

JAX エコシステムのデベロッパーや研究者にとって、事前トレーニング済みモデルから、プロダクション レディかつ完全にアライメントされた LLM までのプロセスが、これまでになく簡単になりました。
Google はこの度、LLM のポスト トレーニング専用に開発されたオープンソースの JAX ネイティブ ライブラリ、Tunix を公開いたします。Tunix は、モデルを大規模にアライメントするための包括的なデベロッパー向けツールキットを提供し、これまで存在していた重要なギャップを解消します。
Tunix は、特に MaxText と組み合わせることで、TPU で高いパフォーマンスを実現します。その特長は以下のとおりです。
この初期リリースでは、JAX エコシステムとシームレスに統合された、最も一般的なポスト トレーニング ワークフローのためのモジュール式で使いやすい API が提供されます。
PeftTrainer は、モデル非依存であり、フル ファイン チューニングに加え、qwix ライブラリとの統合を通じて、LoRA や QLoRA のようなパラメータ効率の高い一般的なチューニング手法もサポートしています。DPOTrainer は、Direct Preference Optimization(DPO)を実装することで、アライメントを効率化します。この強力な手法は、望ましいレスポンスと拒否されたレスポンスのシンプルなデータセットを使用し、個別の報酬モデルをトレーニングおよび管理する必要性を回避します。PPOLearner: Proximal Policy Optimization(PPO)を実装することにより、RLHF のための実質的な標準である Actor-Critic 法を提供します。これは特に、ツールの使用を伴う新しいエージェント型ワークフローにおいて、複雑かつ連続的なタスクでモデルをトレーニングする際に不可欠です。GRPOLearner: 非常に効率的で Critic 不要の RL アルゴリズムを提供します。Group Relative Policy Optimization(GRPO)を実装し、生成されたレスポンスのグループ全体の報酬を正規化することで、別の Critic モデルを使用する場合の複雑さやコストを伴うことなく、モデルを導きます。Group Sequence Policy Optimization(GSPO-token): トークンレベルのアドバンテージ計算をより柔軟に調整できるようにし、マルチターンの RL トレーニングの安定性を向上させる、GRPO アルゴリズムのバリアントを提供します。DistillationTrainer は、大規模な「教師」モデルの出力を再現するように、小規模で効率的な「生徒」モデルをトレーニングすることで、モデルの圧縮を実現します。これは、レイテンシやコストの制約が厳しい本番環境で、高性能モデルをデプロイするために欠かせない手法です。Tunix では、以下の蒸留アルゴリズムを標準で利用できます。Tunix の導入を支援するために、複数の Python ノートブックを用意しました。以下の結果は、Tunix の GRPO 実装の有効性を示しています。GSM8K の数学的推論のベンチマークでは、Gemma 2 2B-IT モデルを Tunix でファイン チューニングした結果、pass@1 精度が約 12% 相対的に向上しました。すべての指標で有望な成果が確認され、モデルの動作を迅速かつ効果的に調整するライブラリの能力が示されました。
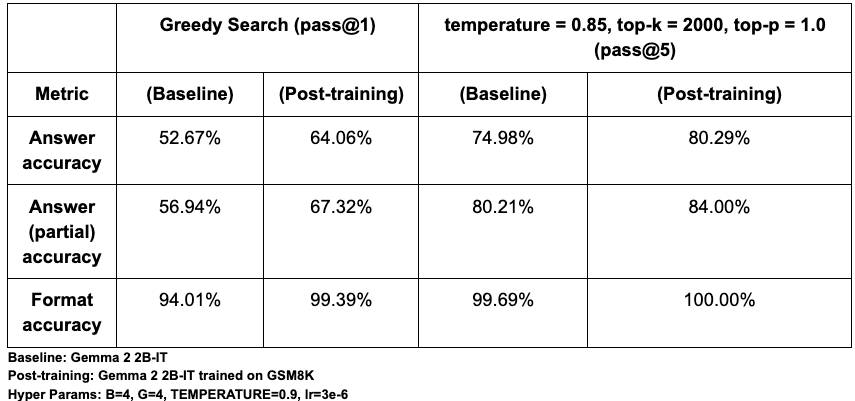
テキスト生成の確率的性質を考慮して、pass@1(貪欲探索)と pass@5(多様性サンプリング)の両方を使用してパフォーマンスを評価し、1 回または 5 回の試行における正確性を測定しました。評価では、以下の 3 つの主要な指標に着目しました。
