

Gemma는 Gemini 모델을 만드는 데 사용된 것과 동일한 연구와 기술로 제작된 경량의 최첨단 개방형 모델 제품군입니다.
Gemma의 다양한 변형은 다음과 같은 다양한 사용 사례와 형식에 맞게 설계되었습니다.
이 모든 모델은 그 태생부터 유사한 DNA를 공유하는 셈이므로, Gemma 제품군은 최신 LLM 시스템에서 사용할 수 있는 아키텍처 및 설계 선택 사항에 대해 알아볼 수 있는 독특한 방식을 제공합니다. 이를 통해 개방형 모델의 풍부한 생태계에 기여하고 LLM 시스템의 작동 방식에 대한 이해를 더욱 증진할 수 있기를 바랍니다.
이 시리즈에서는 다음 내용을 다룹니다.
이 시리즈의 내용은 다음과 같습니다.
모델에 대한 정보를 제공하기 위해 아래의 간단한 코드와 같이 Hugging Face Transformers 인쇄 모듈을 사용합니다.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
print(model)Keras Model 클래스 API에서도 torchinfo 또는 summary()를 사용하여 모델 내부를 탐색할 수 있습니다.
이 가이드는 AI 입문서는 아닙니다. 독자가 이미 신경망, Transformer, 관련 용어(예: 토큰)에 대한 실무 지식이 있는 것으로 가정하고 기술합니다. 이러한 개념에 대한 복습이 필요한 분을 위해 시작하는 데 도움이 되는 몇 가지 자료를 아래와 같이 안내해 드립니다.
브라우저에서 작동하는 실습용 신경망 학습 도구
Transformer 개론
Gemma는 가중치가 공개된 LLM입니다. 다양한 매개변수 크기에서 명령 튜닝 변이와 사전 학습된 원시 변이로 모두 제공됩니다. Gemma는 Attention Is All You Need라는 제하의 논문에서 Google 연구팀에서 소개한 LLM 아키텍처를 기반으로 합니다. Gemma의 일차적 기능은 사용자가 제공한 프롬프트를 기반으로 토큰워드 단위로 텍스트를 생성하는 것입니다. 번역과 같은 작업에서 Gemma는 한 언어의 문장을 입력으로 받아 그에 해당하는 문장을 다른 언어로 출력합니다.
곧 보시게 될 일이지만, Gemma는 그 자체로도 훌륭한 모델이지만 다양한 사용자 니즈에 부응하고자 사용자 설정 확장에도 적합합니다.
먼저 Gemma 모델이 기반으로 하는 Transformer 디코더를 살펴보겠습니다.
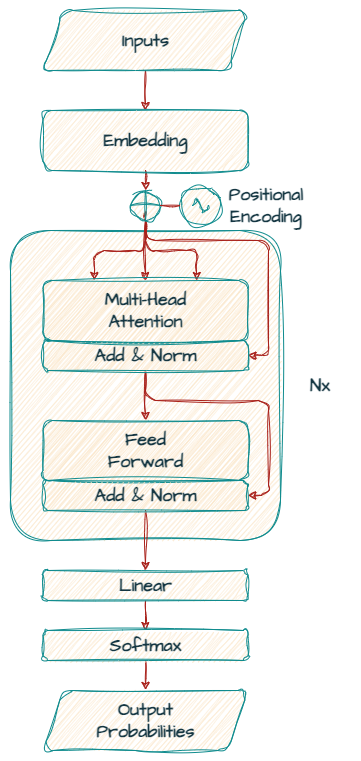
'Attention Is All You Need'에 소개된 원래의 인코더-디코더 트랜스포머 모델 아키텍처와 달리, Gemma는 전적으로 '디코더 전용' 모델입니다.
이 아키텍처의 핵심 매개변수가 아래 표에 요약되어 있습니다.
