

We are excited to enable developers to seamlessly bring new on-device generative AI models to edge devices. To meet that need, we are announcing the AI Edge Torch Generative API, which allows developers to author high performance LLMs in PyTorch for deployment using the TensorFlow Lite (TFLite) runtime. This is the second in a series of blog posts covering Google AI Edge developer releases. The first post in the series introduced Google AI Edge Torch, which enables high performance inference of PyTorch models on mobile devices using the TFLite runtime.
AI Edge Torch Generative API enables developers to bring powerful new capabilities on-device, such as summarization, content generation, and more. We already enable developers to bring some of the most popular LLMs to devices using the MediaPipe LLM Inference API. We are now excited to enable developers to bring any supported model on device with great performance. The initial version of AI Edge Torch Generative API offers the following:
In this blog post we will deep dive into performance, portability, authoring developer experience, end to end inference pipeline and debug toolchain. Further documentation and examples are available here.
As part of our work to get some of the most popular LLMs working out seamlessly through the MediaPipe LLMInference API, our team authored several fully hand-written transformers with state of the art on device performance (MediaPipe LLM Inference API blog). A few themes emerged from this work: how to represent attention effectively, use of quantization, and the importance of a good KV Cache representation. The Generative API makes each of these easy to express (as we’ll see in the next section), while still achieving performance that’s >90% of our handwritten versions with far greater developer velocity.
The following table shows key benchmarks across 3 model examples:
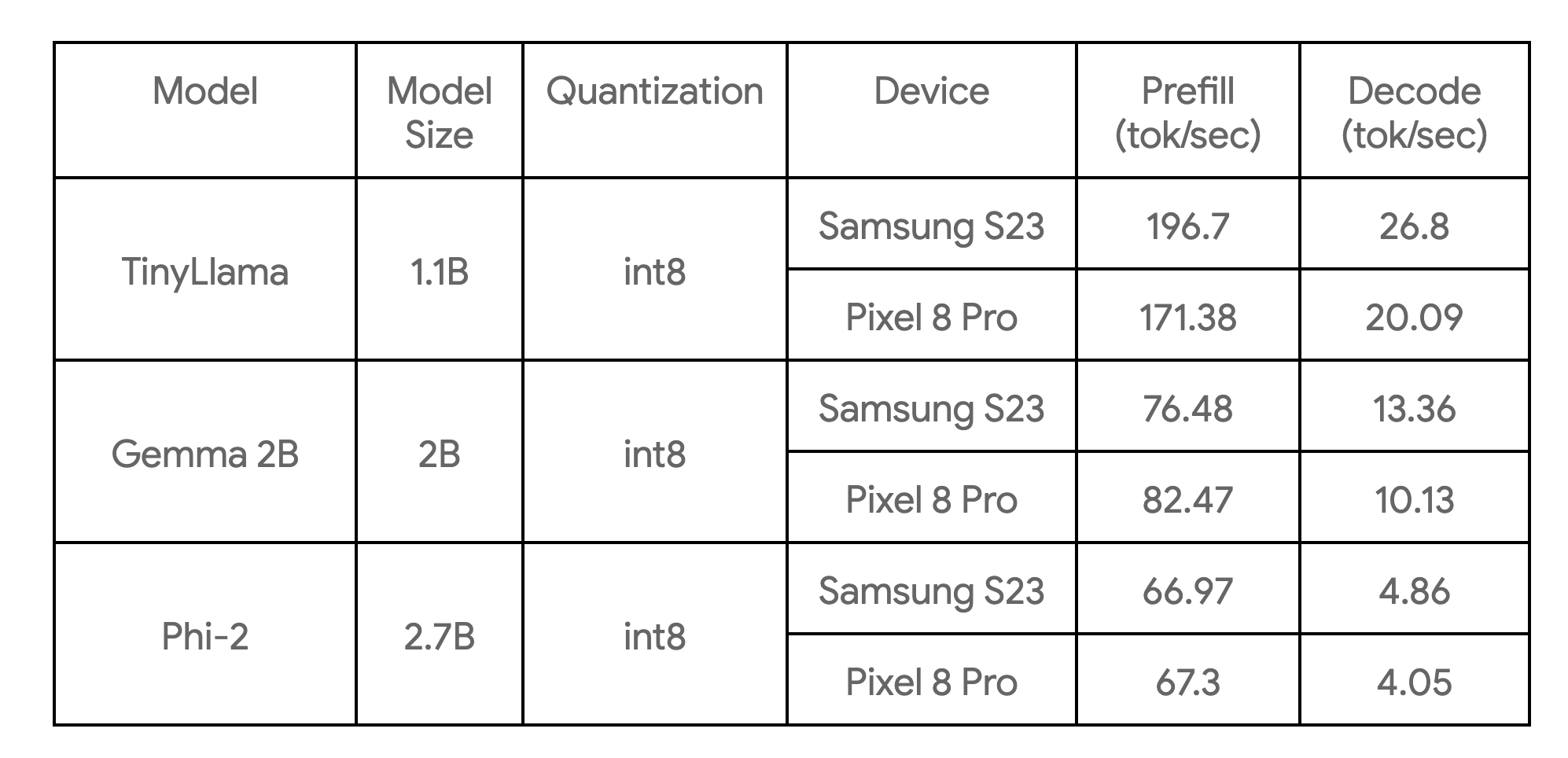
These are benchmarked on big cores, with 4 CPU threads, and are the fastest CPU implementations of these models we are currently aware of on the devices listed.
The core authoring library provides basic building blocks for common transformer models (encoder-only, decoder-only, or encoder-decoder style etc). It allows you to either author a model from scratch, or re-author an existing model for improved performance. We recommend most users to re-author, since it requires no training/fine-tuning steps. The key benefits of the Generative API authoring includes:
As an example, here we showcase how to re-author TinyLLama(1.1B)’s core functionality with around 50 lines of Python with the new Generative API.
Step 1: Define model structure
import torch
import torch.nn as nn
from ai_edge_torch.generative.layers.attention import TransformerBlock
import ai_edge_torch.generative.layers.attention_utils as attn_utils
import ai_edge_torch.generative.layers.builder as builder
import ai_edge_torch.generative.layers.model_config as cfg
class TinyLLamma(nn.Module):
def __init__(self, config: cfg.ModelConfig):
super().__init__()
self.config = config
# Construct model layers.
self.lm_head = nn.Linear(
config.embedding_dim, config.vocab_size, bias=config.lm_head_use_bias
)
self.tok_embedding = nn.Embedding(
config.vocab_size, config.embedding_dim, padding_idx=0
)
self.transformer_blocks = nn.ModuleList(
TransformerBlock(config) for _ in range(config.num_layers)
)
self.final_norm = builder.build_norm(
config.embedding_dim,
config.final_norm_config,
)
self.rope_cache = attn_utils.build_rope_cache(
size=config.kv_cache_max,
dim=int(config.attn_config.rotary_percentage * config.head_dim),
base=10_000,
condense_ratio=1,
dtype=torch.float32,
device=torch.device("cpu"),
)
self.mask_cache = attn_utils.build_causal_mask_cache(
size=config.kv_cache_max, dtype=torch.float32, device=torch.device("cpu")
)
self.config = configStep 2: Define model’s forward function
@torch.inference_mode
def forward(self, idx: torch.Tensor, input_pos: torch.Tensor) -> torch.Tensor:
B, T = idx.size()
cos, sin = self.rope_cache
cos = cos.index_select(0, input_pos)
sin = sin.index_select(0, input_pos)
mask = self.mask_cache.index_select(2, input_pos)
mask = mask[:, :, :, : self.config.kv_cache_max]
# forward the model itself
x = self.tok_embedding(idx) # token embeddings of shape (b, t, n_embd)
for i, block in enumerate(self.transformer_blocks):
x = block(x, (cos, sin), mask, input_pos)
x = self.final_norm(x)
res = self.lm_head(x) # (b, t, vocab_size)
return resStep 3: Map old model weights
The library allows you to map weights easily with the ModelLoader APIs, for example:
import ai_edge_torch.generative.utilities.loader as loading_utils
# This map will associate old tensor names with the new model.
TENSOR_NAMES = loading_utils.ModelLoader.TensorNames(
ff_up_proj="model.layers.{}.mlp.up_proj",
ff_down_proj="model.layers.{}.mlp.down_proj",
ff_gate_proj="model.layers.{}.mlp.gate_proj",
attn_query_proj="model.layers.{}.self_attn.q_proj",
attn_key_proj="model.layers.{}.self_attn.k_proj",
attn_value_proj="model.layers.{}.self_attn.v_proj",
attn_output_proj="model.layers.{}.self_attn.o_proj",
pre_attn_norm="model.layers.{}.input_layernorm",
pre_ff_norm="model.layers.{}.post_attention_layernorm",
embedding="model.embed_tokens",
final_norm="model.norm",
lm_head="lm_head",
)After those steps are done, you can run a few sample inputs to verify numerical correctness (see link) of the re-authored model. If the numerical check is passing, you can proceed to the convert & quantize step.
With the conversion APIs provided by ai_edge_torch, you can leverage the same API to convert (re-authored) transformer models to a highly optimized TensorFlow Lite model. The conversion process contains the following key steps:
1) Export to StableHLO. The PyTorch model is traced and compiled to a FX Graph with Aten ops by the torch dynamo compiler, then lowered to StableHLO graph by ai_edge_torch.
2) ai_edge_torch runs further compiler passes on StableHLO, including op fusion/folding etc, and generates a highly performant TFLite flatbuffer (with fused ops for SDPA, KVCache).
The core Generative API library also provides a set of quantization API which covers common LLM quantization recipes. The recipe is passed an additional parameter to the ai_edge_torch converter API, which automatically covers quantization. In future releases, we expect to expand the set of quantization modes available.
We identified that in real inference scenarios, LLM models need to have clearly separated (disaggregated) inference functions (prefill, decode) to achieve best serving performance. This is partly based on the observation that prefill/decode may take different tensor shapes, prefill is compute-bound whereas decode is memory bound. For large LLMs, it’s critical to avoid duplicating model weights between prefill/decode. We achieve this using the existing multi-signature feature in TFLite and ai_edge_torch that let you easily define multiple entry points for the model as shown below.
def convert_tiny_llama_to_tflite(
prefill_seq_len: int = 512,
kv_cache_max_len: int = 1024,
quantize: bool = True,
):
pytorch_model = tiny_llama.build_model(kv_cache_max_len=kv_cache_max_len)
# Tensors used to trace the model graph during conversion.
prefill_tokens = torch.full((1, prefill_seq_len), 0, dtype=torch.long)
prefill_input_pos = torch.arange(0, prefill_seq_len)
decode_token = torch.tensor([[0]], dtype=torch.long)
decode_input_pos = torch.tensor([0], dtype=torch.int64)
# Set up Quantization for model.
quant_config = quant_recipes.full_linear_int8_dynamic_recipe() if quantize else None
edge_model = (
ai_edge_torch.signature(
'prefill', pytorch_model, (prefill_tokens, prefill_input_pos)
)
.signature('decode', pytorch_model, (decode_token, decode_input_pos))
.convert(quant_config=quant_config)
)
edge_model.export(f'/tmp/tiny_llama_seq{prefill_seq_len}_kv{kv_cache_max_len}.tflite')During our performance investigation phase, we found a few critical aspects for improving LLM performance:
1) High-performant SDPA and KVCache: we found that without enough compiler optimizations / fusions, the converted TFLite model will not have great performance, given the granular ops in these functions. To address this, we introduced high-level function boundary and StableHLO composite ops
2) Leveraging TFLite’s XNNPack delegate to further accelerate SDPA: it’s critical to ensure heavy MatMul/Matrix-vector computations are well optimized. The XNNPack library has excellent performance for these primitives across a broad range of mobile CPUs.
3) Avoiding wasteful computations: static shape models can induce more compute than is minimally required if models have long fixed input message size in prefill stage or large fixed sequence length in decode stage.
4) Runtime memory consumption. We introduced a weight caching / pre-packing mechanism in TFLite’s XNNPack delegate to significantly lower the peak memory usage.
LLM inference typically involves many pre/post-processing steps and sophisticated orchestration, e.g. Tokenization, sampling and autoregressive decoding logic. To this end, we provide both the MediaPipe-based solutions and a pure C++ inference example.
The MediaPipe LLM Inference API is a high-level API which supports LLM Inference using a prompt-in/prompt-out interface. It takes care of all the complexity of implementing the LLM pipeline under the hood, and makes deployment much easier and fluent. To deploy using the MP LLM Inference API, you need to ensure you convert models using the expected prefill and decode signatures, and create a bundle as shown in the code below:
def bundle_tinyllama_q8():
output_file = "PATH/tinyllama_q8_seq1024_kv1280.task"
tflite_model = "PATH/tinyllama_prefill_decode_hlfb_quant.tflite"
tokenizer_model = "PATH/tokenizer.model"
config = llm_bundler.BundleConfig(
tflite_model=tflite_model,
tokenizer_model=tokenizer_model,
start_token="<s>",
stop_tokens=["</s>"],
output_filename=output_file,
enable_bytes_to_unicode_mapping=False,
)
llm_bundler.create_bundle(config)We also provide you with an easy-to-use C++ example (without MediaPipe dependency) to showcase how to run an end-to-end text generation example. Developers can use this example as a starting point for integrating the exported models with their unique production pipelines and requirements, which enables better customization and flexibility.
Since the core inference runtime is in TFLite, the whole pipeline can be easily integrated into your Android (included in Google Play) or iOS apps without any modifications. This will ensure the models converted from the new Generative API will be immediately deployable by just adding a few custom op dependencies. In future releases, we will bring GPU support for both Android & iOS, and target ML accelerators (TPU, NPU) as well.
The recently announced Model Explorer is a useful tool for visualizing large models such as Gemma 2B. Hierarchical viewing and side by side comparison makes it easy to visualize original / reauthored / converted model versions. For more details on this and how you can visualize benchmark info for performance tuning, check out this blog post.
Below is an example of how we used this when authoring the PyTorch TinyLlama model – showing the PyTorch export() model alongside the TFLite model. Using Model Explorer, we can easily compare how each layer (e.g. RMSNorms, SelfAttention) is expressed.
The AI Edge Torch Generative API is a powerful companion to prebuilt optimized models available in Mediapipe LLM inference API for developers who want to enable their own generative AI models on device. In the coming months expect new updates including web support, improved quantization and wider compute support beyond CPU. We’re also interested in exploring even better framework integration.
This is an early preview of the library, which is in an experimental stage with the goal of engaging with the developer community. Please expect APIs to change, rough edges, and limited support for quantization and models. But there’s plenty to get started with already in our GitHub repo - jump in and feel free to share PRs, issues, and feature requests.
In part 3 of this series, we’ll take a deeper look at the Model Explorer visualization tool that enables developers to visualize, debug and explore models.
This work is a collaboration across multiple functional teams at Google. We’d like to thank all team members who contributed to this work: Aaron Karp, Advait Jain, Akshat Sharma, Alan Kelly, Andrei Kulik, Arian Afaian, Chun-nien Chan, Chuo-Ling Chang, Cormac Brick, Eric Yang, Frank Barchard, Gunhyun Park, Han Qi, Haoliang Zhang, Ho Ko, Jing Jin, Joe Zoe, Juhyun Lee, Kevin Gleason, Khanh LeViet, Kris Tonthat, Kristen Wright, Lin Chen, Linkun Chen, Lu Wang, Majid Dadashi, Manfei Bai, Mark Sherwood, Matthew Soulanille, Matthias Grundmann, Maxime Brénon, Michael Levesque-Dion, Mig Gerard, Milen Ferev, Mohammadreza Heydary, Na Li, Paul Ruiz, Pauline Sho, Pei Zhang, Ping Yu, Pulkit Bhuwalka, Quentin Khan, Ram Iyengar, Renjie Wu, Rocky Rhodes, Sachin Kotwani, Sandeep Dasgupta, Sebastian Schmidt, Siyuan Liu, Steven Toribio, Suleman Shahid, Tenghui Zhu, T.J. Alumbaugh, Tyler Mullen, Weiyi Wang, Wonjoo Lee, Yi-Chun Kuo, Yishuang Pang, Yu-hui Chen, Zoe Wang, Zichuan Wei.

LiteRT: Maximum performance, simplified

Developer’s Guide to Building ADK Agents with Skills

A2UI v0.9: The New Standard for Portable, Framework-Agnostic Generative UI

New enhancements for merchant initiated transactions with the Google Pay API

On-device small language models with multimodality, RAG, and Function Calling