'Gemma 설명' 시리즈의 이전 게시물에서 Gemma 모델 제품군의 아키텍처에 대한 개요를 상세히 설명했습니다. 각 게시물로 연결되는 링크는 아래에서 확인하실 수 있습니다.
이 글에서는 새로운 EmbeddingGemma의 아키텍처와 레시피를 살펴보겠습니다. 개략적인 소개는 이 공지사항 블로그에서 확인하실 수 있습니다. 구체적인 방법론과 실험, 평가에 대해 전반적으로 살펴보려면 기술 보고서 전문을 참조하세요. 이제 시작하겠습니다.
어떻게 컴퓨터가 단어나 구절, 심지어 전체 문서의 의미와 맥락을 해석하도록 학습하는 것인지 궁금했던 적이 있나요? 텍스트의 본질과 의미를 포착하는 수치적 표현인 '임베딩'에 바로 그 비밀이 있는 경우가 많습니다. EmbeddingGemma는 텍스트를 임베딩으로 변환할 수 있는 임베딩 모델입니다. 이러한 임베딩은 검색과 검색 증강 생성, 이해와 같은 작업에 사용할 수 있습니다.
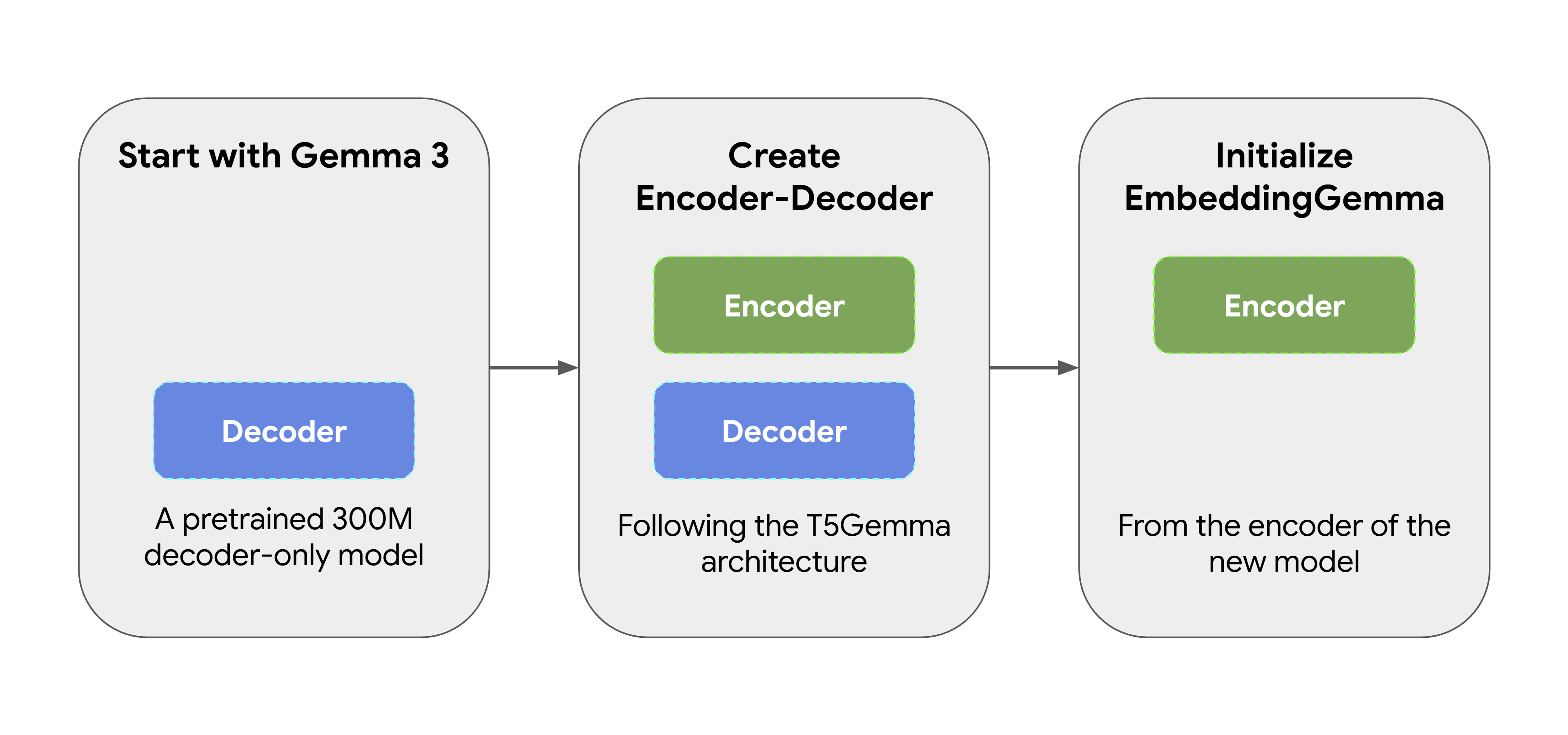
