En las entradas anteriores de la serie “Todo sobre Gemma”, proporcionamos una descripción detallada de las arquitecturas de la familia de modelos Gemma. Aquí encontrarás enlaces a cada publicación:
En esta entrada, explorarás la nueva arquitectura de EmbeddingGemma y su receta. Para obtener una introducción de alto nivel, puedes leer este blog de presentación. Si quieres tener un panorama completo de la metodología, los experimentos y la evaluación, consulta el informe técnico completo. Empecemos.
¿Alguna vez te preguntaste cómo se entrenan las computadoras para interpretar el significado y el contexto de palabras, frases o incluso documentos completos? La magia suele estar relacionada con algo llamado “incorporaciones”, es decir, representaciones numéricas que capturan la esencia y el significado del texto. EmbeddingGemma es un modelo de incorporación que puede convertir texto en incorporaciones. Estas se pueden utilizar para tareas como la búsqueda, la recuperación, la generación aumentada y la comprensión.
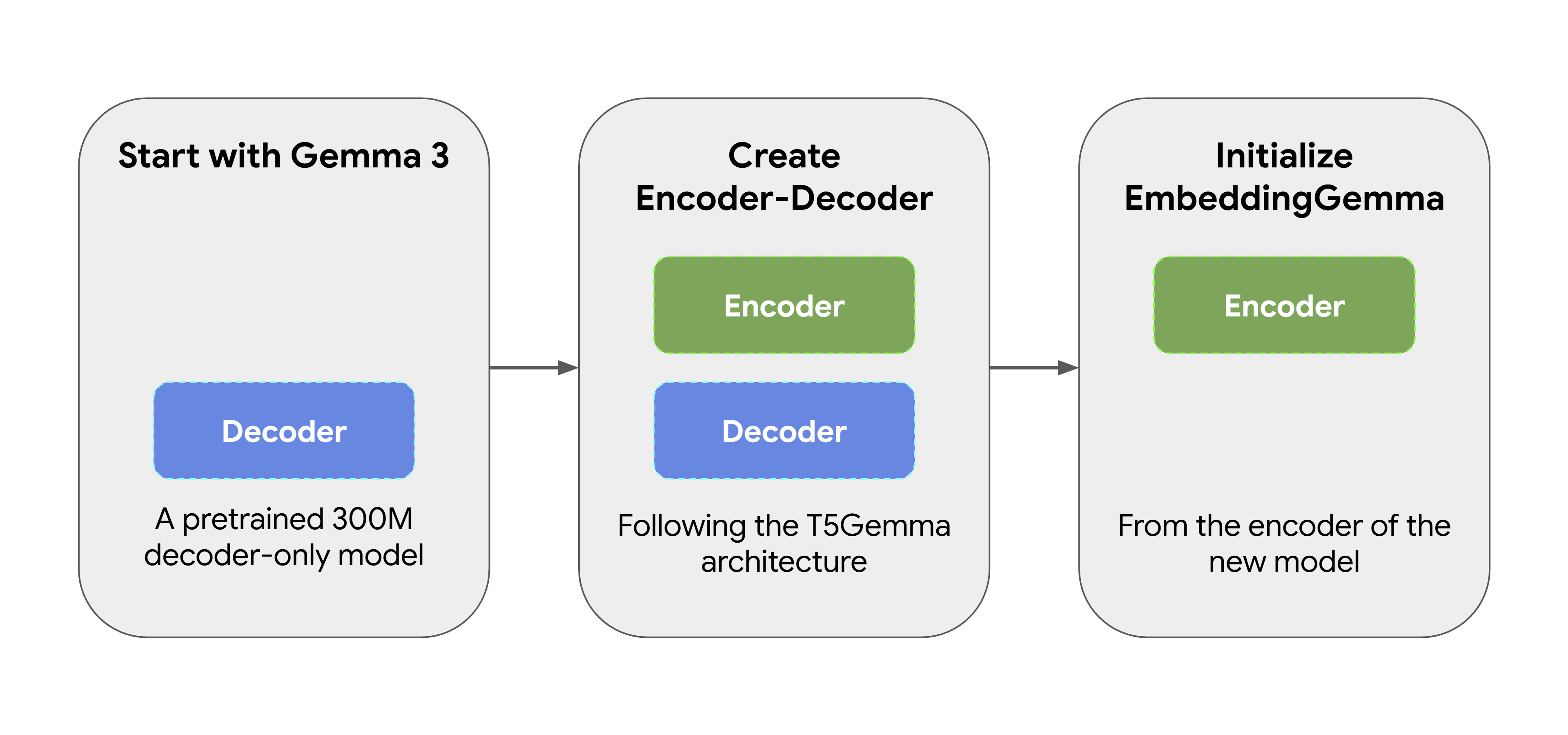
EmbeddingGemma no se creó desde cero. Comenzó como un modelo preentrenado Gemma 3 de 300 millones de parámetros. Luego, se lo transformó utilizando el método adaptación de T5Gemma, que convierte el modelo Gemma original solo para decodificador en una arquitectura de tipo codificador-decodificador. Más adelante, inicializamos EmbeddingGemma desde el codificador de este nuevo modelo, asegurándonos de que sea capaz de producir representaciones expresivas desde el principio. Este enfoque permite a EmbeddingGemma heredar una gran cantidad de “conocimiento mundial” de su predecesor sin tener que hacer entrenamiento adicional.
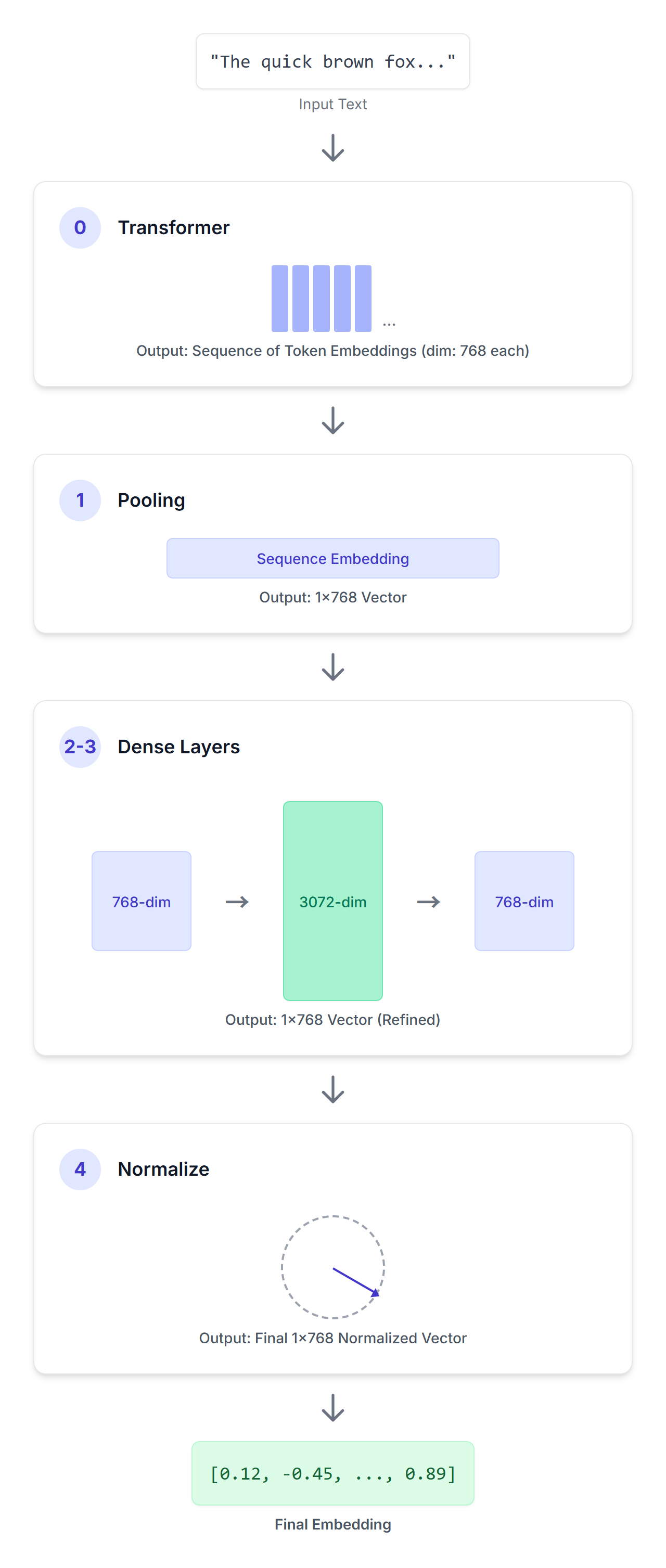
Puedes usar EmbeddingGemma para generar incorporaciones utilizando marcos de trabajo como los transformadores de oraciones. EmbeddingGemma procesa una secuencia determinada de entrada de texto a través de una serie de pasos cuidadosamente diseñados para producir una representación vectorial concisa.
