

今回 EmbeddingGemma をご紹介できることを嬉しく思います。EmbeddingGemma はそのサイズにおいてクラス最高のパフォーマンスを発揮する新しいオープン埋め込みモデルです。オンデバイス AI 専用に設計された高効率の 3 億 800 万パラメータ設計により、ハードウェア上で直接実行される検索拡張生成(RAG)やセマンティック検索などの手法を活用したアプリケーションを構築できます。インターネット接続がなくてもどこでも動作する、プライベートで高品質な埋め込みを実現します。
Link to Youtube Video (visible only when JS is disabled)
EmbeddingGemma は埋め込みを生成します。埋め込みとは数値表現であり、この例ではテキスト(文やドキュメントなど)を高次元空間で意味を表現するために数値ベクトルに変換したものです。埋め込みの質が優れているほど、ニュアンスや複雑さを含めた言語の表現が向上します。
RAG パイプラインをビルドする際には、ユーザーの入力に基づいて関連するコンテキストを取得し、そのコンテキストに基づいて回答を生成するという 2 つの重要な段階があります。取得を実行するには、ユーザーのプロンプトの埋め込みを生成し、システム上の全ドキュメントの埋め込みとの類似度を計算します。これにより、ユーザーのクエリに最も関連性の高い文章を取得できます。次に、これらの文章が元のユーザークエリとともに Gemma 3 などの生成モデルに渡され、文脈に沿った回答(例: 損傷した床板を修理するために大工の電話番号が必要だと理解できる)が生成されます。
