Modern smartphones feature sophisticated SoCs (system on a chip), composed of CPU, GPU, and NPU, which can enable compelling, on-device GenAI experiences that are significantly more interactive and real-time than their server-only counterparts. The GPU is the most ubiquitous accelerator for AI tasks, with GPU compute being available on roughly 90% of all Android devices. However, solely relying on it can create performance bottlenecks, especially when building complex, interactive GenAI experiences. Consider the following setting: running a compute-intensive, text-to-image generation model on-device, while simultaneously processing the live camera feed with an ML-based segmentation. Even the most powerful mobile GPU will struggle under this combined load, resulting in jarring frame drops and a broken user experience.
This is where the NPU (Neural Processing Unit) comes in. It’s a highly specialized processor that offers tens of TOPS (Tera Operations Per Second) of dedicated AI compute, far more than a modern, mobile GPU can sustain. Crucially, it is significantly more power-efficient per TOP than both CPUs and GPUs, which is essential for battery-operated devices like mobile phones. The NPU is no longer a niche feature; it's a standard component, with over 80% of recent Qualcomm SoCs now including one. The NPU runs parallel to the GPU and CPU, enabling the heavy AI processing. This concurrency frees the GPU to focus on rendering and the CPU on main-thread logic. This modern architecture unlocks the smooth, responsive, and fast performance that modern AI applications demand.

To bring this NPU power to LiteRT, Google’s high-performance on-device ML framework, we are thrilled to announce a significant leap forward: the LiteRT Qualcomm AI Engine Direct (QNN) Accelerator, developed in close collaboration with Qualcomm, replacing the previous TFLite QNN delegate.
This update introduces two major advantages for developers:
1. A unified and simplified mobile deployment workflow that frees Android app developers from the biggest complexities of NPU acceleration. You no longer need to:
You can now deploy your model seamlessly across all supported devices, with either ahead-of-time (AOT) or on-device compilation. This makes integrating pre-trained .tflite models in production from sources like Qualcomm AI Hub easier than ever.
2. State-of-the-Art on-device performance. The accelerator supports an extensive range of LiteRT ops, enabling maximum NPU usage and full model delegation, a critical factor for securing the best performance. Furthermore, it is packed with the specialized kernels and optimizations required for sophisticated LLMs and GenAI models, achieving SOTA performance for models like Gemma and FastVLM.
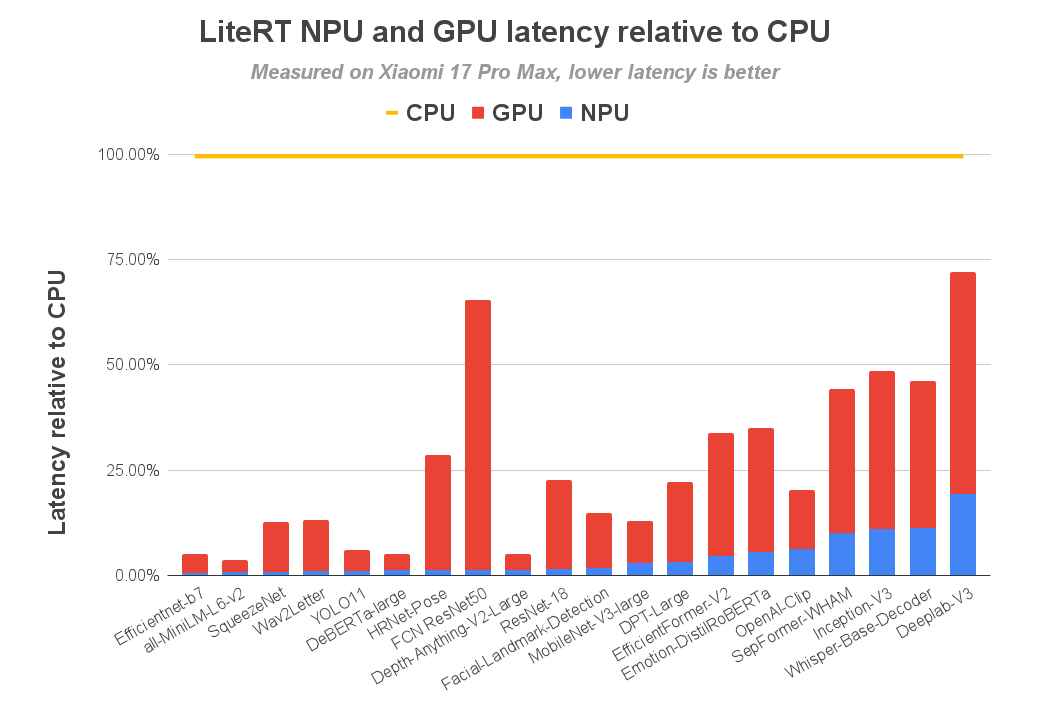
We benchmarked the new LiteRT QNN accelerator across 72 canonical ML models, encompassing vision, audio, and NLP domains. The results show a massive jump in raw performance: the NPU acceleration provides up to a 100x speedup over CPU and a 10x speedup over GPU. Our new accelerator enables this by supporting 90 LiteRT ops, allowing 64 of the 72 models to delegate fully to the NPU.
This speed translates to real interactive performance. On Qualcomm’s latest flagship SoC, the Snapdragon 8 Elite Gen 5, the performance benefit is substantial: over 56 models run in under 5ms with the NPU, while only 13 models achieve that on the CPU. This unlocks a host of live AI experiences that were previously unreachable.
Here is a selection of 20 representative models from the benchmark:
The LiteRT QNN Accelerator exhibits cutting-edge performance with sophisticated LLMs. To demonstrate this, we benchmarked the FastVLM-0.5B research model, a state-of-the-art vision model for on-device AI, using LiteRT for both AOT compilation and on-device NPU inference.
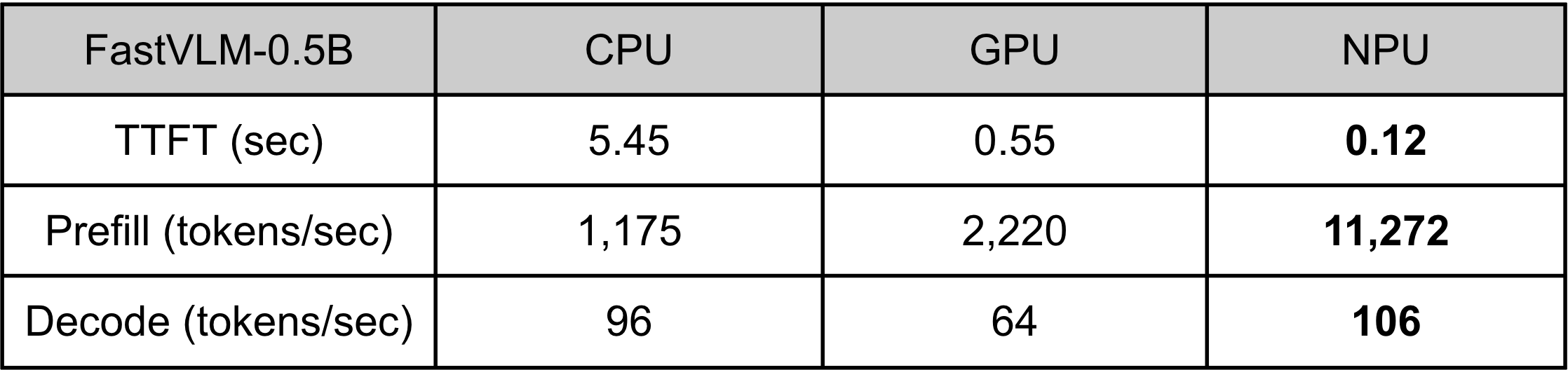
The model is optimized with int8 weight quantization and int16 activation quantization. This is the key to unlocking the NPU’s most powerful, high-speed int16 kernels. We also went beyond simple delegation and added special NPU kernels for performance-critical transformer layers to the LiteRT QNN Accelerator, particularly for the Attention mechanism, ensuring these layers run efficiently.
This delivers a level of performance that creates an AI experience rarely seen on mobile devices. Running on the Snapdragon 8 Elite Gen 5 NPU, our FastVLM integration delivers time-to-first-token (TTFT) in just 0.12 second on high-resolution images (1024x1024). It achieves over 11,000 tokens/sec for prefill and over 100 tokens/sec for decode. This extreme throughput is what makes a smooth, real-time, interactive experience possible. To showcase this, we built a live scene understanding demo that processes and describes the world around you.
Here’s how simple it is to deploy a .tflite model on NPU across different Qualcomm SoC versions using the unified workflow with LiteRT. Pre-trained production-quality .tflite models can be downloaded from sources like Qualcomm AI Hub.
Step 1: (optional) AOT Compilation for the target SoCs with LiteRT
While pre-compiling your .tflite model offline (AOT) is optional, we highly recommend it for large models where on-device compilation can result in longer initialization times and higher peak memory consumption.
You can compile for all supported SoCs or target specific SoC versions using LiteRT on the host in a few lines of Python code:
from ai_edge_litert.aot import aot_compile as aot_lib
from ai_edge_litert.aot.vendors.qualcomm import target as qnn_target
# --- Compile to all available SoCs ---
compiled_models = aot_lib.aot_compile(tflite_model_path)
# --- Or, compile to specific Qualcomm SoC versions ---
# Example: Targeting Qualcomm Snapdragon 8 Elite Gen5 Mobile Platform (SM8850)
sm8850_target = qnn_target.Target(qnn_target.SocModel.SM8850)
compiled_models = aot_lib.aot_compile(
tflite_model_path,
target=[sm8850_target]
)After compilation, export your compiled models across target SoCs into a single Google Play AI Pack. You then upload this pack to Google Play, which uses Play for On-device AI (PODAI) to automatically deliver the correct compiled models to each users' devices.
from ai_edge_litert.aot.ai_pack import export_lib as ai_pack_export
# --- Export the AI Pack ---
# This bundles model variants and metadata so Google Play can
# deliver the correct compiled model to the right device.
ai_pack_export.export(
compiled_models,
ai_pack_dir,
ai_pack_name,
litert_model_name
)See a full example in the LiteRT AOT compilation notebook.
Step 2: Deploy to the target SoCs with Google Play for On-device AI
Add your model to the Android app project. You have two distinct options depending on your chosen workflow:
// my_app/settings.gradle.kts
...
include(":ai_pack:my_model")
// my_app/app/build.gradle.kts
android {
...
assetPacks.add(":ai_pack:my_model")
}Next, run the script to fetch the QNN libraries. This downloads NPU runtime (for both AOT and on-device compilation) and the compiler library (essential for on-device compilation).
# Download and unpack NPU runtime libraries to the root directory.
# For AOT compilation, download litert_npu_runtime_libraries.zip.
# For on-device compilation, download litert_npu_runtime_libraries_jit.zip.
$ ./litert_npu_runtime_libraries/fetch_qualcomm_library.shAdd NPU runtime libraries as feature modules to the gradle configuration:
// my_app/settings.gradle.kts
include(":litert_npu_runtime_libraries:runtime_strings")
include(":litert_npu_runtime_libraries:qualcomm_runtime_v79")
...
// my_app/app/build.gradle.kts
android {
dynamicFeatures.add(":litert_npu_runtime_libraries:qualcomm_runtime_v79")
...
}
dependencies {
// Strings for NPU runtime libraries
implementation(project(":litert_npu_runtime_libraries:runtime_strings"))
...
}For a complete guide on configuring your app for Play for On-device AI, please refer to this tutorial.
Step 3: Inference on NPU using LiteRT Runtime API
LiteRT abstracts away the complexity of developing against specific SoC versions, letting you run your model on the NPU with just a few lines of code. It also provides a robust, built-in fallback mechanism: you can specify CPU, GPU, or both as options, and LiteRT will automatically use them if the NPU is unavailable. Conveniently, AOT compilation also supports fallback. It provides partial delegation on NPU where unsupported subgraphs seamlessly run on CPU or GPU as specified.
// 1. Load model and initialize runtime.
// If NPU is unavailable, inference will fallback to GPU.
val model =
CompiledModel.create(
context.assets,
"model/mymodel.tflite",
CompiledModel.Options(Accelerator.NPU, Accelerator.GPU)
)
// 2. Pre-allocate input/output buffers
val inputBuffers = model.createInputBuffers()
val outputBuffers = model.createOutputBuffers()
// 3. Fill the first input
inputBuffers[0].writeFloat(...)
// 4. Invoke
model.run(inputBuffers, outputBuffers)
// 5. Read the output
val outputFloatArray = outputBuffers[0].readFloat()Check out our image segmentation sample app of how to use all the features
The new LiteRT Qualcomm AI Engine Direct (QNN) Accelerator is a major achievement for LiteRT, closing the gap between raw hardware potential and real-world application performance. We're incredibly excited to see what you build with this power.
We encourage you to explore our LiteRT DevSite and our LiteRT Github repository. Happy building!
Special thanks to the Google ODML team and Qualcomm team for their significant contributions in this effort:
Google ODML team: Alice Zheng, Advait Jain, Andrew Zhang, Arian Arfaian, Chintan Parikh, Chunlei Niu, Cormac Brick, Gerardo Carranza, Gregory Karpiak, Jingjiang Li, Jing Jin, Julius Kammerl, Lu Wang, Luke Boyer, Marissa Ikonomidis, Maria Lyubimtseva, Matt Kreileder, Matthias Grundmann, Na Li, Ping Yu, Quentin Khan, Rishika Sinha, Sachin Kotwani, Sebastian Schmidt, Steven Toribio, Teng-Hui Zhu, Terry (Woncheol) Heoi, Vitalii Dziuba, Weiyi Wang, Yu-Hui Chen, Zichuan We
Qualcomm LiteRT team: Alen Huang, Bastiaan Aarts, Brett Taylor, Chun-Hsueh Lee (Jack), Chun-Po Chang (Jerry), Chun-Ting, Lin (Graham), Felix Baum, Jiun-Kai Yang (Kelvin), Krishna Sridhar, Ming-Che Lin (Vincent), William Lin