

The previous posts in the “Gemma explained” series provided a detailed overview of the Gemma model family's architectures. You can find links to each post below:
In this post, you will explore the new EmbeddingGemma’s architecture and its recipe. For a high-level introduction, you can read this announcement blog. For a comprehensive look at the methodology, experiments, and evaluation, please see the full technical report. Let’s get started.
Have you ever wondered how computers are trained to interpret the meaning and context within your words, phrases, or even entire documents? The magic often lies in something called “embeddings” - numerical representations that capture the essence and meaning of text. EmbeddingGemma is an embedding model that can turn text into embeddings. These embeddings can be used for tasks like searching, retrieval augmented generation, and understanding.
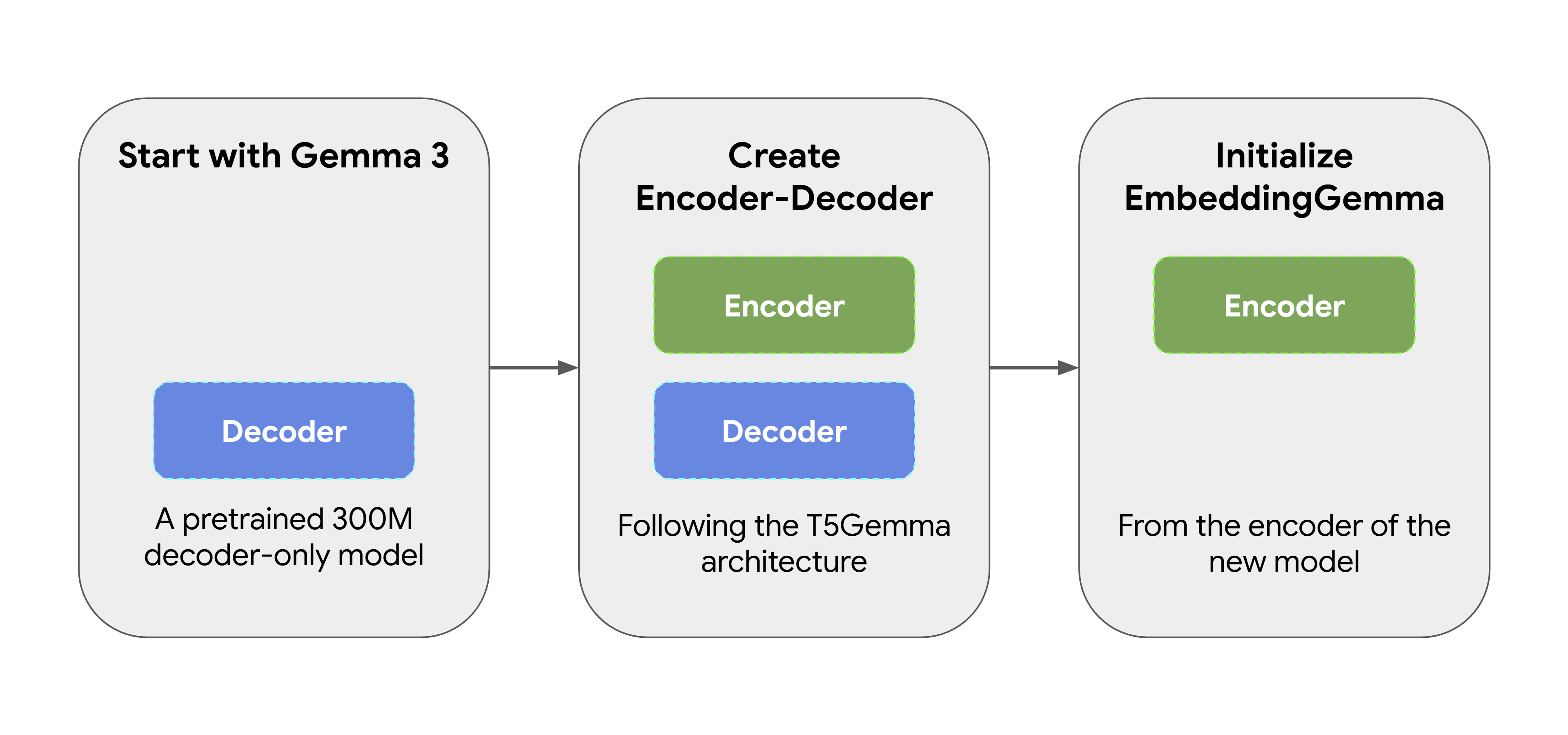
EmbeddingGemma wasn’t created from scratch. It started as a pretrained 300M parameter Gemma 3 model. It was then transformed using T5Gemma’s adaptation method, which converts the original decoder-only Gemma model into an encoder-decoder architecture. We then initialized EmbeddingGemma from the encoder of this new model, ensuring it is able to produce expressive representations from the start. This approach allows EmbeddingGemma to inherit a lot of “world knowledge” from its predecessor without having to do additional training
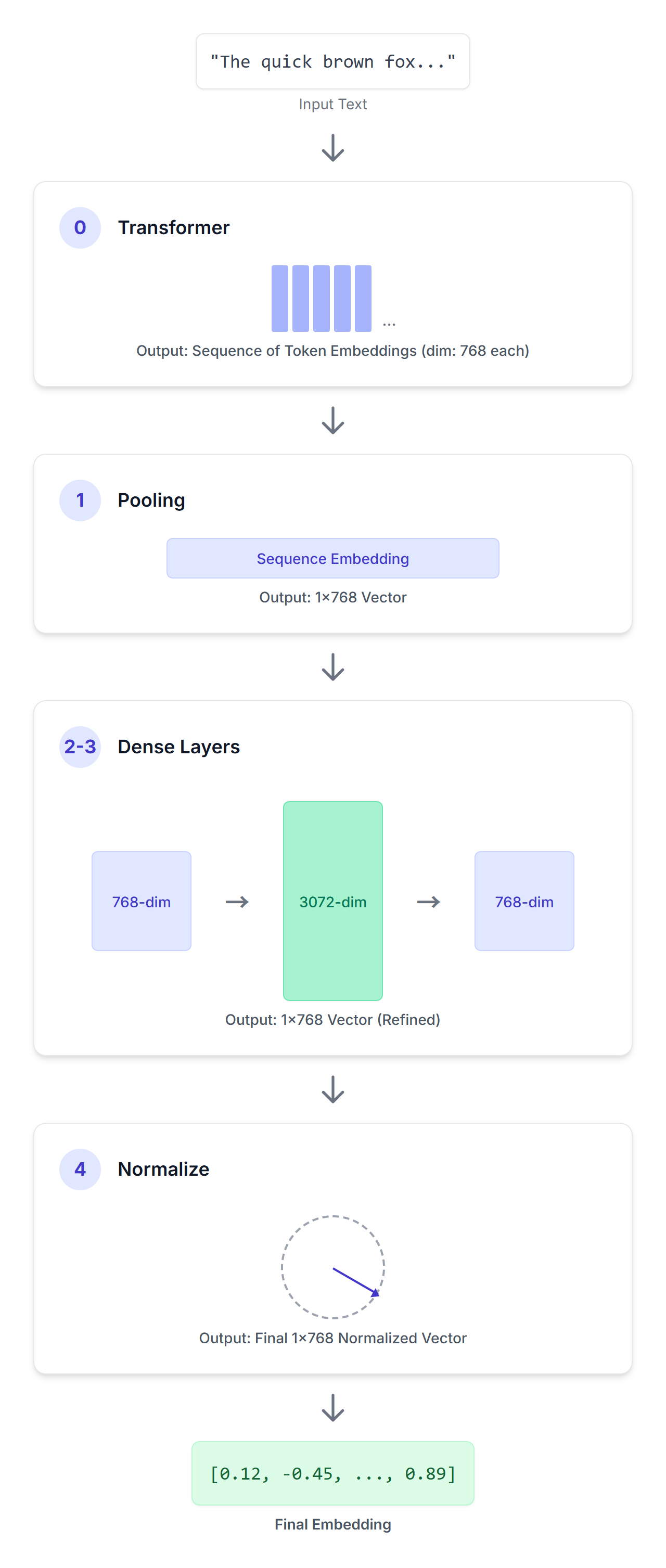
You can use EmbeddingGemma to generate embeddings using frameworks such as Sentence Transformers. Given an input sequence of text, EmbeddingGemma processes it through a series of carefully designed steps to produce a concise vector representation.
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)(0): Transformer
An input sequence passes through this encoder-only transformer model. This transformer utilizes bidirectional attention to understand the meaning of each token in the provided context, producing a sequence of 768-dimensional vectors, one for each token in your input sequence.
(1): Pooling
The output of the transformer is a sequence of token embeddings. The pooling layer’s job is to convert this variable-length sequence into a single, fixed-size embedding for the entire input. EmbeddingGemma is using a pooling strategy called “Mean Pooling”. This is the most common approach, where the average of all token embeddings is calculated.
(2): Dense
Next, we apply a linear projection to scale the embedding (768) up to a larger embedding dimension (3072).
(3): Dense
Then we apply another linear projection to scale the learned 3072-dimensional embedding to the final target dimension (768).
(4): Normalize
Finally, we apply Euclidean normalization, enabling efficient similarity comparisons. This is a simpler and cheaper operation compared to the more complex RMSNorm that you might recall from other Gemma models.
EmbeddingGemma learns to create its powerful embeddings by optimizing a combination of three distinct, weighted loss functions during its training.
The NCE loss teaches the model the fundamental concepts of similarity and contrast. For each input (e.g., a query), it learns to:
The key is the inclusion of "hard negatives" (answers that are semantically similar to the query but are incorrect or incomplete). By training on these tricky examples, the model is forced to learn the subtle, fine-grained distinctions that separate correct from nearly-correct ones.
It’s like building a well-organized library, where related items are placed near each other, while unrelated items are kept distant.
This loss is designed to encourage EmbeddingGemma to produce embeddings that are spread out over the embedding space. Even if the model learned to separate similar and dissimilar things, it might still get lazy and just stack all embeddings in the same small corner.
This Regularizer makes embeddings robust to quantization and enables efficient search in vector databases using Approximate Nearest Neighbor (ANN) algorithms.
This loss serves as a form of knowledge distillation, where EmbeddingGemma learns from a larger, more powerful Gemini Embedding model as a teacher.
The loss minimizes the L2 distance (a measure of difference) between the two embedding models’ embeddings for queries and passages. This enables EmbeddingGemma to learn from the teacher model, effectively inheriting much of its knowledge and capabilities.
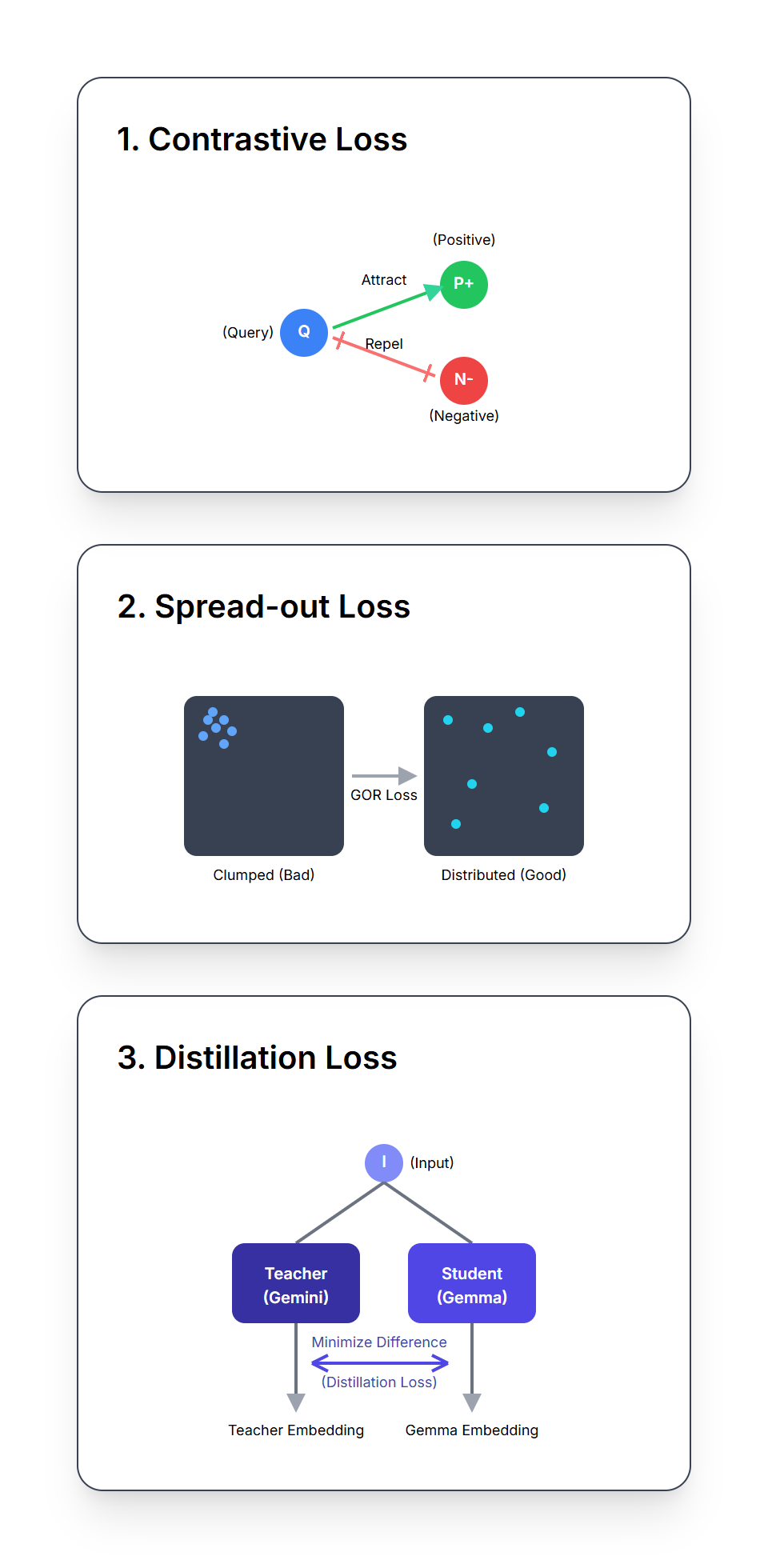
By combining these three loss functions, EmbeddingGemma learns to produce representations that are well-structured, expressive, and robust, enabling strong performance in real-world search and retrieval tasks.