EmbeddingGemma는 완전히 새로 만들어진 모델이 아닙니다. 이 모델의 출발점은 사전 학습된 300M 매개변수를 가진 Gemma 3 모델입니다. 그다음엔 원래의 디코더 전용 Gemma 모델을 인코더-디코더 아키텍처로 변환하는 T5Gemma의 적응 방법을 사용하여 이 모델을 변환했습니다. 다음으로, 이 새 모델의 인코더에서 EmbeddingGemma를 초기화하여 처음부터 풍부한 표현을 생성할 수 있도록 했습니다. EmbeddingGemma는 이런 접근 방식을 통해 추가적인 학습을 할 필요 없이 이전 모델로부터 수많은 '세상의 지식'을 이어 받았습니다.
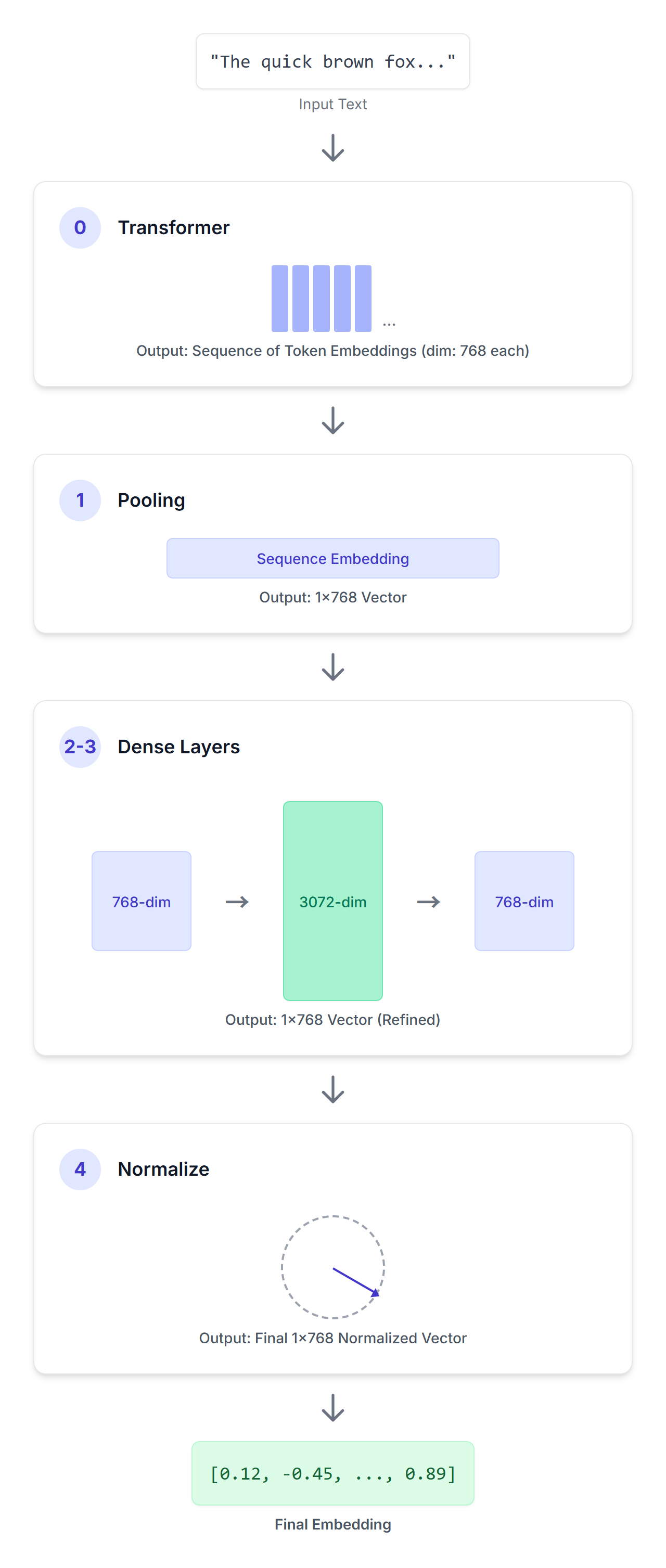
EmbeddingGemma를 활용하여 Sentence Transformers와 같은 프레임워크를 통해 임베딩을 생성할 수 있습니다. 텍스트 입력 시퀀스가 주어지면 EmbeddingGemma는 이를 정교하게 설계된 일련의 단계를 거쳐 처리하여 간결한 벡터 표현을 생성합니다.
