Gemma 徹底解説シリーズのこれまでの記事では、Gemma モデル ファミリーのアーキテクチャを詳しく解説しました。それぞれの投稿へのリンクは以下のとおりです。
この投稿では、新しい EmbeddingGemma のアーキテクチャとそのレシピについて解説します。概要については、こちらのお知らせブログをご覧ください。トレーニング方法、テスト、評価について包括的に確認するには、テクニカル レポート全文をご覧ください。では、始めましょう。
コンピューターがどのようにして単語、フレーズ、さらには文書全体の意味と文脈を解釈するようにトレーニングされているのか疑問に思ったことはありませんか?その秘密は多くの場合「埋め込み」と呼ばれるものにあります。埋め込みは、テキストの本質と意味を捉える数値表現です。EmbeddingGemma は、テキストを埋め込みに変換できる埋め込みモデルです。この埋め込みは、検索、検索拡張生成、理解などのタスクに使用できます。
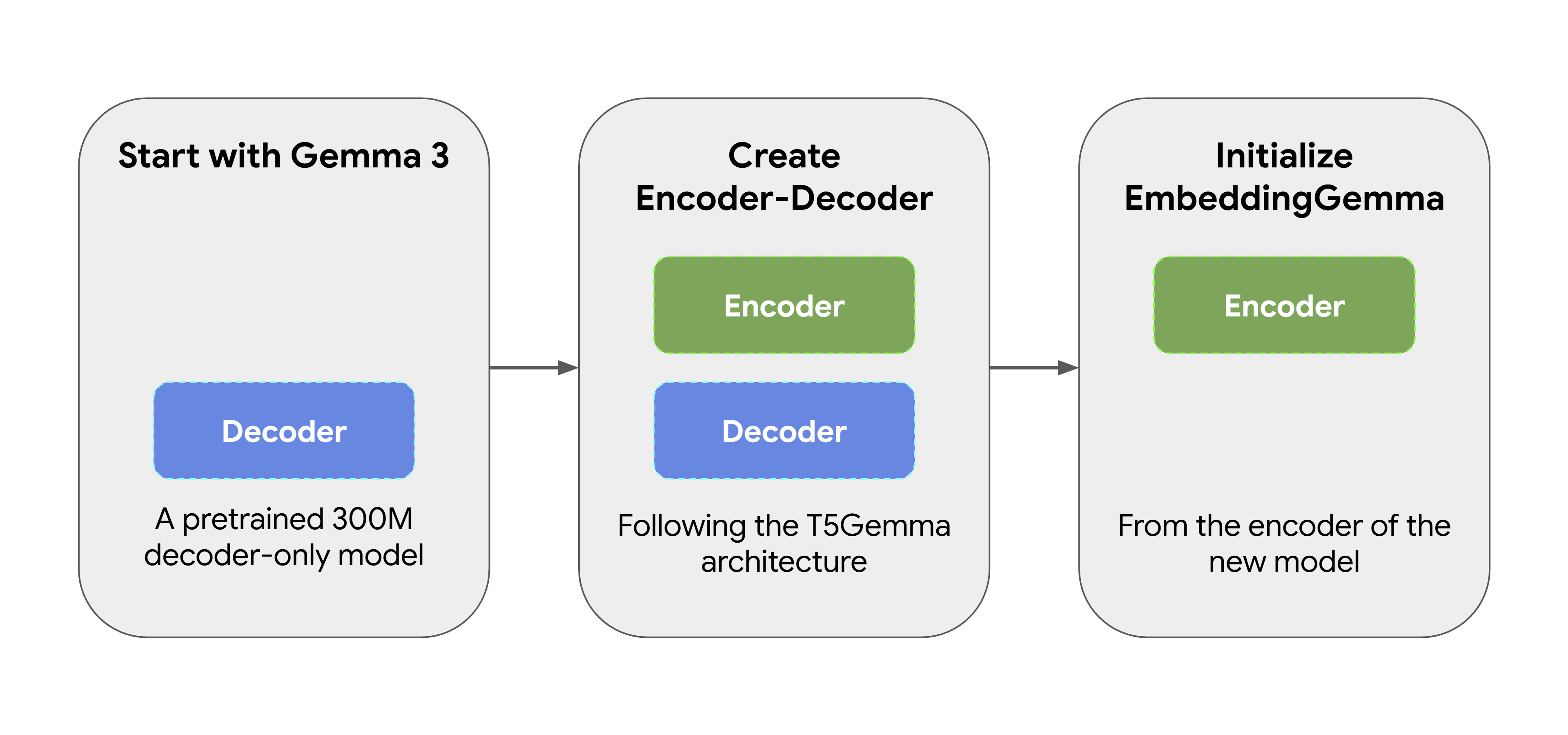
EmbeddingGemma はゼロから作成されたものではありません。事前にトレーニングされた 3 億パラメータの Gemma 3 モデルとして始まりました。その後、T5Gemma の適応手法を使用し、元のデコーダのみの Gemma モデルをエンコーダ - デコーダ アーキテクチャに変換しました。次に、この新しいモデルのエンコーダから EmbeddingGemma を初期化し、最初から表現を生成できるようにしました。このアプローチにより、EmbeddingGemma は追加のトレーニングを行うことなく、その前身となるモデルから多くの「世界についての知識」を継承することができます。