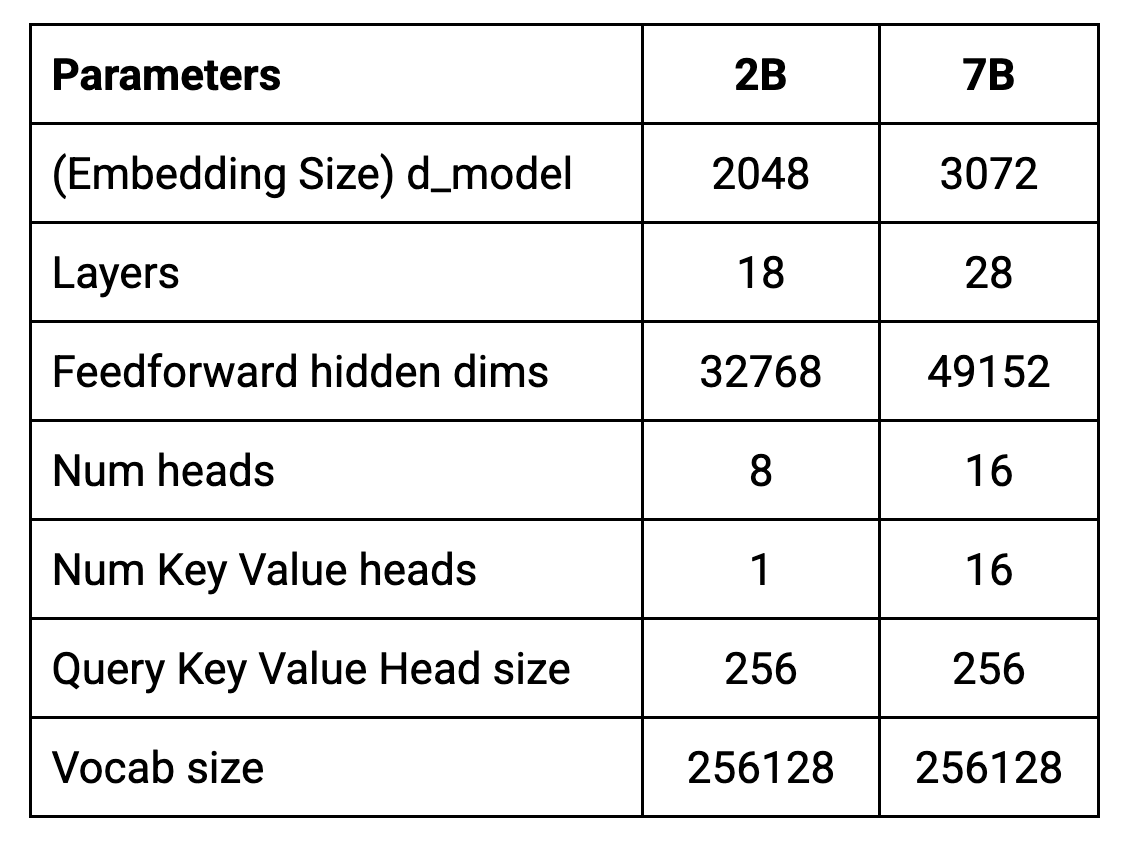
모델은 토큰 8192개의 컨텍스트 길이로 학습됩니다. 즉, 한 번에 최대 약 6,144개의 단어(100개의 토큰은 대략 75단어와 같다는 경험칙 사용)를 처리할 수 있습니다.
실제 입력 제한은 작업과 사용량에 따라 달라질 수 있다는 점도 강조합니다. 이는 텍스트 생성 시 컨텍스트 창 내에서 토큰을 소비하여 새로운 입력을 위한 공간이 사실상 감소하기 때문입니다. 기술적 입력 제한은 일정하게 유지되지만 생성된 출력은 후속 입력의 일부가 되어 추가적인 생성에 영향을 미칩니다.
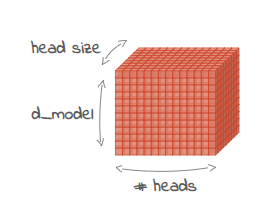
d_model은 디코더에 입력으로 사용되는 임베딩(단어 또는 하위 단어의 벡터 표현으로, 토큰이라고도 함)의 크기를 나타냅니다. 또한 이에 따라 디코더 레이어 내의 내부 표현 크기가 결정됩니다.
d_model 값이 클수록 모델이 다른 단어의 뉘앙스와 그 관계를 나타내는 '공간'이 더 많아집니다. 이는 특히 복잡한 언어 작업의 경우 더 나은 성능으로 이어질 수 있습니다. 그러나 d_model이 증가하면 모델이 더 커지고 학습과 사용에 더 많은 계산 비용이 들기도 합니다.
Transformer는 여러 스택으로 구성된 레이어로 이루어집니다. 심층적 모델일수록 레이어도 더 많고, 따라서 매개변수도 더 많으며 더 복잡한 패턴을 학습할 수 있습니다. 그러나 이러한 추가 매개변수는 과적합이 되기 쉽고 더 많은 계산 리소스가 필요함을 의미하기도 합니다.
이처럼 증강된 표현 능력은 모델 학습 노이즈 또는 새로운 예로 일반화할 수 있는 능력이 결여된 특정 학습 데이터 패턴을 초래할 수 있습니다.