SentenceTransformer(
(0): Transformador({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Agrupación({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Densidad({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Densidad({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalización()
)(0): Transformador
Una secuencia de entrada pasa a través de este modelo de transformador de solo codificador. Este transformador utiliza la atención bidireccional para comprender el significado de cada token en el contexto proporcionado, con lo que produce una secuencia de vectores de 768 dimensiones, uno para cada token de tu secuencia de entrada.
(1): Agrupación
El resultado del transformador es una secuencia de incorporaciones de tokens. La tarea de la capa de agrupación es convertir esta secuencia de longitud variable en una única incorporación de tamaño fijo para toda la entrada. EmbeddingGemma utiliza una estrategia de agrupación llamada “agrupación promedio”. Este es el enfoque más común, con el que se calcula el promedio de todas las incorporaciones de tokens.
(2): Densidad
A continuación, aplicamos una proyección lineal para escalar la incorporación (768) hasta una dimensión de incorporación más grande (3072).
(3): Densidad
Luego, aplicamos otra proyección lineal para escalar la incorporación aprendida de 3.072 dimensiones a la dimensión objetivo final (768).
(4): Normalización
Finalmente, aplicamos la normalización euclidiana, lo que permite hacer comparaciones de similitudes eficientes. Esta es una operación más simple y económica en comparación con RMSNorm, que es más compleja y tal vez recuerdes de otros modelos de Gemma.
