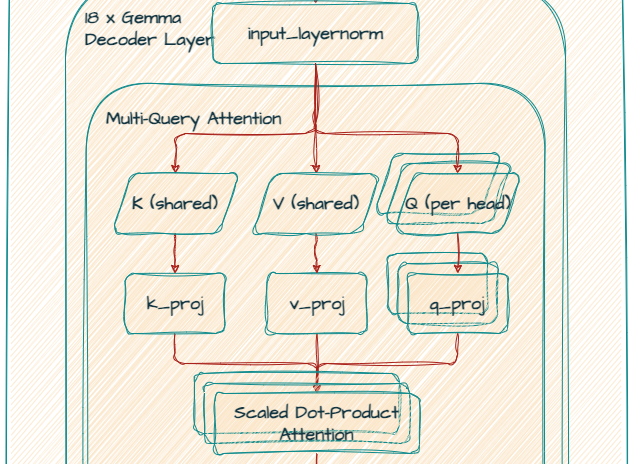
k_proj と v_proj は、サイズ 256 の同じヘッドを共有するため、out_features は 256 になります。対照的に、q_proj と o_proj には、並列に動作する 8 つのヘッドがあります(256 x 8 = 2048)。
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)ゲート メカニズムに gate_proj と up_proj を利用し、その後、down_proj を使って次元を減らし、3072 に戻します。
これらの正規化レイヤにより、トレーニングが安定し、モデルが効果的に学習できるようになります。
この最終レイヤで、処理済みの埋め込み(3072)を、語彙空間(256000)における次のトークンの確率分布にマッピングします。
CodeGemma モデルは、コード補完とチャットによるコーディング支援向けに最適化したファイン チューニング済み Gemma モデルです。CodeGemma モデルは、5,000 億以上の主要コードのトークンでトレーニングしています。さらに、CodeGemma にはフィルインザミドル(FIM)機能が追加されており、2 つの既存テキスト間で補完を行うことができます。
CodeGemma からわかるのは、Gemma チェックポイントのファイン チューニング能力です。追加のトレーニングを行うことで、モデルを特定のタスクに特化させて、最後尾の補完にとどまらない複雑な補完を学習させることができます。
4 つのユーザー定義トークンを利用できます。FIM 用に 3 つのトークン、マルチファイル コンテキスト サポート用に "<|file_separator|>" トークンを利用できます。
BEFORE_CURSOR = "<|fim_prefix|>"
AFTER_CURSOR = "<|fim_suffix|>"
AT_CURSOR = "<|fim_middle|>"
FILE_SEPARATOR = "<|file_separator|>"次の画面のようなコード補完について考えてみましょう。
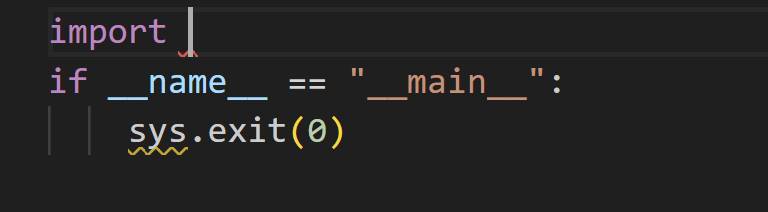
入力プロンプトは次のようになります。
<|fim_prefix|>import <|fim_suffix|>if __name__ == "__main__":\n sys.exit(0)<|fim_middle|>モデルは、コード補完の候補として「sys」を提示します。
CodeGemma の詳細については、CodeGemma / クイックスタートをご覧ください。
この記事では、Gemma のアーキテクチャについて説明しました。
次回以降の投稿では、最新モデルである Gemma 2 について説明します。安全対策が大幅に強化されており、推論時のパフォーマンスと効率の面で前のモデルを凌駕しています。
今後の投稿にご期待ください。お読みいただきありがとうございました。
Gemma
CodeGemma

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules
Coral NPU のご紹介: エッジ AI 向けフルスタック プラットフォーム

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX