

JAX 생태계의 개발자와 연구자에게 있어 사전 학습된 모델에서 완전히 정렬되고 프로덕션 환경에서 바로 사용할 준비가 된 LLM으로 가는 경로가 훨씬 더 간단해졌습니다.
오늘, LLM 사후 학습용으로 특별히 구축된 새로운 오픈소스 JAX 네이티브 라이브러리인 Tunix를 선보이게 되어 기쁩니다. Tunix는 대규모 모델 정렬을 위한 포괄적이고 개발자 친화적인 툴킷을 제공하여 매우 중요한 격차를 해소합니다.
특히 MaxText와 결합 시 TPU에서 뛰어난 성능을 발휘하도록 구축된 Tunix는 다음과 같은 이점이 있습니다.
이 초기 버전에서는 가장 일반적인 사후 학습 워크플로를 위한 사용하기 쉬운 모듈식 API를 제공하며, JAX 생태계와 원활하게 통합됩니다.
PeftTrainer는 모델에 구애받지 않으며, 전체 가중치 파인 튜닝과 LoRA 및 QLoRA 같은 인기 있는 매개변수 효율성이 뛰어난 튜닝 방법을 모두 지원합니다. (qwix 라이브러리와의 통합을 이용함)DPOTrainer는 DPO(Direct Preference Optimization, 직접 선호도 최적화)를 구현하여 정렬을 간소화합니다. 이 강력한 기법은 선호하는 응답과 거부하는 응답으로 구성된 간단한 데이터 세트를 사용하므로 별도의 리워드 모델을 학습 및 관리할 필요가 없습니다.PPOLearner: PPO(Proximal Policy Optimization, 근접 정책 최적화)를 구현하여 RLHF(인간 피드백을 통한 강화 학습)를 위한 황금률인 행위자-비평가 방법을 제공합니다. 이 방법은 복잡하고 연속적인 작업에서 모델을 학습시키는 데 필수적이며, 특히 도구 사용이 포함된 새로운 에이전트형 워크플로에 유용합니다.GRPOLearner: 매우 효율적이고 크리틱이 없는 RL 알고리즘을 제공합니다. GRPO(Group Relative Policy Optimization, 그룹 상대 정책 최적화)를 구현하여 생성된 응답 그룹 전반에서 리워드를 정규화하여 별도의 크리틱 모델 구축에 따르는 복잡성과 비용 없이도 모델을 안내합니다.GSPO(Group Sequence Policy Optimization, 그룹 시퀀스 정책 최적화) 토큰: 토큰 단위의 이점 계산을 조정하는 데 더 나은 유연성을 제공하는 GRPO 알고리즘의 변형으로, 다중 턴 RL 학습의 안정성을 향상시킬 수 있습니다.DistillationTrainer는 더 작고 더 효율적인 '학생' 모델이 더 큰 '교사' 모델의 출력을 모방하도록 학습시켜 모델 압축을 가능하게 합니다. 이는 지연 시간이나 비용 제약 조건이 엄격한 프로덕션 환경에서 고성능 모델을 배포하는 데 중요한 기법입니다. Tunix는 별도의 구성 없이 바로 다음과 같은 증류 알고리즘을 제공합니다.저희는 사용자가 Tunix를 익히는 데 도움이 되도록 몇 가지 Python 노트북을 제작했습니다. 아래 결과는 Tunix의 GRPO 구현을 통해 얻은 효과를 보여줍니다. GSM8K 수학 추론 벤치마크에서 Tunix로 Gemma 2 2B-IT 모델을 파인 튜닝한 결과 pass@1 답변 정확도가 약 12% 향상되었습니다. 모든 측정항목에서 유의미한 수치 증가를 관찰했으며, 이는 모델의 행동을 해당 라이브러리가 빠르고 효과적으로 정렬할 수 있음을 보여주었습니다.
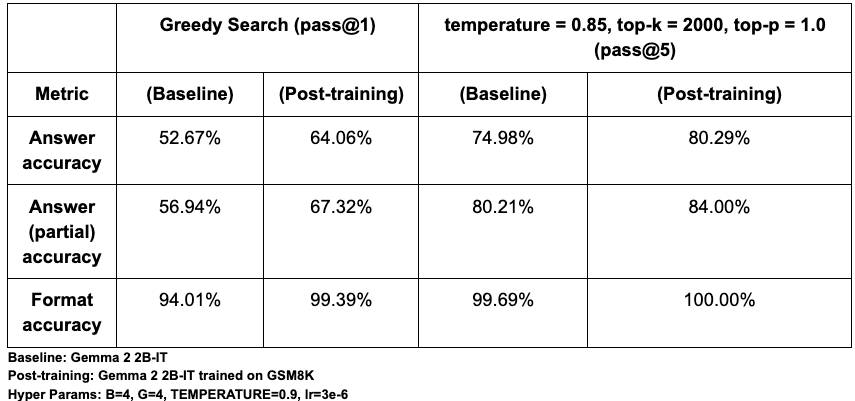
텍스트 생성의 확률적 특성을 고려하여, 한 번 또는 다섯 번의 시도에서 정확도를 측정하기 위해 pass@1(탐욕적 검색)과 pass@5(다양성을 고려한 샘플링)를 모두 사용하여 성능을 평가했습니다. 평가는 다음 세 가지 주요 측정항목에 중점을 두었습니다.