또한 더욱 심층적인 모델에는 과적합 방지를 위해 더 많은 학습 데이터가 필요한 경우가 많습니다. 사용 가능한 데이터가 제한적인 경우, 모델은 일반화할 수 있는 표현을 학습하기에 충분한 예가 부족한 바람에 대신에 학습 데이터를 기억해버리는 결과로 이어질 수 있습니다.
각 Transformer 레이어는 어텐션 메커니즘 뒤에 피드포워드 네트워크를 포함합니다. 이 네트워크는 고유의 차원수를 갖는데, 모델의 표현력 증대를 위해 d_model 크기보다 큰 경우가 많습니다.
이 네트워크는 임베딩을 추가로 변환하고 더 복잡한 패턴을 추출하기 위해 일종의 신경망인 MLP(Multi-Layer Perceptron)로 구현됩니다.
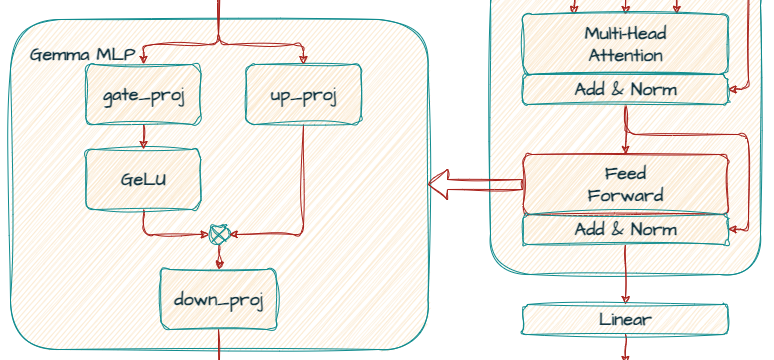
Gemma에서 표준 ReLU 비선형성은 GLU(Gate Linear Unit)의 변형인 GeGLU 활성화 함수로 대체됩니다. GeGLU는 활성화를 S자형 부분과 선형 투영 부분의 두 부분으로 나눕니다. S자형 부분의 출력은 원소 단위로 선형 투영과 곱해져 비선형 활성화 함수가 됩니다.
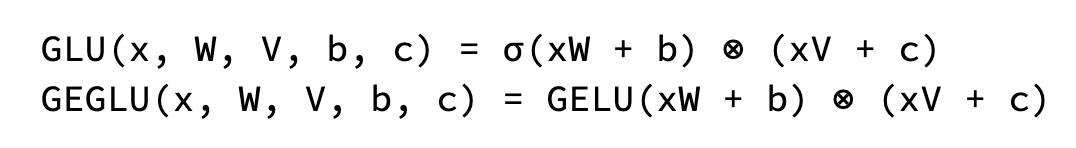
각 Transformer 레이어에는 병렬로 작동하는 여러 어텐션 메커니즘이 포함됩니다. 이러한 '헤드'를 통해 모델은 입력 시퀀스의 다양한 측면에 동시에 집중할 수 있습니다. 헤드 수를 늘리면 모델이 데이터에서 다양한 관계를 캡처하는 능력을 향상할 수 있습니다.
7B 모델은 다중 헤드 어텐션(MHA)을 사용하는 반면, 2B 모델은 다중 쿼리 어텐션(MQA)을 사용합니다. MQA는 동일한 키 및 값 예측을 공유하는데, 이는 곧 각 헤드가 동일한 기본 표현에 초점을 맞추지만 쿼리 예측은 서로 다르다는 의미입니다.
원래 MHA는 더 풍부한 표현 학습을 제공하지만 더 비싼 계산 비용이 수반됩니다. MQA는 효과적인 것으로 입증된 효율적인 대안을 제공합니다.
이는 다중 헤드 어텐션 메커니즘 내의 각 어텐션 헤드의 차원수를 가리킵니다. 임베딩 차원을 헤드 수로 나누어 계산합니다. 예를 들어, 임베딩 차원이 2048이고 헤드가 8개인 경우 각 헤드의 크기는 256이 됩니다.
모델이 이해하고 처리할 수 있는 고유 토큰(단어, 하위 단어 또는 문자)의 수를 정의하는 매개변수입니다. Gemma 토크나이저는 SentencePiece를 기반으로 합니다. 어휘의 크기는 학습 전에 미리 결정됩니다. 그런 다음 SentencePiece는 선택한 어휘 크기와 학습 데이터를 기반으로 최적의 하위 단어 세분화를 학습합니다. 256,000개에 달하는 Gemma의 대형 어휘 집합을 사용하면 다양한 텍스트 입력을 처리하고 다국어 텍스트 입력 처리 등의 다양한 작업에 대한 성능을 잠재적으로 개선할 수 있습니다.
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)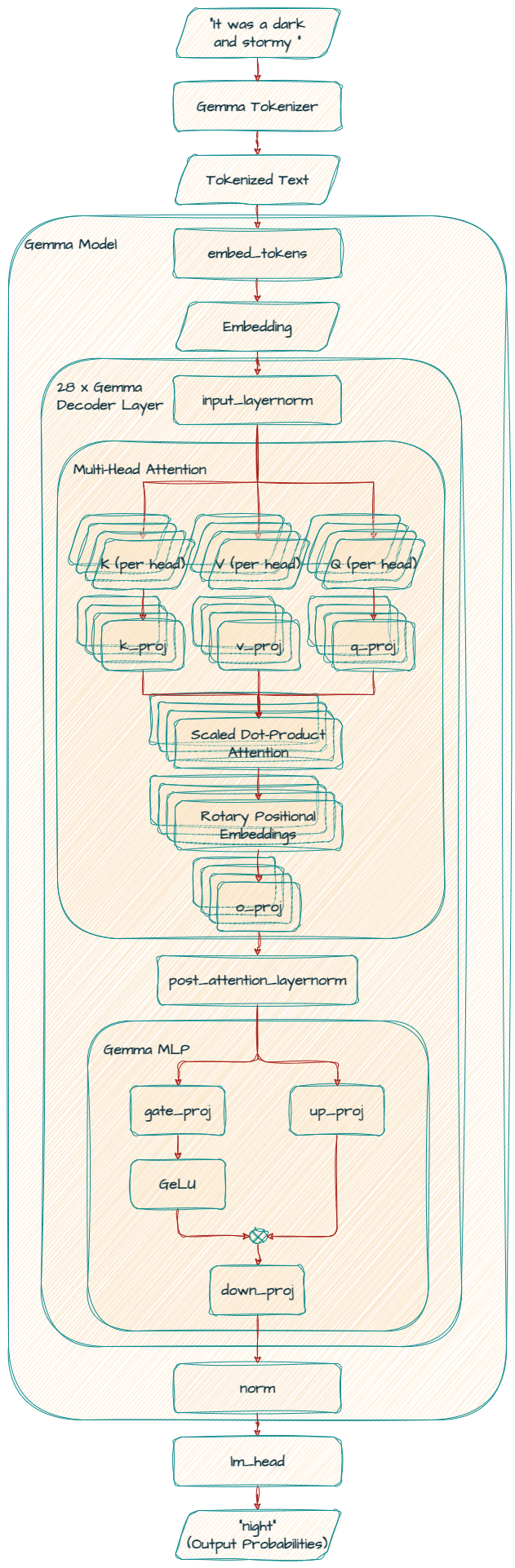
이 레이어는 입력 토큰(단어 또는 하위 단어)을 모델이 처리할 수 있는 치밀한 숫자 표현(임베딩)으로 변환합니다. 어휘 크기는 256,000개이며 차원수가 3072인 임베딩을 생성합니다.
레이어는 28개 스택이 쌓인 GemmaDecoderLayer 블록으로 구성된 모델의 핵심입니다. 이러한 각 레이어는 단어와 컨텍스트 간의 복잡한 관계를 포착하기 위해 토큰 임베딩을 구체화합니다.
셀프 어텐션 메커니즘에서 모델은 다음 단어를 만들 때 입력에 있는 단어에 다른 가중치를 할당합니다. 모델은 조정된 내적 어텐션 메커니즘을 활용하여 선형 투영(q_proj, k_proj, v_proj, o_proj)을 사용하여 쿼리, 키, 값 및 출력 표현을 생성합니다.
이 모델은 MHA(Multi Head Attention)를 사용하므로 모든 out_features 값은 q_proj, k_proj, v_proj에 대해 똑같이 4096입니다. 이들은 병렬로 256의 크기를 가진 16개의 헤드를 가지고 있으며, 총 4096(256 x 16)입니다.
또한 이 모델은 위치 인코딩에 rotary_emb(GemmaRotaryEmbedding)를 사용하여(RoPE라고도 함) 위치 정보를 보다 효과적으로 활용합니다.
마지막으로, o_proj 레이어는 어텐션 출력을 원래 차원(3072)으로 다시 투영합니다.
Gemma 2B 모델은 MQA(Multi Query Attention)를 사용합니다.
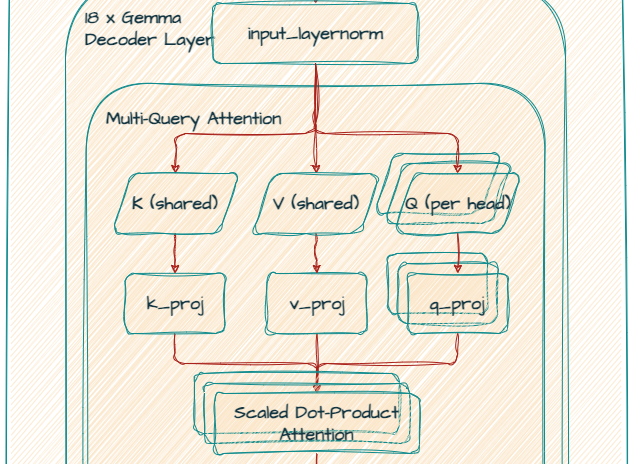
k_proj와 v_proj는 256의 크기를 가진 동일한 헤드를 공유하여 out_features가 256이 됩니다. 반면에, q_proj와 o_proj는 8개의 헤드(256 x 8 = 2048)를 병렬로 갖습니다.
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)mlp는 게이팅 메커니즘에 대해 gate_proj와 up_proj를 활용한 다음 down_proj를 활용하여 차원을 다시 3072로 줄입니다.
이러한 정규화 레이어는 학습을 안정화하고 모델의 효과적인 학습 능력을 향상시킵니다.
이 마지막 레이어는 미세 조정된 임베딩(3072)을 어휘 공간(256000)을 통해 다음 토큰에 대한 확률 분포로 다시 매핑합니다.
CodeGemma 모델은 코드 완성 및 코딩 채팅 지원에 최적화하여 미세 조정한 Gemma 모델입니다. CodeGemma 모델은 주로 코드의 5,000억 개 이상 토큰에 대해 학습됩니다. 또한 CodeGemma는 중간을 채우는 기능을 추가하여 기존 텍스트의 두 부분 사이에 발생하는 완료를 허용합니다.
CodeGemma는 Gemma 체크포인트의 미세 조정 가능성을 강조합니다. 추가 학습을 통해 모델은 특정 작업에서 전문화되어 순수한 접미사 완성보다 더 복잡한 완성을 학습합니다.
4개의 사용자 정의 토큰(FIM의 경우 3개, 다중 파일 컨텍스트 지원의 경우 '<|file_separator|>'개의 토큰)을 사용할 수 있습니다.
BEFORE_CURSOR = "<|fim_prefix|>"
AFTER_CURSOR = "<|fim_suffix|>"
AT_CURSOR = "<|fim_middle|>"
FILE_SEPARATOR = "<|file_separator|>"아래 화면과 같은 코드를 완성하려는 경우를 생각해 보세요.
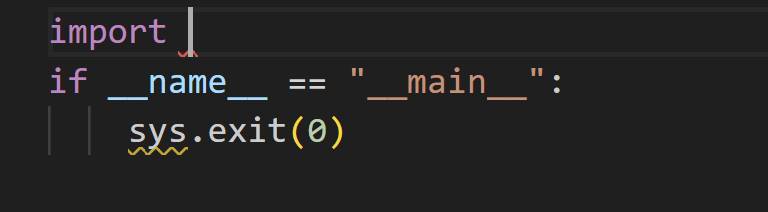
입력 프롬프트는 다음과 같아야 합니다.
<|fim_prefix|>import <|fim_suffix|>if __name__ == "__main__":\n sys.exit(0)<|fim_middle|>모델은 제안된 코드 완성으로 'sys'를 제공합니다.
CodeGemma / Quickstart에서 CodeGemma에 대해 자세히 알아볼 수 있습니다.
이 기사에서는 Gemma 아키텍처에 대해 설명했습니다.
다음 게시물 시리즈에서는 최신 모델인 Gemma 2를 살펴보겠습니다. 안전 조치가 상당히 향상됨에 따라, 이 모델은 추론 중에 성능과 효율성 측면에서 이전 모델을 능가합니다.
계속 지켜봐 주시고 끝까지 읽어주셔서 감사합니다!
Gemma
CodeGemma

Announcing the Data Commons Gemini CLI extension

EmbeddingGemma 출시: 온디바이스 임베딩을 위한 동급 최고의 개방형 모델
Coral NPU 소개: Edge AI를 위한 풀 스택 플랫폼

Gemma 3 270M 소개: 초효율적인 AI를 위한 콤팩트 모델

Building with Gemini 3 in Jules

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX