在“解析 Gemma”系列的上一篇博文中,我们回顾了 RecurrentGemma 的架构。在本篇博文中,我们将探索 PaliGemma 的架构。让我们一起深入了解一下吧!
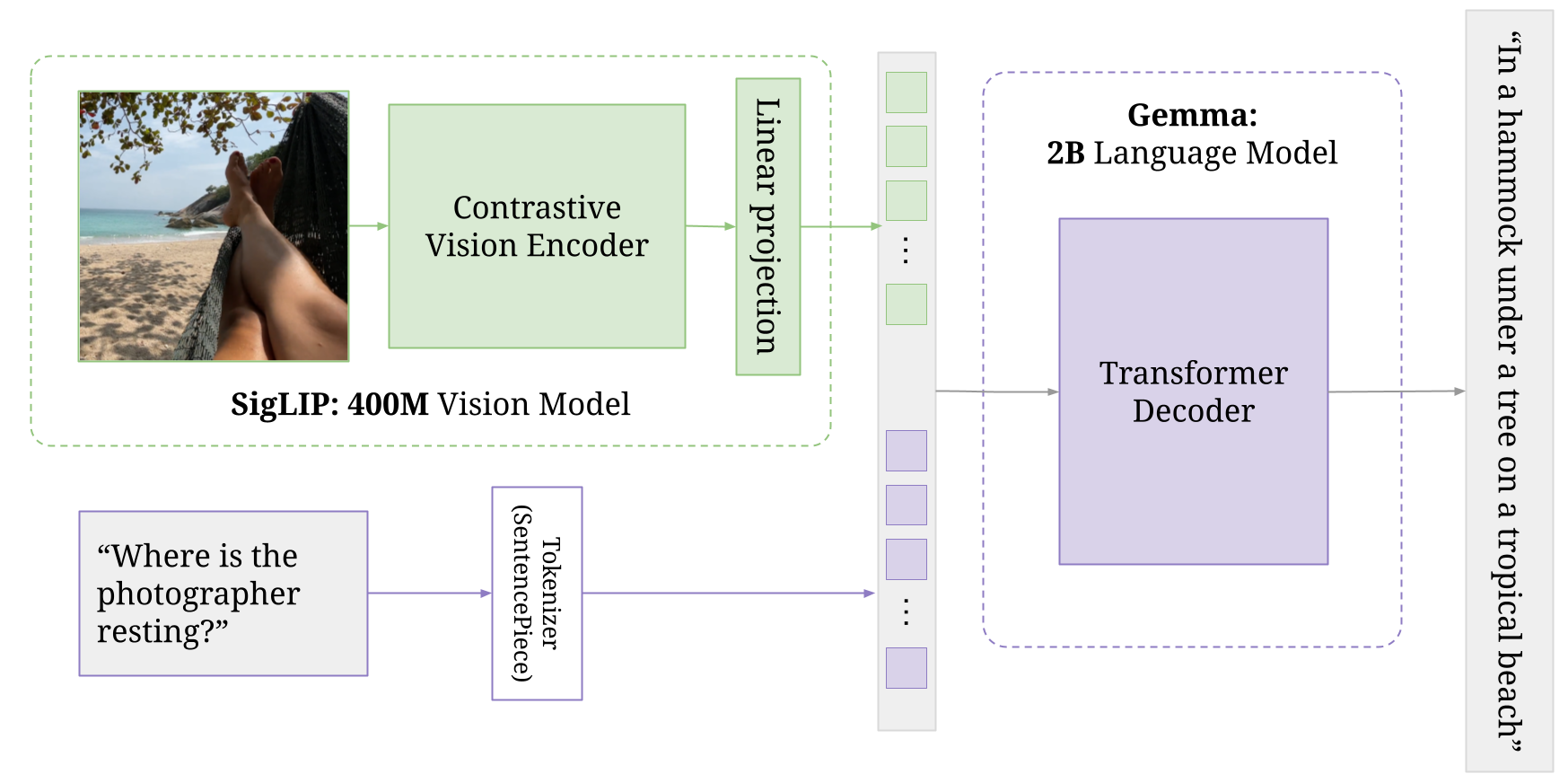
PaliGemma 是一款轻量级开放视觉语言模型 (VLM),基于 SigLIP 视觉模型等开放组件和 Gemma 语言模型开发而成,其灵感源自 PaLI-3。PaLI 代表“Pathway Language and Image Model”。顾名思义,此模型能够同时接收图像和文本输入并产生文本回复,正如您在本微调指南中所看到的那样。
PaliGemma 可为 BaseGemma 模型添加额外视觉模型,该模型包含图像编码器。此编码器会与文本 token 一起传递给专门的 Gemma 2B 模型。视觉模型和 Gemma 模型均经过多个阶段的独立和协同训练,以生成最终的联合架构。有关详细信息,请参阅 Pali-3 论文的第 3.2 节
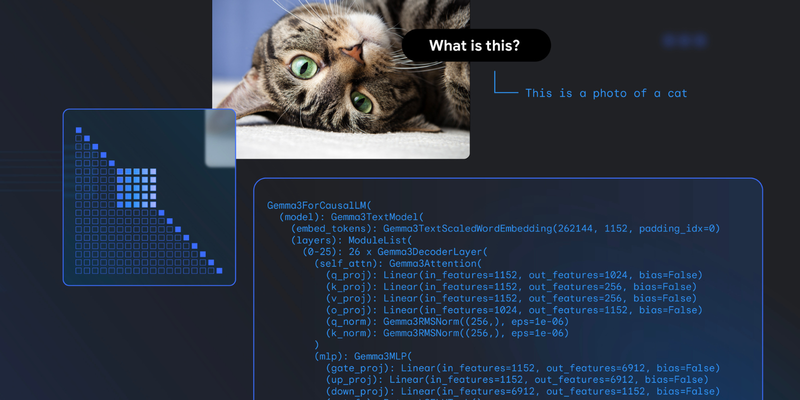
PaliGemmaForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): PaliGemmaMultiModalProjector(
(linear): Linear(in_features=1152, out_features=2048, bias=True)
)
(language_model): GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(257216, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=257216, bias=False)
)
)此组件负责处理输入图像。
它使用 SiglipVisionTransformer,这是一种专为视觉任务设计的 Transformer 架构。
PaliGemma 可将一个或多个图像作为输入接收,然后 SigLIP 编码器会将这些图像转换为“软 token”。
与文本模型处理句中单词的方式类似,该编码器会将图像分解为更小的片段。然后,模型会学习捕捉这些片段之间的关系,从而有效地理解图像的视觉内容。
它使用具有以下参数的卷积层 (Conv2d)。
每个片段嵌入中均会添加位置嵌入,以便编码空间信息(即每个片段在原始图像中的位置)。
这是利用学习嵌入层(嵌入)完成的,该层可将每个片段的位置(最多 256 个位置)作为输入接收,并输出大小为 1152 的向量(与片段嵌入维度相同)。
嵌入会通过一系列 SiglipEncoderLayer,每个 SiglipEncoderLayer 都由自注意力和前馈神经网络组成。这有助于模型捕捉图像不同部分之间的关系。
该组件可将视觉塔的输出投影到多模态空间中。这是利用简单的线性层实现的,线性层支持视觉和语言表征的有效结合。
该组件是基于 Gemma 2B 模型的语言模型。
它可以从投影器获取多模态表征,并将其作为输入接收,然后生成文本输出。
每个检查点都会使用不同的序列长度针对文本输入进行训练。例如,训练 paligemma-3b-mix-224 所使用的序列长度为 256(输入文本 + 经 Gemma 的分词器处理的输出文本)。
PaliGemma 使用具有 256000 token 的 Gemma 分词器,但其词汇扩展了 1024 个条目,这些条目表示归一化图像空间中的坐标 (<loc0000>…<loc1023>),另一轮扩展则包含 128 个条目 (<seg000>…<seg127>),这些条目是轻量级引用表达式分割向量量化的变分自动编码器 (VQ-VAE) 使用的编码词。(256000 + 1024 + 128 = 257216)
其他软 token 则用于编码对象检测和图像分割。以下是 paligemma-3b-mix-224 的输出示例。您可以在 HuggingFace 现场演示中自行尝试。