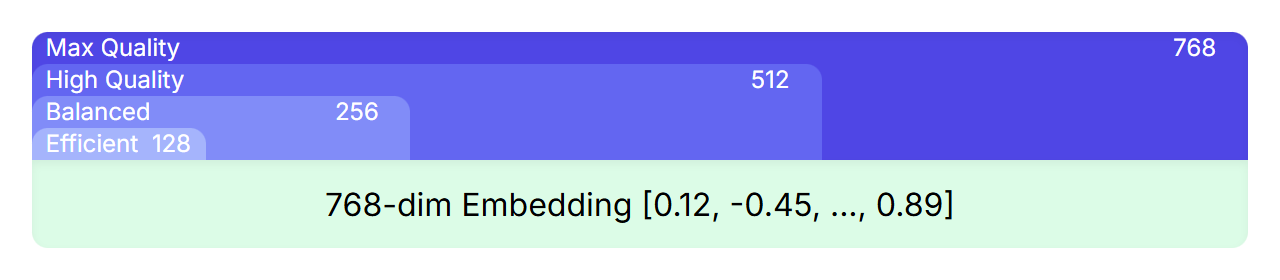
MRL is a technique that allows nesting smaller, high-quality representations within a larger one. For example, even though EmbeddingGemma’s embeddings have 768 dimensions, you can truncate the embeddings and get smaller ones with 512, 256, or even 128 dimensions which retain high quality.
During training, the loss functions are not just applied to the final 768-dimensional embedding, but also to the overlapping subsets of that embedding (the first 512, 256, and 128 dimensions). This ensures that even a truncated version of the full embedding is a powerful and complete representation.
For you, this means you can choose the right trade-off between performance and efficiency for your application without needing to train or manage multiple models. Simply select the embedding size that best fits your needs, ranging from the full 768 dimensions for maximum quality to smaller sizes for increased speed and lower storage costs.
The model’s journey includes several stages
By carefully adapting a powerful base model and refining it with a multi-faceted training approach, EmbeddingGemma's architecture is engineered to deliver highly effective and versatile text representations suitable for a wide range of applications.
We explored the architecture of EmbeddingGemma, a powerful model for generating text embeddings. We learned its origins, the process of generating embeddings, and the development recipe. For an in-depth dive into our training methodology, evaluation benchmarks, and the full experimental results, we encourage you to read the official technical report.
Models like EmbeddingGemma lead the way for more efficient and powerful semantic technologies. As these models become more capable and accessible, we can expect to see advancements in several key areas like Retrieval-Augmented Generation (RAG), on-device AI, and hyper-personalization.
Find the model weights on Hugging Face, Kaggle, Vertex AI and start tinkering today.
Thanks for reading!

Developer’s Guide to Building ADK Agents with Skills
Bring state-of-the-art agentic skills to the edge with Gemma 4

Introducing Metrax: performant, efficient, and robust model evaluation metrics in JAX
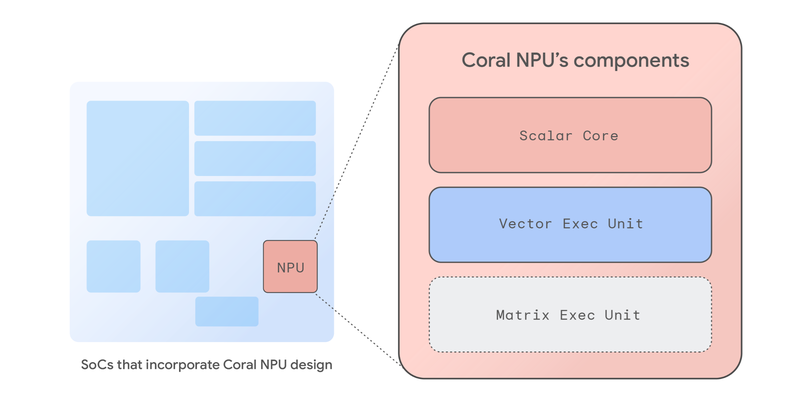
Introducing Coral NPU: A full-stack platform for Edge AI