Today, Google DeepMind launched Gemma 4, a family of state-of-the-art open models that redefine what is possible on your own hardware. Now available under the Apache 2.0 license, Gemma 4 gives developers a powerful toolkit for on-device AI development. With Gemma 4, you can now go beyond chatbots to build agents and autonomous AI use cases running directly on-device. Gemma 4 enables multi-step planning, autonomous action, offline code generation, and even audio-visual processing, all without specialized fine-tuning. It’s also built for a global audience with support for over 140 languages.
We are excited to announce that you can experience Gemma 4’s expansive capabilities on the edge starting today! Access Android's built-in Gemma 4 model through the new AICore Developer Preview, or leverage Google AI Edge to build agentic, in-app experiences across mobile, desktop, and edge devices.
In this post, we’ll show you how to get started with Google AI Edge using both Google AI Edge Gallery and LiteRT-LM.
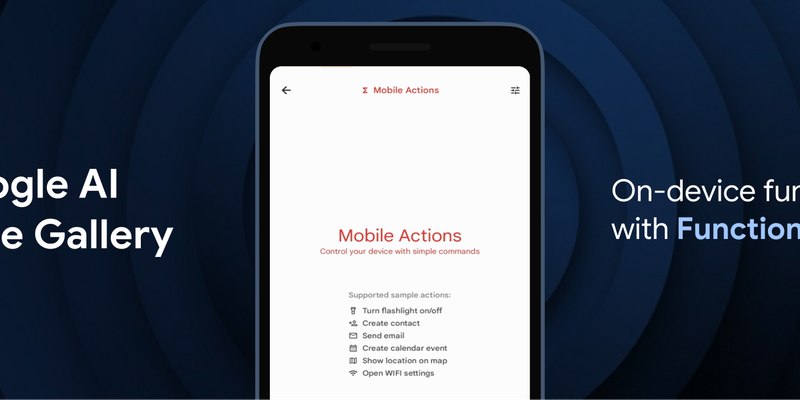
Google AI Edge Gallery, available on iOS and Android, allows you to build and experiment with AI experiences that run entirely on-device. Today, we are thrilled to announce the launch of Agent Skills, one of the first applications to run multi-step, autonomous agentic workflows entirely on-device. Powered by Gemma 4, Agent Skills can:
To experience the Gemma 4 E2B and E4B models in action, check out the Google AI Edge Gallery app today. Within the app, it’s easy to start experimenting and creating your own skills with our guide. We can’t wait to see what you build and share your skills in the Github Discussion!
For developers who are interested in deploying Gemma 4 in-app or across a broader range of devices, LiteRT-LM provides stellar performance with reach across the entire hardware spectrum. LiteRT-LM adds GenAI specific libraries on top of LiteRT, which is already trusted by millions of Android and edge developers with its high-performance libraries XNNPack and ML Drift. LiteRT-LM builds on this stack and enhances model performance with the following new features:
To support the extended context lengths required by agentic use cases, LiteRT-LM leverages cutting-edge GPU optimizations to process 4,000 input tokens across 2 distinct skills in under 3 seconds.
LiteRT-LM also brings smaller Gemma 4 models to IoT & edge devices with compelling performance. On a Raspberry Pi 5, for example, it achieves a prefill throughput of 133 tokens per second and decode throughput of 7.6 tokens per second on Gemma 4 E2B. With this performance, you can run smart home controllers, voice assistants, and robotics completely offline on constrained hardware.
Ready to get started? Check out the LiteRT-LM documentation for a complete guide and device-specific performance metrics. You can also view the individual model cards for Gemma 4 E2B and Gemma 4 E4B.
Gemma 4 is available today with support across an unprecedented range of platforms:
Today, we are also launching a new Python package and CLI tool to make it easier than ever to experiment with Gemma in the console, and to power Gemma-based Python pipelines for IoT devices. The litert-lm CLI is available on Linux, macOS, and Raspberry Pi, enabling developers to try out the latest Gemma 4 model capabilities without writing any code. The CLI now also supports tool calling that powered Agent Skills in Google AI Edge Gallery. Python bindings for LiteRT-LM provide the flexibility to deeply customize your on-device LLM pipeline from Python. Getting started with LiteRT-LM in your terminal is simple using our guide.
The era of agentic experiences on-device is here, and we hope you are excited to start building on the edge. Regardless of which device you are building on, get started with our Agent Skills examples in Google AI Edge Gallery, and LiteRT-LM getting started guide. We can’t wait to see what you build!
We'd like to extend a special thanks to our significant contributors for their work on this project:
Advait Jain, Alice Zheng, Amber Heinbockel, Andrew Zhang, Byungchul Kim, Cormac Brick, Daniel Ho, Derek Bekebrede, Dillon Sharlet, Eric Yang, Fengwu Yao, Frank Barchard, Grant Jensen, Hriday Chhabria, Jae Yoo, Jenn Lee, Jing Jin, Jingxiao Zheng, Juhyun Lee, Lu Wang, Lin Chen, Majid Dadashi, Marissa Ikonomidis, Matthew Chan, Matthew Soulanille, Matthias Grundmann, Milen Ferev, Misha Gutman, Mohammadreza Heydary, Pradeep Kuppala, Qidong Zhao, Quentin Khan, Ram Iyengar, Raman Sarokin, Renjie Wu, Rishika Sinha, Rodney Witcher, Ronghui Zhu, Sachin Kotwani, Suleman Shahid, Tenghui Zhu, Terry Heo, Tiffany Hsiao, Wai Hon Law, Weiyi Wang, Xiaoming Hu, Xu Chen, Yishuang Pang, Yi-Chun Kuo, Yu-Hui Chen, Zichuan Wei, and the gTech team.