検証の結果、ベースラインの pass@1 精度は約 52% で、Eleuther の LM Eval Harness によるベースモデルの評価、約 51% とほぼ一致し、本セットアップの妥当性が確認されました。絶対的な精度はプロンプトの形式(<start_answer> と <answer> のどちらを使用するかなど)に影響を受けやすいものの、ポスト トレーニングによるパフォーマンスの大幅な向上は異なる設定間でも一貫しています。
Link to Youtube Video (visible only when JS is disabled)
最先端の学術研究機関から AI スタートアップまで、Tunix はすでに次世代の機械学習開発を支えています。Google は、モデル アライメントとエージェント AI に関する実世界の課題を解決するために、パートナーと連携して Tunix の開発を進めています。ここで、パートナーからのコメントをご紹介します。
「私の研究は、データ中心の学習に重点を置いており、特に大規模言語モデル(LLM)のポスト トレーニングの段階で、モデルの性能を向上させるために高品質なデータを準備する必要があります。主な課題は、データサンプルを素早く反復し、有用なものとそうでないものを見極めることです。この点において、Tunix は最適なライブラリです。「ホワイト ボックス」設計により、トレーニング ループを完全に制御でき、研究のニーズに合わせてコードを容易に変更、調整できます。このカスタマイズ性は、他のフレームワークと比較して大きな利点であり、反復的なデータ分析を加速させるうえで非常に重要です。」
- ブランダイス大学コンピュータ サイエンス准教授、NeurIPS シニア エリアチェア、ICLR エリアチェア、Hongfu Liu 氏
「ポスト トレーニングにおける強化学習の主なボトルネックは、検証可能な報酬を持つ環境が少ないことです。ゲーム環境は、これを解決するための最適なマルチターン環境であり、Tunix はこの研究に理想的なフレームワークです。Tunix を使えば、TPU と簡単な並列化を活用して、JAX 上で直接構築できます。Tunix は、他の選択肢と比べて軽量で、コードベースがクリーンかつ管理しやすいライブラリです。過度な抽象化層を持つ他のフレームワークとは異なり、モデルやハイパーパラメータを高度にカスタマイズできます。このような合理化されたアプローチは私たちの研究にとって不可欠であり、JAX の専門家でなくても使いこなせるため、学習曲線も緩やかです。」
- カリフォルニア大学サンディエゴ校准教授、vLLM および Chatbot Arena(LMSys)共同開発者、Disaggregated Serving 発明者、Hao Zhang 氏
Precur AI は、バックグラウンドのワークフローを信頼性が高く効率的なコード駆動型エージェントに変換する Agent Compiler を開発しているスタートアップ企業です。共同設立者兼最高技術責任者の Hanjun Dai 氏は次のように述べています。
「当社は、監督なしで 24 時間年中無休で稼働するバックグラウンド エージェントの開発に取り組んでいます。主な目標はエージェントの堅牢性の向上であり、そのために「エージェント カーネル」と呼ばれる、長期的かつ反復的なタスクに最適化されたモデルのポスト トレーニングを行っています。SFT、RL、蒸留までカバーする Tunix の広範な設計により、エージェント開発スタック全体を一元化できます。さらに、JAX および TPU エコシステムとのネイティブな統合も大きな利点です。Flax を使った開発や、Qwix を用いた量子化モデルのサービングも容易にカスタマイズできるため、クリーンで強力なフレームワークとして、当社のワークフローに非常にスムーズに組み込めます。」
- PreCur AI 共同設立者兼最高技術責任者、Hanjun Dai 氏
Google は、Tunix をオープンに構築しています。ぜひコミュニティに参加して、実際に試し、開発にご協力ください。
Tunix を JAX コミュニティと共有することで、このライブラリからどのようなものが生み出されるのか楽しみにしています。