PaliGemma 的输出,其提示为“segment floor; cat; person;”

如果您不熟悉机器学习和计算机视觉任务,那么模型输出的解码对您来说不会很直观易懂。
最开始的四个位置 token 表示边界框的坐标,其范围为 0 到 1023。这些坐标与宽高比无关,因为图像大小已假定为调整至 1024 x 1024。
例如,输出显示猫的位置位于坐标 (382、637) 和 (696、784) 之间。在该坐标系中,左上角表示为 (0,0),其中垂直坐标列于水平坐标之前。

面具使用以下 16 个分割 token 进行编码。通过解码这些值,神经网络模型 (VQ-VAE) 可以利用量化表征(码本索引)来重建面具。您可以在此处查看实际代码。
最后,您可以通过 PaliGemma 的输出获得这个美丽的成果。

在本文中,您了解了 PaliGemma。
Gemma 系列通过提供一系列具有相似核心架构但旨在支持不同用例的开放式权重模型,为理解现代大型语言模型系统提供了独特的机会。Google 为研究人员、开发者和最终用户发布的这些模型涵盖了各种功能和复杂性。
本概述重点介绍了 Gemma 模型系列的多功能性和适用性,强调该模型系列适用于各种任务,我们希望这有助于您简要了解该模型系列。
Google 开发者社区 Discord 服务器是一个出色的平台,可助您展示项目、与其他开发者建立联系以及参与互动讨论。不妨考虑加入该服务器,了解这些令人兴奋的机会。
感谢您的阅读!