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)(0): Transformer
입력 시퀀스는 이 인코더 전용 트랜스포머 모델을 거쳐 처리됩니다. 이 트랜스포머는 양방향 어텐션을 활용하여 주어진 컨텍스트 속에서 각 토큰의 의미를 이해하고, 입력 시퀀스의 각 토큰마다 하나씩 768차원 벡터로 이루어진 시퀀스를 생성합니다.
(1): Pooling
트랜스포머의 출력은 토큰 임베딩의 시퀀스입니다. 풀링 레이어의 역할은 이 가변 길이 시퀀스를 전체 입력에 대한 단일한 고정 크기 임베딩으로 변환하는 것입니다. EmbeddingGemma는 '평균 풀링'이라는 풀링 전략을 사용합니다. 이는 모든 토큰 임베딩의 평균이 계산되는 가장 일반적인 접근 방식입니다.
(2): Dense
다음으로, 선형 투영을 적용하여 임베딩(768)을 더 큰 임베딩 차원(3072)으로 확장합니다.
(3): Dense
그런 다음, 학습된 3072차원 임베딩을 최종 목표 차원(768)으로 축소하기 위해 또 다른 선형 투영을 적용합니다.
(4): Normalize
마지막으로, 유클리드 정규화를 적용하여 효율적으로 유사성을 비교할 수 있도록 합니다. 이는 다른 Gemma 모델에서 재현할 수 있는 더 복잡한 RMSNorm에 비해 더 간단하고 저렴한 작업입니다.
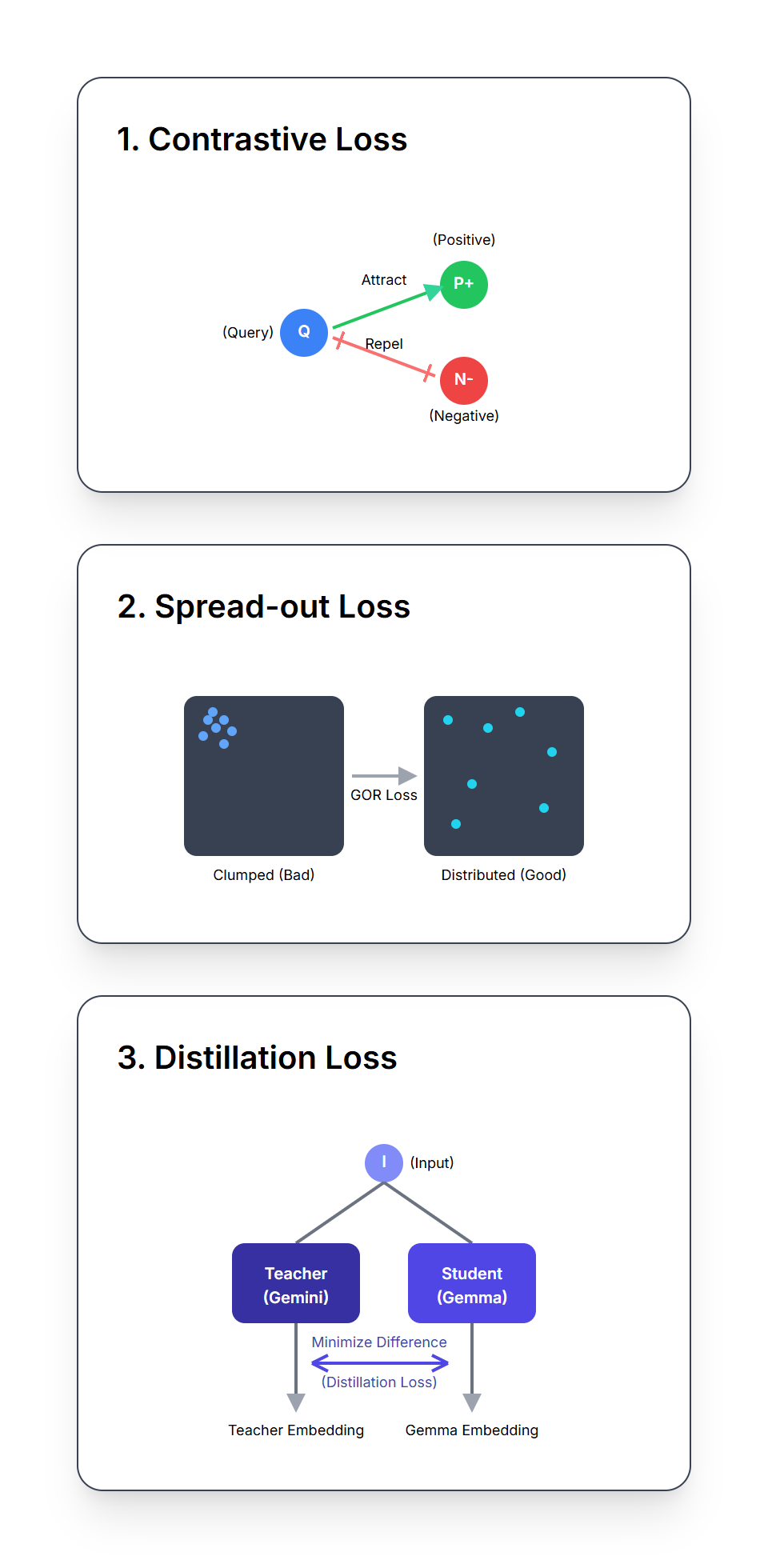