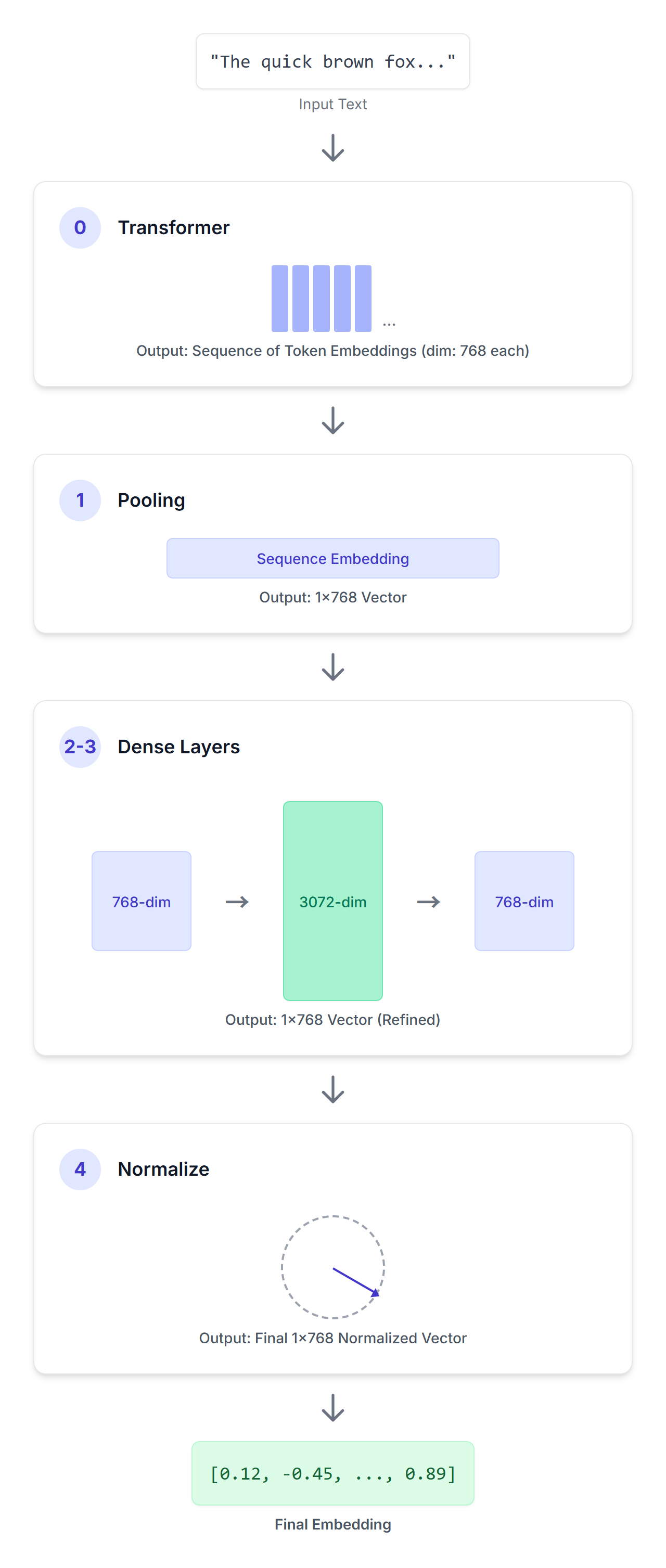
EmbeddingGemma を使用 することで、Sentence Transformers などのフレームワークを使用して埋め込みを生成できます。テキストの入力シーケンスを与えられると、EmbeddingGemma はそれを緻密に設計された一連のステップを通して処理し、簡潔なベクトル表現を生成します。
SentenceTransformer(
(0): Transformer({'max_seq_length': 2048, 'do_lower_case': False, 'architecture': 'Gemma3TextModel'})
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Dense({'in_features': 768, 'out_features': 3072, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(3): Dense({'in_features': 3072, 'out_features': 768, 'bias': False, 'activation_function': 'torch.nn.modules.linear.Identity'})
(4): Normalize()
)(0): Transformer
入力シーケンスは、このエンコーダのみの Transformer モデルを通過します。この Transformer 層は、双方向の注意を活用して、提供されたコンテキスト内の各トークンの意味を理解し、入力シーケンス内の各トークンに対して 768 次元のベクトルのシーケンスを生成します。
(1): Pooling
Transformer 層の出力は、トークン埋め込みのシーケンスです。Pooling 層の役割は、この可変長のシーケンスを入力全体で単一の固定長の埋め込みに変換することです。EmbeddingGemma は、「平均プーリング」と呼ばれるプーリング手法を使用しています。これは最も一般的なアプローチで、すべてのトークン埋め込みの平均を計算するものです。
(2): Dense
次に、線形投影を適用して、埋め込み(768 次元)をより大きな埋め込み次元(3072)に拡大します。
(3): Dense
その後、別の線形投影を適用して、学習した 3072 次元の埋め込みを最終的なターゲット次元(768)にスケーリングします。
(4): Normalize
最後に、ユークリッド正規化を適用して、効率的な類似性の比較を可能にします。これは、ほかの Gemma モデルで使用していたより複雑な RMSNorm と比較して、よりシンプルでコストの低い操作です。
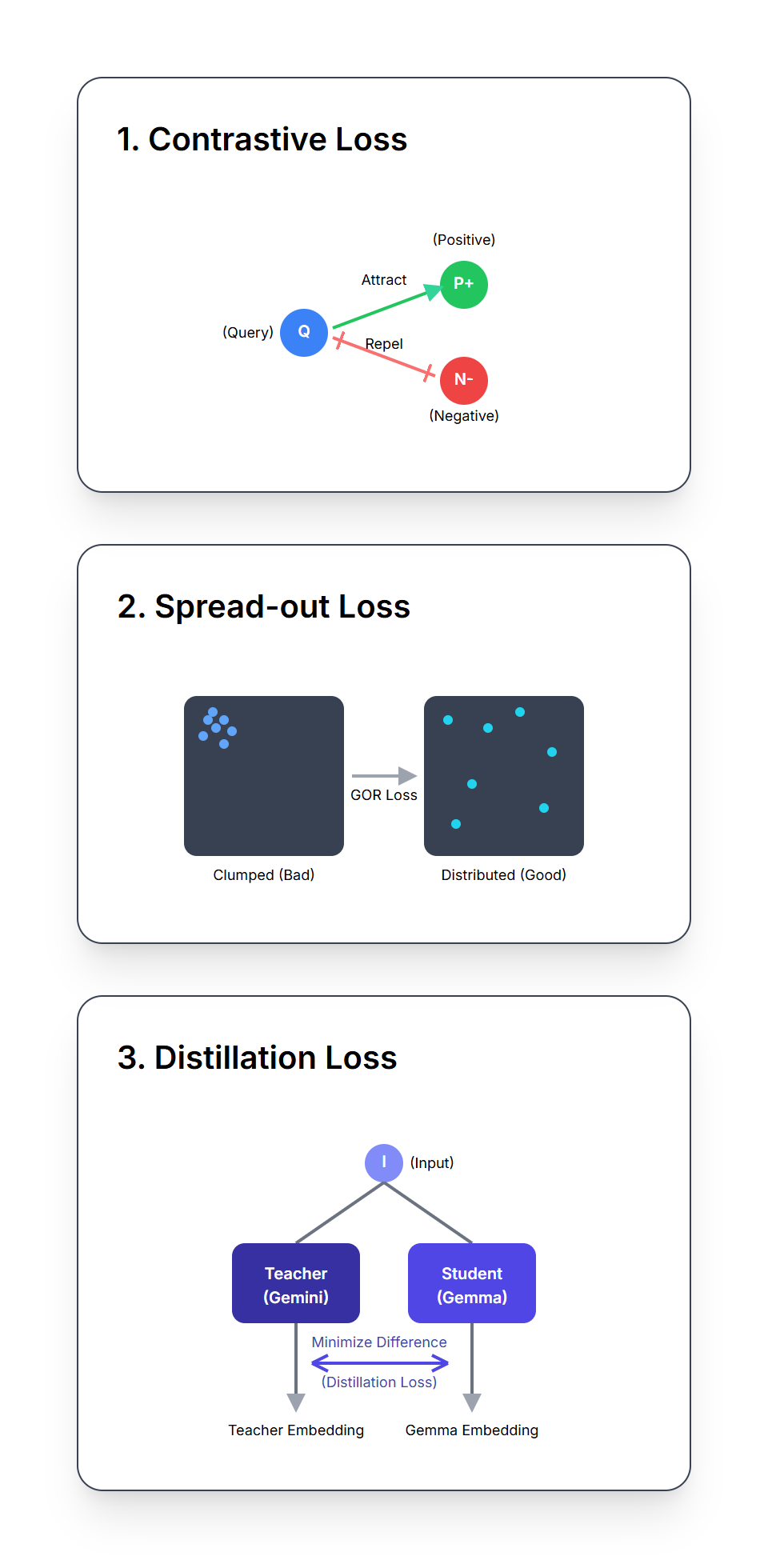
EmbeddingGemma は、トレーニング中に 3 つの異なる加重損失関数の組み合わせを最適化することで、強力な埋め込みを作成することを学習します。
NCE 損失は、EmbeddingGemma に類似性と対照性の基本的な概念を教えます。入力(クエリなど)ごとに、次のことを学習します。
重要なのは、「ハードネガティブ」(クエリと意味的に類似しているが、不正確または不完全な回答)を含めることです。このようなトリッキーな例を使用してトレーニングすることで、EmbeddingGemma は、正しい回答と正しそうに見える間違った回答を区別する微妙で細かい違いを学ぶことを余儀なくされます。
関連するアイテム同士が近くに置かれ、関連性のないアイテムが遠くに置かれる、整理されたライブラリを構築するようなものです。
この損失は、EmbeddingGemma が埋め込み空間全体に広がる埋め込みを生成するように設計されています。類似したものと異なったものを区別することを学んだとしても、怠惰になり、すべての埋め込みを片隅の 1 か所に積み重ねるだけになってしまう可能性があります。
この正則化は、埋め込みを量子化に対して堅牢にし、近似最近傍探索(ANN)アルゴリズムを使用してベクトル データベースでの効率的な検索を可能にします。
この損失は、知識蒸留の方式として役立ちます。EmbeddingGemma は、より大規模で強力な Gemini Embedding モデルを教師として学習します。
この損失は、2 つの埋め込みモデルのクエリとパッセージの埋め込みの間の L2 距離(差の尺度)を最小化します。これにより、EmbeddingGemma は教師モデルから学習し、その知識と能力の多くを効果的に継承することができます。
これら 3 つの損失関数を組み合わせることで、EmbeddingGemma は、適切に構造化された、表現力豊かで、堅牢な表現を生成することを学び、実世界に関する検索や情報取得タスクで高いパフォーマンスを実現します。
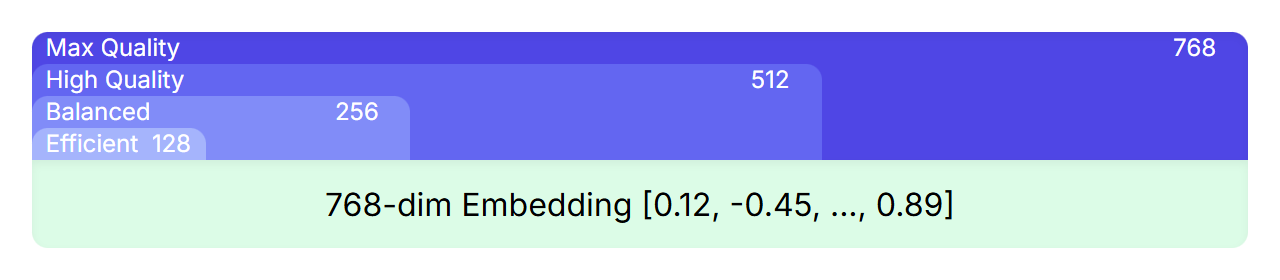
MRL は、大きな表現の中に、小さな高品質の表現を入れ子にすることを可能にする技術です。たとえば、EmbeddingGemma の埋め込みには 768 の次元がありますが、埋め込みを切り捨てて、512、256、128 次元の小さな埋め込みを高品質を維持したまま取得することができます。