검증에 있어, 저희의 기준선 pass@1 정확도 약 52%는 기본 모델에 대해 Eleuther의 LM Eval Harness가 보고한 약 51%와 거의 일치하며, 이는 저희 설정의 타당성을 확인해 줍니다. 절대 정확도는 프롬프트 형식 지정(예: <start_answer> 대 <answer>를 비교)에 <따라 민감하게 변할 수 있지만 사후 학습으로 인한 큰 성능 향상은 다양한 설정에서도 일관되게 나타납니다.
Link to Youtube Video (visible only when JS is disabled)
대표적인 학술 연구소부터 AI 스타트업까지, Tunix는 이미 차세대 ML 개발에 힘을 실어주고 있습니다. 저희는 모델 정렬 및 에이전트형 AI에서 실제 문제를 해결하기 위해 여러 파트너사와의 협업하여 Tunix를 발전시키고 있습니다. 여러 파트너사가 보내준 의견의 일부를 소개합니다.
"제 연구는 데이터 중심 학습에 초점을 맞추고 있습니다. 여기에는 특히 LLM(대형 언어 모델)의 사후 학습 단계에서 모델 성능을 개선하기 위한 고품질 데이터 준비가 포함됩니다. 핵심 과제는 데이터 샘플을 기반으로 신속하게 반복하여 도움이 되는 것과 그렇지 않은 것을 식별하는 것입니다. Tunix는 이런 목적으로 사용하기에 완벽한 라이브러리입니다. '화이트 박스' 설계 덕분에 저희 팀은 학습 루프를 완벽하게 제어할 수 있어 특정 연구 요구사항에 맞게 코드를 수월하게 수정 및 조정할 수 있습니다. 이러한 사용자 설정 기능은 다른 프레임워크에 비해 큰 장점이며 반복 데이터 분석을 가속화하는 데 매우 중요합니다."
— Hongfu Liu, 브랜다이스 대학교 컴퓨터 과학과 조교수, NeurIPS 수석 지역 위원장, ICLR 지역 위원장
"사후 강화 학습에서의 주요 병목 현상은 검증 가능한 리워드를 제공하는 환경이 부족하다는 점입니다. 게임은 이 문제를 해결할 수 있는 완벽한 멀티 턴 환경을 제공하며, Tunix는 이 연구에 이상적인 프레임워크입니다. Tunix를 사용하면 TPU와 손쉬운 동시 로드를 활용하여 JAX에서 직접 개발할 수 있습니다. 다른 대안과 비교해 Tunix는 깔끔하고 관리하기 쉬운 코드베이스를 갖춘 경량 라이브러리입니다. 다른 프레임워크의 과도한 추상화 레이어 없이 모델과 하이퍼파라미터를 상위 수준에서 사용자 설정할 수 있습니다. 이런 간소한 접근 방식은 저희 업무에 매우 중요하며, 꼭 JAX 전문가가 아니더라도 효율적으로 활용할 수 있어 학습 곡선이 완만하다는 점을 알게 되었습니다."
— Hao Zhang, UC 샌디에이고 대학교 조교수, vLLM, Chatbot Arena(LMSys) 코크리에이터, Disaggregated Serving 발명가
Precur AI는 백그라운드 워크플로를 안정적이고 효율적인 코드 기반 에이전트로 변환하는 에이전트 컴파일러를 개발하는 스타트업입니다. 공동 창업자 겸 CTO인 Hanjun Dai는 다음과 같이 말합니다.
"우리 회사는 감독 없이 연중무휴 하루 24시간 실행되는 백그라운드 에이전트에 주력합니다. 핵심 목표는 에이전트의 견고성이죠. 그래서 이를 위해 장기적이지만 반복적인 작업에 최적화된 모델인 '에이전트 커널'을 사후 학습시킵니다. SFT, RL, 증류를 아우르는 Tunix의 광범위한 설계 덕분에 전체 에이전트 개발 스택을 통합된 상태로 유지할 수 있어요. JAX 및 TPU 생태계와 기본적으로 통합된 것은 큰 장점입니다. 개발을 위한 Flax와 양자화된 서빙을 위한 Qwix를 통한 손쉬운 사용자 설정 덕분에 매우 손쉽게 우리의 워크플로에 녹아드는 깔끔하고 강력한 프레임워크입니다."
— Hanjun Dai, PreCur AI 공동 설립자 겸 CTO
저희는 Tunix를 공개적으로 개발하고 있습니다. 여러분도 저희 커뮤니티에 참여해 Tunix를 직접 사용해 보시고 다양한 방식으로 개발에 기여해 주시길 바랍니다.
Tunix를 JAX 커뮤니티와 공유하게 되어 기쁘게 생각하며, 개발자 여러분이 무엇을 개발하실지 기대됩니다.