EmbeddingGemma는 학습 중에 세 가지 서로 다른 가중 손실 함수의 조합을 최적화하여 강력한 임베딩을 만드는 방법을 학습합니다.
NCE 손실은 모델에 유사성과 대조의 기본 개념을 가르칩니다. 모델은 각 입력(예: 쿼리)에 대해 다음을 수행하는 방법을 학습합니다.
핵심은 '하드 네거티브'(쿼리와 의미상 유사하지만 부정확하거나 불완전한 답변)를 포함하는 것입니다. 이처럼 까다로운 예제를 학습함으로써 모델은 정답과 거의 정답에 가까운 답변 사이의 미묘하고 세밀한 차이를 구분할 수밖에 없을 정도로 학습합니다.
이는 관련 있는 항목은 서로 가까이 배치되는 반면 관련 없는 항목은 서로 멀리 배치된 잘 정리된 라이브러리를 구축하는 것과 같습니다.
이 손실은 EmbededdingGemma가 임베딩을 임베딩 공간 전체에 분산해 생성하도록 유도하게끔 설계되었습니다. 모델이 유사한 것과 유사하지 않은 것을 구분하는 방법을 학습하더라도, 여전히 모델은 게을러져서 모든 임베딩을 그냥 똑같은 작은 모서리에 몰아 놓을 수도 있기 때문입니다.
이 Regularizer는 임베딩을 양자화에 강하게 만들고 ANN(Approximate Nearest Neighbor) 알고리즘을 사용하여 벡터 데이터베이스에서 효율적으로 검색할 수 있도록 합니다.
이 손실은 지식 증류의 한 형태로, EmbeddingGemma가 더 크고 더 강력한 Gemini Embedding 모델을 교사로 삼아 학습하도록 작동합니다.
