

Today, Gemini 1.5 Flash-8B, our latest Flash variant, is production-ready and comes with:
Developers can access gemini-1.5-flash-8b for free via Google AI Studio and the Gemini API.
At I/O, we announced Gemini 1.5 Flash, our lightweight model, optimized for speed and efficiency. Over the last few months, Google DeepMind has made considerable progress making 1.5 Flash even better based on developer feedback and testing the limits of what’s possible.
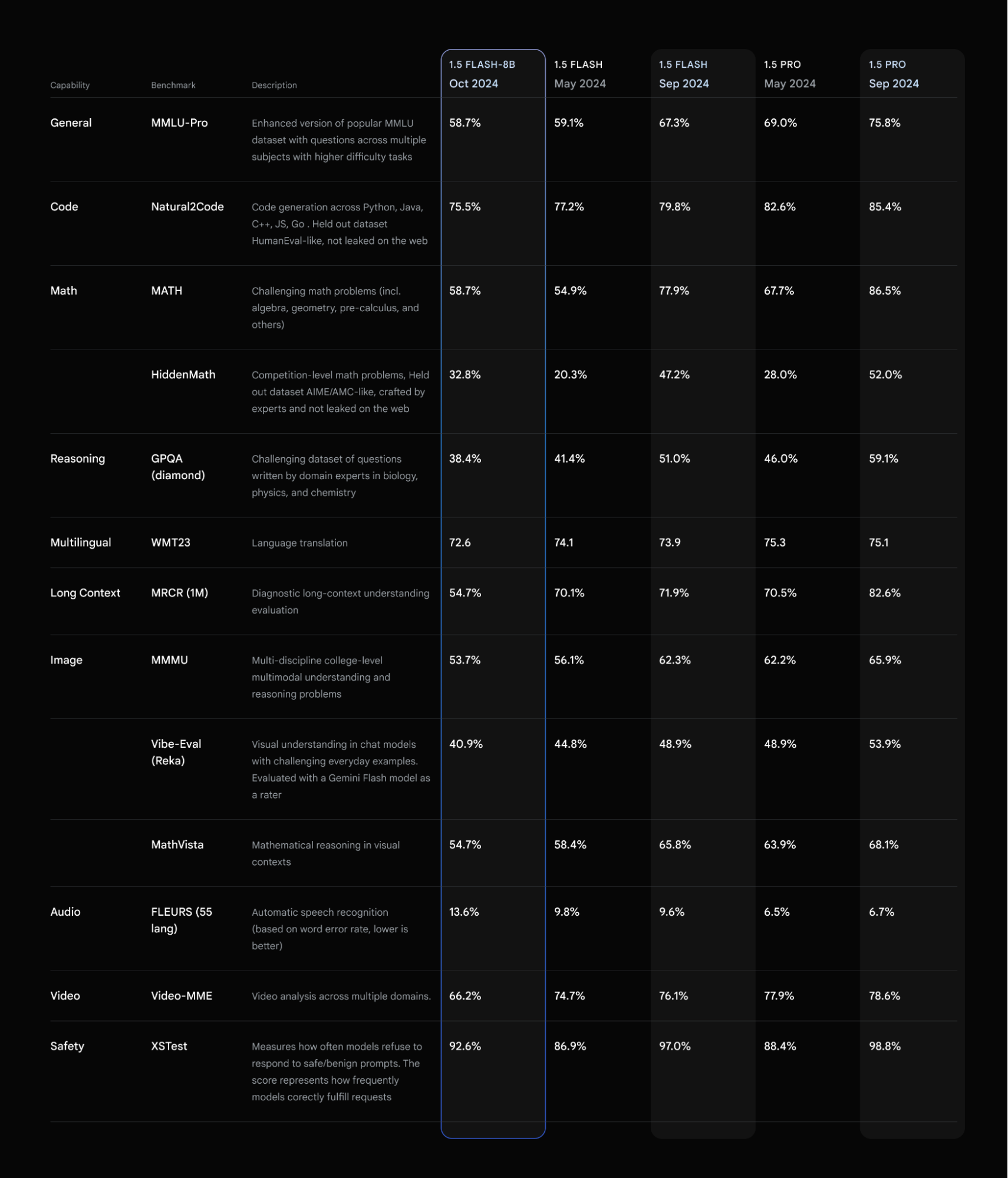
Last month, we released an experimental version of Gemini 1.5 Flash-8B, a smaller and faster variant of 1.5 Flash. We’re now excited to make it generally available for production-use. Flash-8B nearly matches the performance of the 1.5 Flash model launched in May across many benchmarks. It performs especially well on tasks such as chat, transcription, and long context language translation.
Our release of best in class small models continues to be informed by developer feedback and our own testing of what is possible with these models. We see the most potential for this model in tasks ranging from high volume multimodal use cases to long context summarization tasks.
With the stable release of Gemini 1.5 Flash-8B, we are announcing the lowest cost per intelligence of any Gemini model:
For developers on the paid tier, billing will start on Monday October 14th.
This new price, along with the work we have already done to drive down developer costs with 1.5 Flash and 1.5 Pro, highlights our commitment to ensuring developers have the freedom to build the products and services that push the world forward.

Gemini 1.5 Flash-8B is best suited for simple, higher volume tasks. To make this model as useful as we can, we are doubling the 1.5 Flash-8B rate limits, meaning developers can send up to 4,000 requests per minute (RPM).
Happy building and stay tuned for more updates!

Build Long-running AI agents that pause, resume, and never lose context with ADK

Accelerating on-device AI: A look at Arm and Google AI Edge optimization

Turn creative prompts into interactive XR experiences with Gemini

Announcing Genkit Middleware: Intercept, extend, and harden your agentic apps

How we built the Google I/O 2026 Save the Date experience