For developers and researchers in the JAX ecosystem, the path from a pre-trained model to a fully aligned, production-ready LLM just got a lot simpler.
Today, we're excited to introduce Tunix, a new open-source, JAX-native library built specifically for LLM post-training. Tunix closes a critical gap by providing a comprehensive and developer-friendly toolkit for aligning models at scale.
Built for performance on TPUs, especially when combined with MaxText, Tunix offers:
This initial release provides modular and easy-to-use APIs for the most common post-training workflows, seamlessly integrated with the JAX ecosystem:
PeftTrainer is model-agnostic and supports both full-weight fine-tuning and popular parameter-efficient tuning methods like LoRA and QLoRA (via our integration with the qwix library).DPOTrainer streamlines alignment by implementing Direct Preference Optimization (DPO). This powerful technique uses a simple dataset of preferred and rejected responses, bypassing the need to train and manage a separate reward model.PPOLearner: Provides the gold-standard actor-critic method for RLHF by implementing Proximal Policy Optimization (PPO). This is essential for training models on complex, sequential tasks, especially for emerging agentic workflows involving tool use.GRPOLearner: Offers a highly efficient, critic-free RL algorithm. It implements Group Relative Policy Optimization(GRPO), which normalizes rewards across a group of generated responses to guide the model without the complexity and cost of a separate critic model.Group Sequence Policy Optimization (GSPO-token): Offers a variant of GRPO algorithm that provides better flexibility for adjusting token level advantage computation, and can improve stability for multi-turn RL training.DistillationTrainer enables model compression by training a smaller, more efficient 'student' model to replicate the outputs of a larger 'teacher' model. This is a critical technique for deploying high-performing models in production environments with tight latency or cost constraints. Tunix provides the following distillation algorithms out of the box:We have crafted several python notebooks to help users onboard Tunix. The results below demonstrate the effectiveness of Tunix's GRPO implementation. On the GSM8K math reasoning benchmark, fine-tuning the Gemma 2 2B-IT model with Tunix resulted in a ~12% relative improvement in pass@1 answer accuracy. We observed promising gains across all metrics, showcasing the library's ability to quickly and effectively align model behavior.
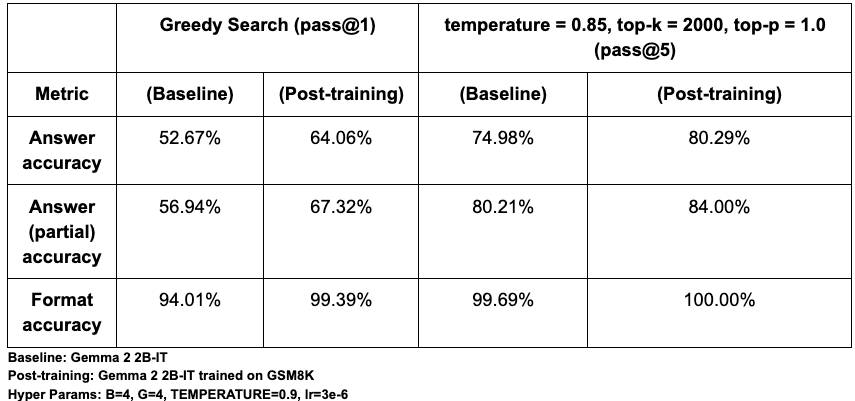
To account for the stochastic nature of text generation, we evaluated performance using both pass@1 (greedy search) and pass@5 (sampling with diversity) to measure correctness across one or five attempts. Our evaluation focused on three key metrics:
For validation, our baseline pass@1 accuracy of ~52% aligns closely with the ~51% reported by Eleuther’s LM Eval Harness for the base model, confirming our setup's validity. While absolute accuracy is sensitive to prompt formatting (e.g. using <start_answer> vs. <answer>), the significant performance lift from post-training remains consistent across different settings.
Link to Youtube Video (visible only when JS is disabled)
From leading academic labs to AI startups, Tunix is already empowering the next wave of ML development. We're developing Tunix in collaboration with our partners to solve real-world challenges in model alignment and agentic AI. Here’s what they have to say:
"My research focuses on data-centric learning, which involves preparing high-quality data to improve model performance, especially in the post-training phase of large language models (LLMs). A key challenge is to quickly iterate on data samples to identify which are helpful and which are not. For this, Tunix is the perfect library. Its 'white-box' design gives my team full control over the training loop, allowing us to easily modify and adapt the code for our specific research needs. This customizability is a significant advantage over other frameworks and is crucial for accelerating our iterative data analysis."
— Hongfu Liu, Assistant Professor of Computer Science, Brandeis University; Senior Area Chair for NeurIPS; Area Chair for ICLR
"A primary bottleneck in post-training reinforcement learning is the scarcity of environments with verifiable rewards. Gaming provides a perfect, multi-turn environment to solve this, and Tunix is the ideal framework for this research. It allows us to build directly on JAX, leveraging TPUs and easy parallelization. Compared to other alternatives, Tunix is a lightweight library with a clean, manageable codebase. It offers high-level customization of models and hyperparameters without the excessive abstraction layers of other frameworks. This streamlined approach is crucial for our work, and we found the learning curve to be gentle, as you don't need to be a JAX expert to be effective."
— Hao Zhang, Assistant Professor, UC San Diego, Co-creator of vLLM, Chatbot Arena (LMSys), and Inventor of Disaggregated Serving
Precur AI is a startup building an Agent Compiler that transforms background workflows into reliable and efficient code-driven agents. Hanjun Dai, Cofounder and CTO, says:
"Our company focuses on background agents running 24/7 without supervision. A key goal is agent robustness, so we post-train “agent kernels” - the models optimized for long-horizon but repetitive tasks. Tunix's breadth of design, covering SFT, RL, and distillation, allows us to keep our entire agent development stack unified. Its native integration with the JAX and TPU ecosystem is a significant advantage. The ease of customization with Flax for development and Qwix for quantized serving makes it a clean and powerful framework that fits very easily into our workflow."
— Hanjun Dai, Cofounder and CTO, PreCur AI
We are building Tunix in the open and invite you to join our community, try it out, and contribute.
We're excited to share Tunix with the JAX community and look forward to seeing what you build.