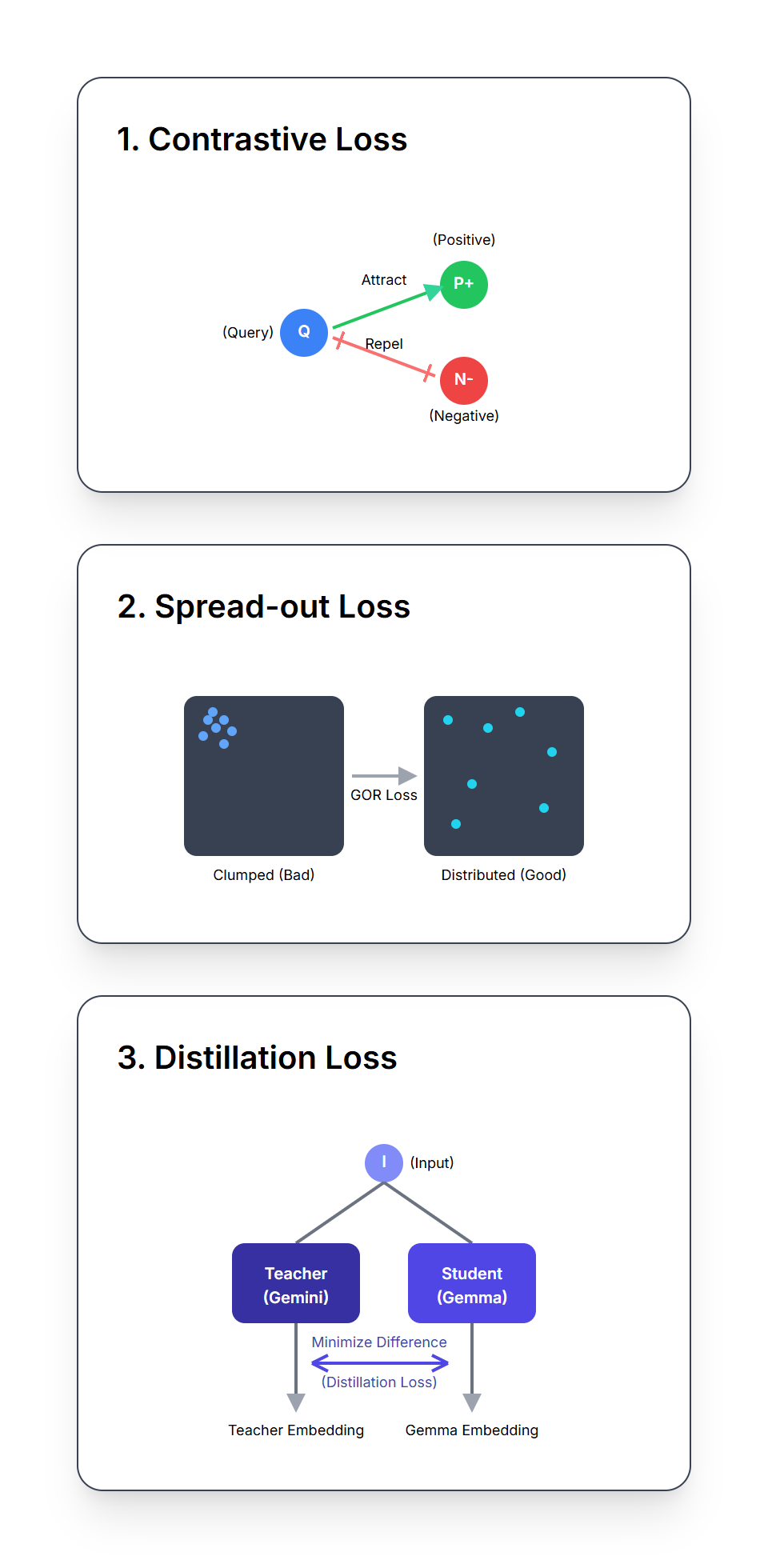
EmbeddingGemma aprende a crear sus potentes incorporaciones optimizando una combinación de tres funciones distintas de pérdida ponderada durante el entrenamiento.
La pérdida de NCE le enseña al modelo los conceptos fundamentales de similitud y contraste. Con cada entrada (p. ej., una consulta), aprende lo siguiente:
La clave es la inclusión de “negativos duros” (respuestas semánticamente similares a la consulta, pero incorrectas o incompletas). Cuando se entrena con estos ejemplos complicados, el modelo se ve obligado a aprender las distinciones sutiles y detalladas que separan las respuestas correctas de las casi correctas.
Es como construir una biblioteca bien organizada, donde los elementos relacionados se colocan cerca unos de otros, mientras que los elementos no relacionados se mantienen separados.
Esta pérdida se diseñó para alentar a EmbeddingGemma a producir incorporaciones que se extiendan por el espacio de incorporación. Incluso si el modelo aprendiera a separar cosas similares y diferentes, igual podría volverse perezoso y simplemente apilar todas las incorporaciones en un mismo rincón pequeño.
Este regularizador hace que las incorporaciones sean sólidas para la cuantificación y permite una búsqueda eficiente en bases de datos vectoriales utilizando algoritmos de vecino más próximos.
Esta pérdida sirve como una forma de destilación de conocimiento, con la que EmbeddingGemma aprende de un modelo más grande y poderoso de incorporación de Gemini, que funciona como maestro.
