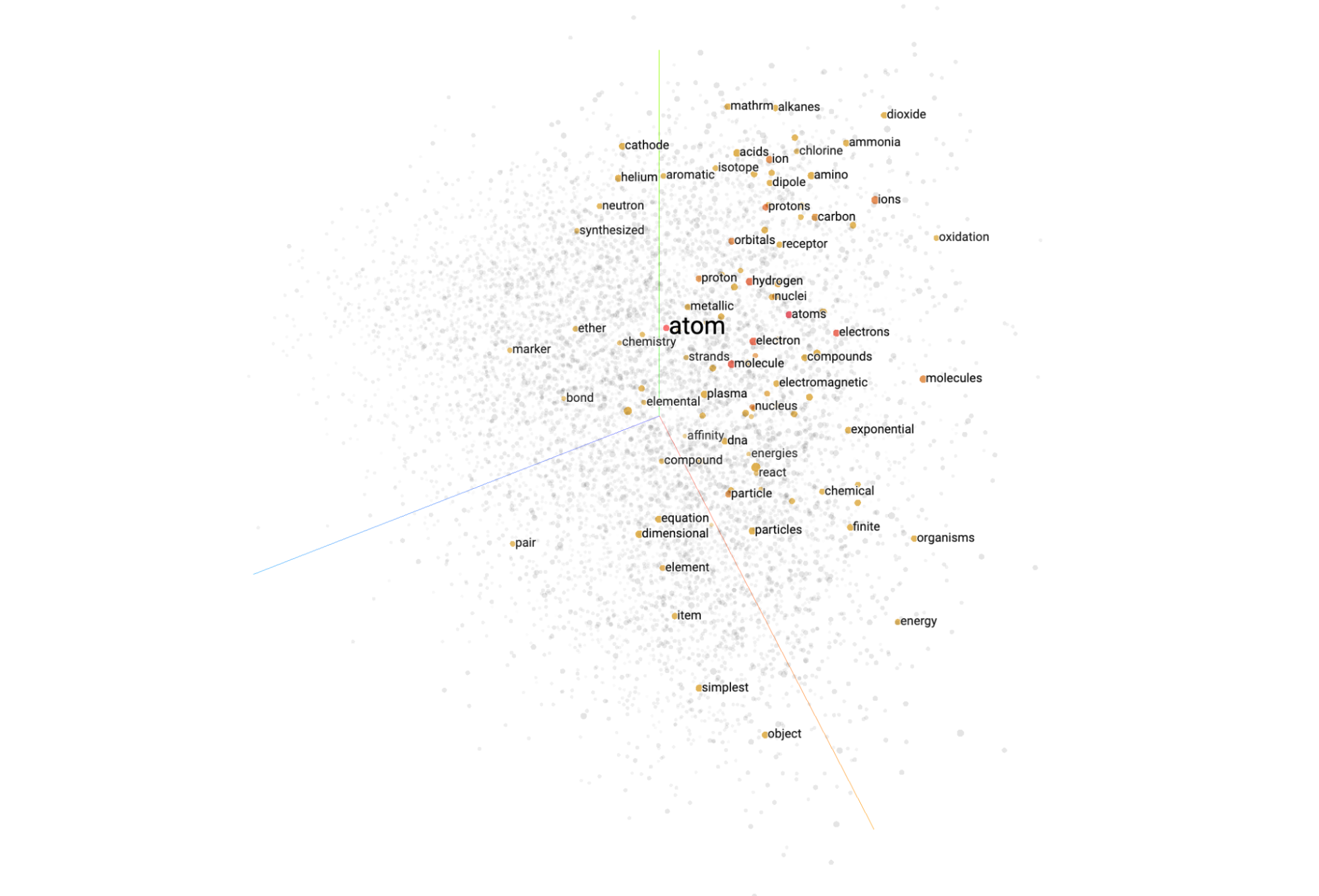
Vector embeddings are a way to represent real-world data – like text, images, or audio – mathematically, as points in a multidimensional map. This sounds incredibly dry, but with enough dimensions, they allow computers (and by extension, us) to uncover and understand the relationships in that data.
For instance, you might remember "word2vec." It was a revolutionary technique developed by Google in 2013 that transformed words into numerical vectors, unlocking the power of semantic understanding for machines. This breakthrough paved the way for countless advancements in natural language processing, from machine translation to sentiment analysis.
We then built upon this foundation with the release of a powerful text embedding model called text-gecko, enabling developers to explore the rich semantic relationships within text.
The Vertex Multimodal Embeddings API takes this a step further, by allowing you to represent text, images, and video into that same shared vector space, preserving contextual and semantic meaning across different modalities.
In this post, we'll explore two practical applications of this technology: searching all of the slides and decks our team has made in the past 10 years, and an intuitive visual search tool designed for artists. We'll dive into the code and share practical tips on how you can unlock the full potential of multimodal embeddings.
Recently, our team was exploring how we might explore the recently released Multimodal Embeddings API. We recognized its potential for large corporate datasets, and we were also eager to explore more personal and creative applications.
Khyati, a designer on our team who’s also a prolific illustrator, was particularly intrigued by how this technology could help her better manage and understand her work. In her words:
"Artists often struggle to locate past work based on visual similarity or conceptual keywords. Traditional file organization methods simply aren't up to the task, especially when searching by uncommon terms or abstract concepts."
And so, our open source multimodal-embeddings demo was born!
While Khyati's dataset was considerably smaller than the million-document scale referenced in the Multimodal Embeddings API documentation, it provided an ideal test case for the new Cloud Firestore Vector Search, announced at Google Cloud Next in April.
So we set up a Firebase project and sent approximately 250 of Khyati’s illustrations to the Multimodal Embeddings API. This process generated 1408-dimensional float array embeddings (providing maximum context), which we then stored in our Firestore database:
mm_embedding_model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
# create embeddings for each image:
embedding = mm_embedding_model.get_embeddings(
image=image,
dimension=1408,
)
# create a Firestore doc to store and add to a collection
doc = {
"name": "Illustration 1",
"imageEmbedding": Vector(embedding.image_embedding),
... # other metadata
}
khyati_collection.add(doc)Make sure to index the imageEmbedding field with the Firestore CLI .
This code block was shortened for brevity, check out this notebook for a complete example. Grab the embedding model from the vertexai.vision_models package
Searching with Firestore's K-nearest neighbors (KNN) vector search is straightforward. Embed your query (just like you embedded the images) and send it to the API:
// Our frontend is typescript but we have access to the same embedding API:
const myQuery = 'fuzzy'; // could also be an image
const myQueryVector = await getEmbeddingsForQuery(myQuery); // MM API call
const vectorQuery: VectorQuery = await khyati_collection.findNearest({
vectorField: 'imageEmbedding', // name of your indexed field
queryVector: myQueryVector,
limit: 10, // how many documents to retrieve
distanceMeasure: 'DOT_PRODUCT' // one of three algorithms for distance
});That's it! The findNearest method returns the documents closest to your query embedding, along with all associated metadata, just like a standard Firestore query.
You can find our demo/searchimplementation here. Notice how we’re using the@google-cloud/firestoreNPM library, which is the current home of this technology, as opposed to the normalfirebaseNPM package.
If you’ve made it this far and still don’t really understand what these embedding vectors look like, that's understandable – we didn't either, at the start of this project.. We exist in a three-dimensional world, so 1408-dimensional space is pretty sci-fi.
Luckily, there are lots of tools available to reduce the dimensionality of these vectors, including a wonderful implementation by the folks at Google PAIR called UMAP. Similar to t-SNE, you can take your multimodal embedding vectors and visualize them in three dimensions easily with UMAP. We’ve included the code to handle this on GitHub, including an open-source dataset of weather images and their embeddings that should be plug-and-play.
While building Khyati’s demo, we were also exploring how to flex the Multimodal Embeddings API’s muscles at its intended scale. It makes sense that Google excels in the realm of embeddings – after all, similar technology powers many of our core search products.
But how could we test it at scale? Turns out, our team's equally prolific deck creation offered an excellent proving ground. We're talking about thousands of Google Slides presentations accumulated over the past decade. Think of it as a digital archaeological dig into the history of our team's ideas.
The question became: could the Multimodal Embeddings API unearth hidden treasures within this vast archive? Could our team leads finally locate that long-lost "what was that idea, from the sprint about the thing, someone wrote it on a sticky note?"? Could our designers easily rediscover That Amazing Poster everyone raved about? Spoiler alert: yes!
The bulk of our development time was spent wrangling the thousands of presentations and extracting thumbnails for each slide using the Drive and Slides APIs. The embedding process itself was nearly identical to the artist demo and can be summarized as follows:
for preso in all_decks:
for slide in preso.slides:
thumbnail = slides_api.getThumbnail(slide.id, preso.id)
slide_embedding = mm_embedding_model.get_embeddings(
image=thumbnail,
dimension=1408,
)
# store slide_embedding.image_embedding in a documentThis process generated embeddings for over 775,000 slides across more than 16,000 presentations. To store and search this massive dataset efficiently, we turned to Vertex AI's Vector Search, specifically designed for such large-scale applications.
Vertex AI's Vector Search, powered by the same technology behind Google Search, YouTube, and Play, can search billions of documents in milliseconds. It operates on similar principles to the Firestore approach we used in the artist demo, but with significantly greater scale and performance.
In order to take advantage of this incredible powerful technology, you’ll need to complete a few extra steps prior to searching:
# Vector Search relies on Indexes, created via code or UI, so first make sure your embeddings from the previous step are stored in a Cloud bucket, then:
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = 'my_index_name',
contents_delta_uri = BUCKET_URI,
dimensions = 1408, # use same number as when you created them
approximate_neighbors_count = 10, #
)
# Create and Deploy this Index to an Endpoint
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = "my_endpoint_name",
public_endpoint_enabled = True
)
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = "my_deployed_index_id"
)
# Once that's online and ready, you can query like before from your app!
response = my_index_endpoint.find_neighbors(
deployed_index_id = "my_deployed_index_id",
queries = [some_query_embedding],
num_neighbors = 10
)The process is similar to Khyati's demo, but with a key difference: we create a dedicated Vector Search Index to unleash the power of ScaNN, Google's highly efficient vector similarity search algorithm.
Now that you’ve seen both options, let’s dive into their differences.
You might have noticed that there were two types of algorithms associated with each vector search service: K-nearest neighbor for Firestore and ScaNN for the Vertex AI implementation. We started both demos working with Firestore as we don’t typically work with enterprise-scale solutions in our team’s day-to-day.
But Firestore’s KNN search is a brute force O(n) algorithm, meaning it scales linearly with the amount of documents you add to your index. So once we started breaking 10-, 15-, 20-thousand document embeddings, things began to slow down dramatically.
This slow down can be mitigated, though, with Firestore’s standard query predicates used in a “pre-filtering” step. So instead of searching through every embedding you’ve indexed, you can do a where query to limit your set to only relevant documents. This does require another composite index on the fields you want to use to filter.
# creating additional indexes is easy, but still needs to be considered
gcloud alpha firestore indexes composite create
--collection-group=all_slides
--query-scope=COLLECTION
--field-config=order=ASCENDING,field-path="project" # additional fields
--field-config field-path=slide_embedding,vector-config='{"dimension":"1408", "flat": "{}"}'Similar to KNN, but relying on intelligent indexing based on the “approximate” locations (as in “Scalable Approximate Nearest Neighbor”), ScaNN was a Google Research breakthrough that was released publicly in 2020.
Billions of documents can be queried in milliseconds, but that power comes at a cost, especially compared to Firestore read/writes. Plus, the indexes are slim by default — simple key/value pairs — requiring secondary lookups to your other collections or tables once the nearest neighbors are returned. But for our 775,000 slides, a ~100ms lookup + ~50ms Firestore read for the metadata was still orders of magnitude faster than what Cloud Firestore Vector Search could provide natively.
There’s also some great documentation on how to combine the vector search with traditional keyword search in an approach called Hybrid Search. Read more about that here.
Quick formatting aside
Creating indexes for Vertex AI also required a separatejsonlkey/value file format, which took some effort to convert from our original Firestore implementation. If you are unsure which to use, it might be worth writing the embeddings to an agnostic format that can easily be ingested by either system, as to not deal with the relative horror of LevelDB Firestore exports.
If a fully Cloud-hosted solution isn’t for you, you can still harness the power of the Multimodal Embeddings API with a local solution.
We also tested a new library called sqlite-vec, an extremely fast, zero dependency implementation of sqlite that can run almost anywhere, and handles the 1408-dimension vectors returned by the Multimodal Embeddings API with ease. Porting over 20,000 of our slides for a test showed lookups in the ~200ms range. You’re still creating document and query embeddings online, but can handle your searching wherever you need to once they are created and stored.
From the foundations of word2vec to today's Multimodal Embeddings API, there are new exciting possibilities for building your own multimodal AI systems to search for information.
Choosing the right vector search solution depends on your needs. Firebase provides an easy-to-use and cost-effective option for smaller projects, while Vertex AI offers the scalability and performance required for large datasets and millisecond search times. For local development, tools like sqlite-vec allow you to harness the power of embeddings mostly offline.
Ready to explore the future of multimodal search? Dive into our open-source multimodal-embeddings demo on GitHub, experiment with the code, and share your own creations. We're excited to see what you build.

Run Ray on TPU, Part 1: The foundations

Expanding Choice in Gemini Enterprise Agent Platform: Introducing Grounding with Parallel Web Search

ML Development in VS Code with Google Cloud Power: Workbench Extension Now Available

We terminated a TPU mid-training and it recovered in seconds: Introduction to elastic training with MaxText