トレーニング中、損失関数は、最終的な 768 次元の埋め込みだけでなく、その埋め込みの重複するサブセット(最初の 512、256、128 次元)にも適用されます。これにより、完全な埋め込みから切り出されたバージョンでも、強力で完全な表現にすることができます。
これにより、開発者は複数のモデルをトレーニングまたは管理する必要なく、アプリケーションのパフォーマンスと効率の適切なトレードオフを選択できます。最大限の品質を実現するための完全な 768 次元から、高速化とストレージ コストの削減を実現するための小さいサイズまで、ニーズに最適な埋め込みサイズを選択するだけです。
モデルの開発過程にはいくつかの段階があります。
強力なベースモデルを慎重に適応させ、多種多様なトレーニング手法で改良することで、EmbeddingGemma のアーキテクチャは、幅広い用途に適した非常に効果的で汎用性の高いテキスト表現を生成するように設計されています。
テキスト埋め込みを生成するための強力なモデルである EmbeddingGemma のアーキテクチャについて解説しました。その起源、埋め込みの生成プロセス、開発レシピを学びました。トレーニング方法、評価ベンチマーク、テスト結果の詳細については、公式テクニカル レポートをお読みいただくことをおすすめします。
EmbeddingGemma のようなモデルは、より効率的で強力なセマンティック技術の道を切り拓いています。このようなモデルがより機能的でアクセスしやすくなるにつれて、検索拡張生成 (RAG)、オンデバイス AI、ハイパー パーソナライゼーションなどのいくつかの重要な分野で進歩が見込まれます。
Hugging Face、Kaggle、Vertex AIでモデルの重みを見つけて、今日から試してみましょう。
お読みいただき、ありがとうございました!