이 손실은 쿼리와 구절에 대한 두 임베딩 모델의 임베딩 간 L2 거리(차이의 척도)를 최소화합니다. 이를 통해 EmbeddingGemma는 교사 모델로부터 학습하여, 그 지식과 능력의 대부분을 효과적으로 계승할 수 있습니다.
EmbeddingGemma는 이러한 세 가지 손실 함수를 결합하여 구조가 탄탄하고 풍부하면서도 견고한 표현을 생성하는 방법을 학습하여 실제 검색과 찾은 정보를 불러오는 작업에서 강력한 성능을 발휘합니다.
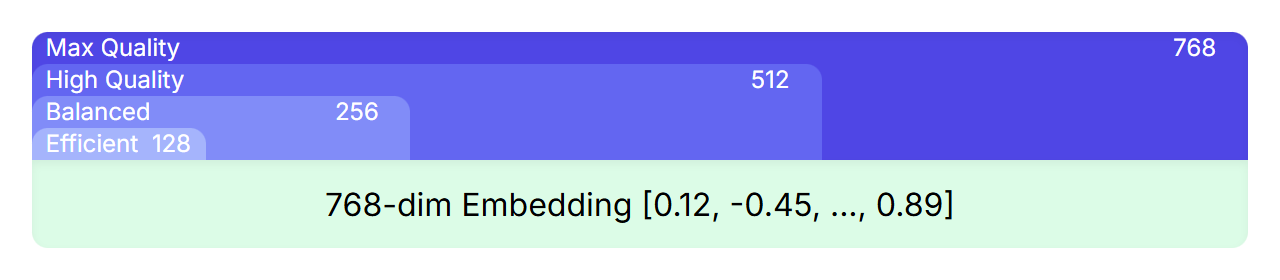
MRL은 큰 표현 내에 고품질의 작은 표현을 중첩할 수 있는 기법입니다. 예를 들어, EmbeddingGemma의 임베딩은 768차원이지만 임베딩을 잘라내 512차원, 256차원 또는 128차원의 더 작은 임베딩으로도 고품질을 유지하며 사용할 수 있습니다.
학습 중에 손실 함수는 최종 768차원 임베딩뿐만 아니라 그 임베딩의 겹치는 부분 집합(첫 번째 512차원, 256차원 및 128차원)에도 적용됩니다. 이를 통해 전체 임베딩을 잘라낸 축소된 버전도 강력하고 완전한 표현력을 유지할 수 있습니다.
즉, 여러 모델을 학습시키거나 관리할 필요 없이 애플리케이션의 성능과 효율성 간에 적절한 절충점을 선택할 수 있습니다. 최고 품질을 위한 전체 768차원부터 속도 향상과 저장 비용 절감을 위한 작은 크기까지, 필요에 가장 적합한 임베딩 크기를 선택하면 됩니다.
이 모델의 여정은 여러 단계로 이루어져 있습니다.
강력한 기본 모델을 세심하게 조정하고 다각적인 학습 접근 방식을 활용해 이를 정교하게 개선함으로써 EmbeddingGemma의 아키텍처는 광범위한 응용 분야에 적합한, 매우 효과적이고 다재다능한 텍스트 표현을 제공하도록 설계되었습니다.
오늘, 강력한 텍스트 임베딩 생성 모델인 EmbeddingGemma의 아키텍처를 살펴보았습니다. 그 과정에서 이 아키텍처의 기원, 임베딩 생성 과정, 개발 레시피를 알아보았습니다. 학습 방법론과 평가 벤치마크, 전체 실험 결과에 대해 자세히 알아보려면 공식 기술 보고서를 읽어보시기 바랍니다.
EmbeddingGemma와 같은 모델은 보다 효율적이고 강력한 시맨틱 기술을 선도합니다. 이러한 모델의 성능과 접근성이 높아짐에 따라, 검색 증강 생성(RAG), 온디바이스 AI, 초개인화와 같은 여러 핵심 영역에서 발전을 기대할 수 있습니다.
Hugging Face, Kaggle, Vertex AI에서 모델 가중치를 찾아 오늘 바로 사용해 보세요.
읽어주셔서 감사합니다!