La pérdida minimiza la distancia euclidiana (una medida de la diferencia) entre las incorporaciones de los dos modelos de incorporación para consultas y pasajes. Esto permite a EmbeddingGemma aprender del modelo maestro y heredar con eficacia gran parte de sus conocimientos y capacidades.
Al combinar estas tres funciones de pérdida, EmbeddingGemma aprende a producir representaciones bien estructuradas, expresivas y robustas, lo que permite obtener un rendimiento sólido en las tareas de búsqueda y recuperación del mundo real.
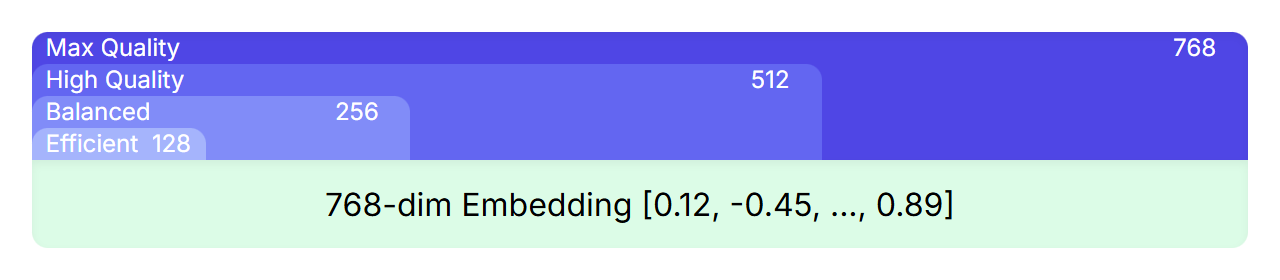
El MRL es una técnica que permite anidar representaciones más pequeñas y de alta calidad dentro de una más grande. Por ejemplo, aunque las incorporaciones de EmbeddingGemma tienen 768 dimensiones, puedes dividirlas y obtener otras más pequeñas con 512, 256 o incluso 128 dimensiones que conserven una calidad alta.
Durante el entrenamiento, las funciones de pérdida no solo se aplican a la incorporación final de 768 dimensiones, sino también a los subconjuntos superpuestos de esa incorporación (las primeras 512, 256 y 128 dimensiones). De esta manera, se garantiza que incluso una versión dividida de la incorporación completa sea una representación potente y completa.
En tu caso, esto significa que puedes elegir la compensación correcta entre rendimiento y eficiencia para tu aplicación, sin necesidad de entrenar o administrar múltiples modelos. Simplemente debes seleccionar el tamaño de incorporación que mejor se adapte a tus necesidades, desde las dimensiones 768 completas para obtener la máxima calidad hasta tamaños más pequeños para aumentar la velocidad y reducir los costos de almacenamiento.
El recorrido del modelo incluye varias etapas
Si se adapta cuidadosamente un modelo base potente y se lo refina con un enfoque de entrenamiento multifacético, la arquitectura de EmbeddingGemma es capaz de ofrecer representaciones de texto altamente eficaces y versátiles, adecuadas para una amplia variedad de aplicaciones.
Exploramos la arquitectura de EmbeddingGemma, un poderoso modelo para generar incorporaciones de texto. Aprendimos sobre los orígenes, el proceso de generación de incorporaciones y la receta de desarrollo. Si deseas profundizar en nuestra metodología de capacitación, nuestros puntos de referencia para evaluación y los resultados experimentales completos, te recomendamos que leas el informe técnico oficial.
Los modelos como EmbeddingGemma están marcando el camino hacia tecnologías semánticas más eficaces y potentes. A medida que estos modelos se vuelven más capaces y accesibles, podremos ver avances en varias áreas clave, como la Generación Aumentada de Recuperación (RAG), la IA en el dispositivo y la hiperpersonalización.
Encuentra los pesos del modelo en Hugging Face, Kaggle y Vertex AI, y comienza a experimentar hoy mismo.
¡Gracias por leer!