この RAG パイプラインを効果的に機能させるには、最初の取得ステップの品質が極めて重要です。埋め込みの質が低いと、関連性のないドキュメントが取得され、不正確または意味をなさない回答につながります。EmbeddingGemma のパフォーマンスが真価を発揮するのはまさにこの点であり、正確で信頼性の高いオンデバイス アプリケーションに必要な高品質の表現を提供します。
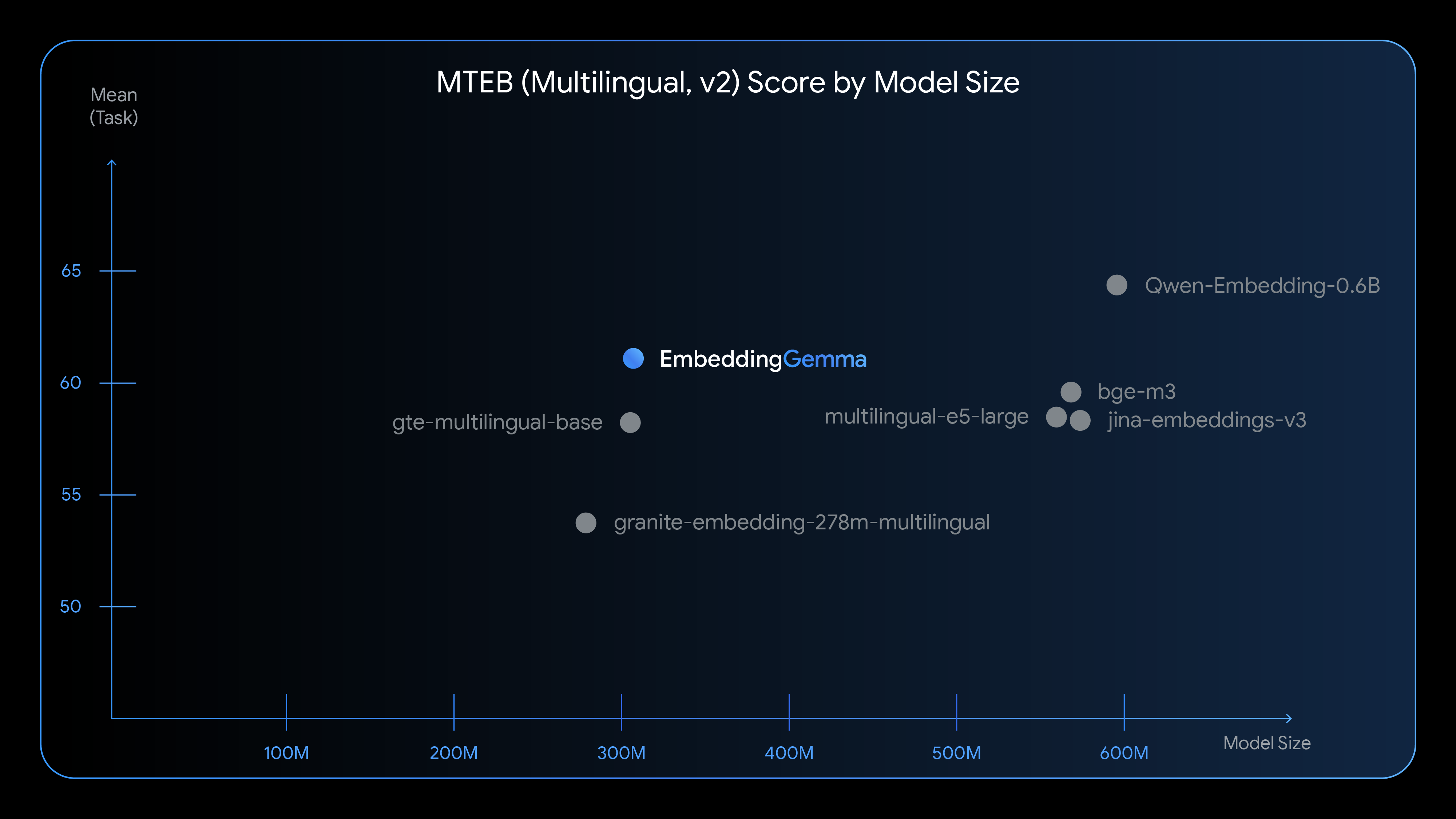
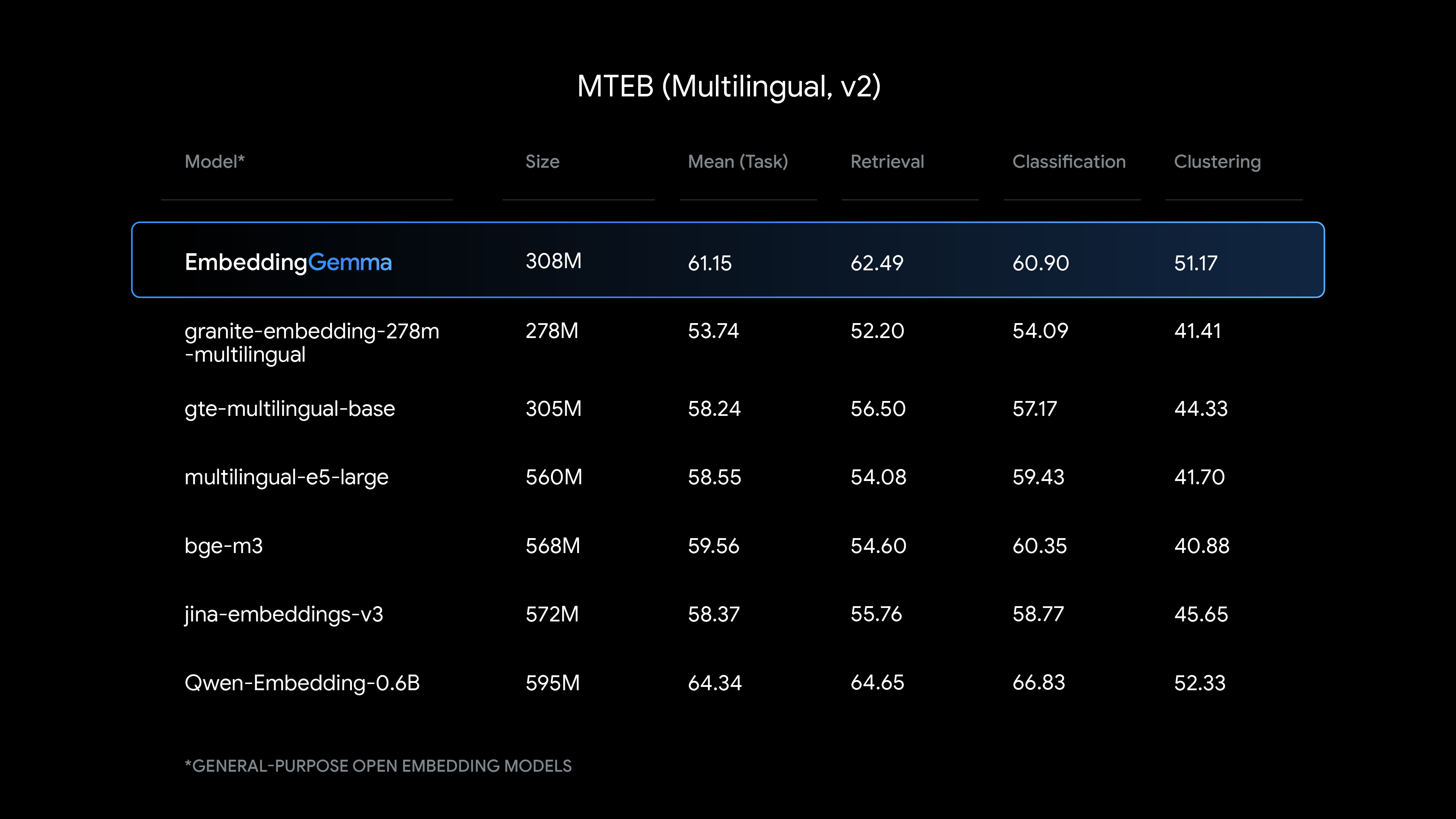
EmbeddingGemma は、そのサイズでは最新鋭のテキスト理解能力を提供し、特に多言語埋め込み生成において強力なパフォーマンスを発揮します。
EmbeddingGemma と他の一般的な埋め込みモデルとの比較をご覧ください。
この 3 億 800 万パラメータ モデルは、約 1 億のモデル パラメータと約 2 億の埋め込みパラメータで構成されており、パフォーマンスと最小限のリソース消費を追求して設計されています。
EmbeddingGemma を使用すると、デベロッパーは柔軟かつプライバシー重視のオンデバイス アプリケーションをビルドできます。デバイスのハードウェア上で直接ドキュメントの埋め込みが生成されるため、機密性の高いユーザーデータを確実に保護できます。テキスト処理には Gemma 3n と同じトークナイザーを採用しており、RAG アプリケーションのメモリ フットプリントを削減します。EmbeddingGemma を使用すると、次のような新機能を利用できます。
これらの例でカバーされていない場合は、クイックスタート ノートブックを使用して特定のドメイン、タスク、または言語向けに EmbeddingGemma をファインチューニングします。
私たちの目標は、お客様のニーズに最適なツールを提供することです。今回のリリースにより、あらゆるアプリケーション向けの埋め込みモデルが利用できるようになりました。
EmbeddingGemma については、リリース当初からアクセシビリティを最優先に考え、主要なプラットフォームやフレームワークでのサポートを可能にするためにデベロッパーの皆さんと連携してきました。Android をはじめとする Google の自社プラットフォーム エクスペリエンスを支えているテクノロジーと同じものを活用し、普段お使いのツールで今すぐビルドを開始していただけます。

Google AI Edge Gallery: 音声サポートが追加され Google Play で利用可能に

T5Gemma: エンコーダ-デコーダ Gemma モデルの新たなコレクション

Building with Gemini 3 in Jules

LiteRT-LM を活用した Chrome、Chromebook Plus、Google Pixel Watch でのオンデバイス生成 AI

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension