벡터 임베딩은 텍스트, 이미지 또는 오디오 같은 실제 데이터를 수학적으로 다차원 맵에 점으로 표현하는 방법입니다. 너무 건조하게 들리겠지만 차원 수가 충분하면 벡터 임베팅을 통해 컴퓨터는 (더 나아가 우리 사람도) 그러한 데이터의 관계를 파악하고 이해할 수 있습니다.
여러분이 기억하실지도 모를 'word2vec'을 예로 들 수 있습니다. word2vec은 Google이 2013년에 개발한 혁신적인 기술로서, 단어를 숫자형 벡터로 변환하여 컴퓨터가 시맨틱 이해력을 발휘할 수 있도록 했습니다. 이 획기적인 기술은 기계 번역부터 감정 분석에 이르기까지 자연어 처리에 있어 수없이 많은 발전을 이룰 수 있는 길을 열어 주었습니다.
그 이후로 저희는 개발자가 텍스트 내에서 풍부한 시맨틱 관계를 탐색할 수 있도록 text-gecko라는 강력한 텍스트 임베딩 모델을 출시하며 이러한 기반을 더욱 공고히 다졌습니다.
Vertex Multimodal Embeddings API는 이를 한 단계 더 발전시켜 텍스트, 이미지, 동영상을 동일한 공유 벡터 공간에 표현하고 다양한 모달리티에서 맥락상 의미와 시맨틱 의미를 보존할 수 있게 합니다.
이 게시물에서는 이 기술의 두 가지 실용적인 응용 분야를 살펴보겠습니다. 하나는 지난 10년간 우리 팀이 만든 모든 슬라이드 및 덱 검색이고 다른 하나는 아티스트용으로 설계된 직관적인 시각적 검색 도구입니다. 코드를 살펴보고 멀티모달 임베딩의 잠재력을 최대한 활용할 방법에 대한 실용적인 팁을 공유하겠습니다.
최근 우리 팀은 얼마 전 출시된 Multimodal Embeddings API를 탐색할 방법을 모색 중이었습니다. 대규모의 기업 데이터 세트에 대해 이 API가 지닌 잠재력을 깨달았고 더 개인적이고 창의적인 응용 방법을 탐구하고 싶은 마음도 있었습니다.
많은 작품을 완성한 일러스트레이터이기도 한 우리 팀 디자이너 Khyati는 이 기술이 어떤 방식으로 자신의 작품을 더 잘 관리하고 이해하는 데 도움이 될 수 있을지에 특히 관심이 많았습니다. 그녀는 이렇게 말했습니다.
"아티스트들은 시각적 유사성이나 개념적 키워드를 기반으로 과거 작품을 찾는 데 어려움을 겪을 때가 많아요. 특히 흔치 않은 용어나 추상적인 개념으로 작품을 검색할 때는 전통적인 파일 정리 방식으로는 이내 한계에 봉착하죠."
그래서 저희가 만든 것이 바로 오픈소스 멀티모달 임베딩 데모입니다!
Khyati의 데이터 세트는 Multimodal Embeddings API 설명서에 언급된 백만 건 규모의 문서보다 훨씬 작았지만, 지난 4월 Google Cloud Next에서 선보인 새로운 Cloud Firestore 벡터 검색에 이상적인 테스트 사례를 제공했습니다.
그래서 저희는 Firebase 프로젝트를 설정하고 Khyati의 삽화 중 약 250개를 Multimodal Embeddings API로 보냈습니다. 이 프로세스를 통해 1,408차원의 부동 소수점 배열 임베딩(최대 컨텍스트 제공)을 생성한 다음 Firestore 데이터베이스에 저장했습니다.
mm_embedding_model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
# 각 이미지에 대한 임베딩 생성:
embedding = mm_embedding_model.get_embeddings(
image=image,
dimension=1408,
)
# 저장할 Firestore 문서를 만들어 컬렉션에 추가
doc = {
"name": "Illustration 1",
"imageEmbedding": Vector(embedding.image_embedding),
... # 기타 메타데이터
}
khyati_collection.add(doc)Firestore CLI로 imageEmbedding 필드를 인덱싱해야 합니다.
이 코드 블록은 간결함을 위해 단축되었습니다. 완전한 예제는 이 노트북 에서 확인하세요. 임베딩 모델의 출처: vertexai.vision_models 패키지
Firestore의 K-최근접 이웃(KNN: K-nearest neighbors) 벡터 검색을 이용한 검색 방법은 간단합니다. 이미지를 삽입하는 것처럼 쿼리를 삽입하고 API로 전송하면 됩니다.
// 프런트엔드는 typescript이지만 동일한 임베딩 API에 액세스할 수 있음:
const myQuery = 'fuzzy'; // 이미지일 수도 있음
const myQueryVector = await getEmbeddingsForQuery(myQuery); // MM API 호출
const vectorQuery: VectorQuery = await khyati_collection.findNearest({
vectorField: 'imageEmbedding', // 인덱싱된 필드의 이름
queryVector: myQueryVector,
limit: 10, // 검색할 문서 수
distanceMeasure: 'DOT_PRODUCT' // 거리에 대한 세 가지 알고리즘 중 하나
});이렇게만 하면 됩니다! findNearest 메서드는 표준 Firestore 쿼리와 마찬가지로 모든 관련 메타데이터와 함께 쿼리 임베딩에 가장 가까운 문서를 반환합니다.
데모/search구현은 여기에서 확인할 수 있습니다. 저희가이 기술의 현재 본거지인 @google-cloud/firestoreNPM 라이브러리를 어떻게 사용하고 있는지에 주목해 주세요. 이 라이브러리는 일반적인firebaseNPM 패키지와 사용 방식이 다릅니다.
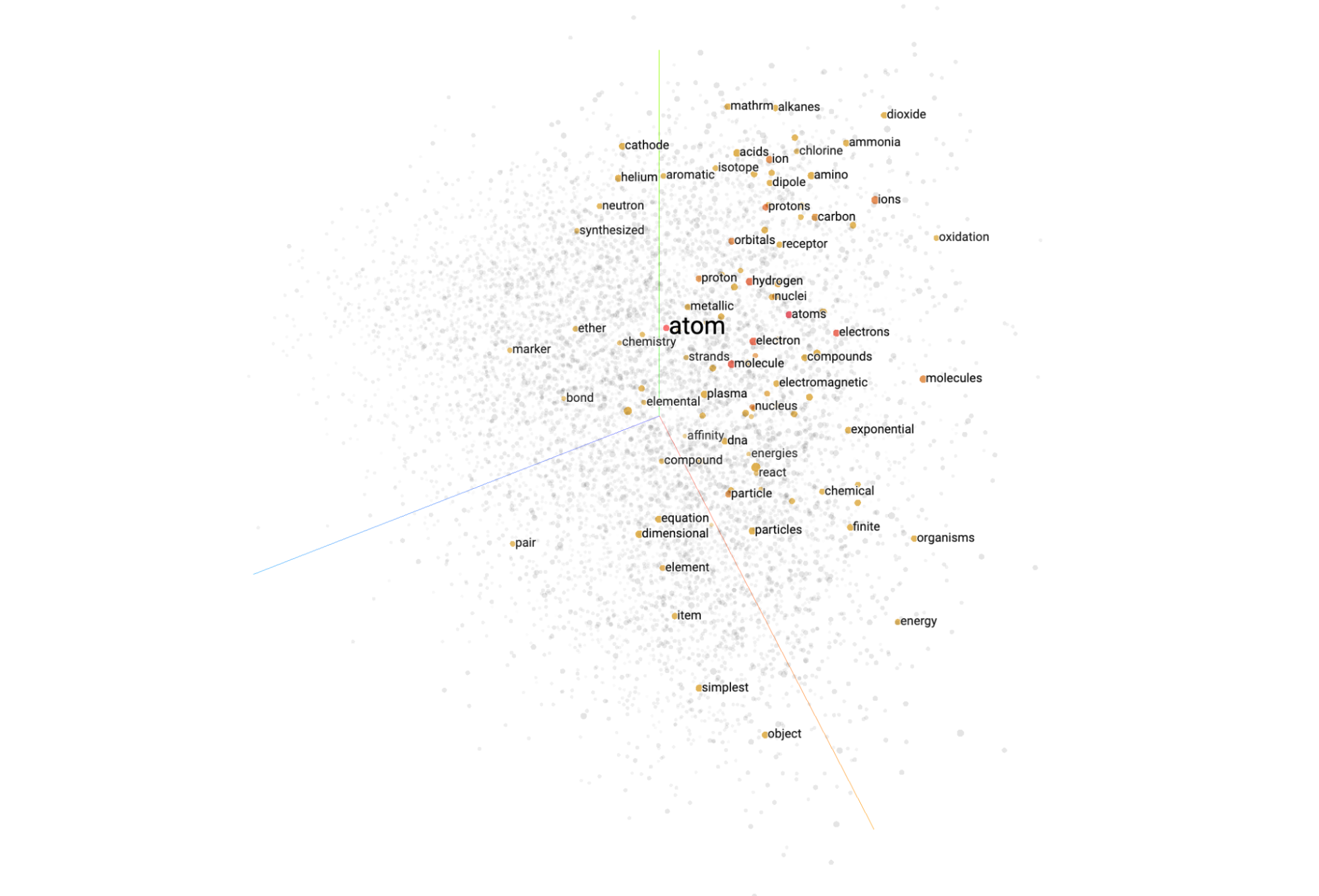
여기까지 잘 따라왔음에도 여전히 이런 임베딩 벡터가 어떤 것인지 확실히 감이 잡히지 않을 수도 있습니다. 이 프로젝트를 시작할 때 저희도 그랬거든요. 3차원 세계에 존재하는 우리 인간에게 1,408차원의 공간은 공상 과학 소설 같은 이야기니까요.
다행히도, Google PAIR 팀에서 구현한 UMAP이라는 멋진 도구를 비롯해 이러한 벡터의 차원을 줄일 수 있는 도구가 많이 있습니다. t-SNE와 마찬가지로, UMAP을 통해 멀티모달 임베딩 벡터를 가져와서 3차원으로 손쉽게 시각화할 수 있습니다. 날씨 이미지의 오픈 소스 데이터 세트와 플러그 앤 플레이가 되어야 하는 이 이미지들의 임베딩 등, GitHub에는 시각화를 처리하는 코드가 포함되어 있습니다.
저희는 Khyati의 데모를 구축하는 한편 Multimodal Embeddings API의 힘을 의도한 규모로 어떻게 발휘할지 그 방법도 모색했습니다. 결국, 유사한 기술이 Google의 핵심 검색 제품 대부분을 구동합니다. 그렇기에 Google이 임베딩 영역에서 탁월할 수 밖에 없습니다.
하지만 어떻게 대규모로 테스트할 수 있을까요? 알고 보니, Khyati가 그려온 수많은 일러스트레이션 작품처럼 우리 팀이 수없이 만들어온 슬라이드 덱도 탁월한 성능 시험장 역할을 했습니다. 지난 10년간 축적된 수천 개의 Google 프레젠테이션 말입니다. 팀에서 오랫동안 쌓아온 아이디어의 역사를 디지털 고고학적 방식으로 발굴한다고 생각하시면 됩니다.
떠오른 질문은 다음과 같습니다. "Multimodal Embeddings API가 이 방대한 자료실 안에 숨겨진 보물을 발굴할 수 있을까?," "Google의 팀장들이 '그 문제에 대해 스프린트 때 나왔던 그 아이디어 뭐였더라? 누가 포스트잇에 적어놨던 것 같은데...'와 같이 오랫동안 잊고 지냈던 정보를 결국 찾아낼 수 있을까?," "모두가 열광했던 그 놀라운 포스터를 우리 디자이너들이 쉽게 재발견할 수 있을까?" 미리 그 답을 알려드리자면, '할 수 있다!'입니다.
Drive 및 Slides API를 사용하여 수천 개의 프레젠테이션을 처리하고 각 슬라이드의 썸네일 이미지를 추출하느라 상당한 개발 시간이 소요되었습니다. 임베딩 프로세스 자체는 아티스트 데모와 거의 동일했으며 다음과 같이 요약할 수 있습니다.
for preso in all_decks:
for slide in preso.slides:
thumbnail = slides_api.getThumbnail(slide.id, preso.id)
slide_embedding = mm_embedding_model.get_embeddings(
image=thumbnail,
dimension=1408,
)
# 문서에 slide_embedding.image_embedding 저장이 프로세스를 통해 16,000개 이상의 프레젠테이션에서 775,000개 이상의 슬라이드를 위한 임베딩을 생성했습니다. 저희는 이 방대한 데이터 세트를 효율적으로 저장하고 검색하기 위해 이런 대규모 애플리케이션을 위해 특별히 설계된 Vertex AI의 벡터 검색을 사용했습니다.
Google 검색, YouTube, Play에 쓰이는 것과 동일한 기술을 기반으로 하는 Vertex AI의 벡터 검색은 수십억 개의 문서를 밀리초 단위의 시간 내에 검색할 수 있습니다. 벡터 검색은 아티스트 데모에서 사용한 Firestore 접근 방식과 유사한 원리로 작동하지만 훨씬 더 큰 규모와 성능을 제공합니다.
이 놀랍도록 강력한 기술을 활용하려면 검색하기 전에 몇 가지 추가 단계를 완료해야 합니다.
# 벡터 검색은 코드나 UI를 통해 생성된 Index에 의존하므로, 먼저 이전 단계의 임베딩이 Cloud 버킷에 저장되어 있는지 확인한 후 다음을 실행합니다.
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = 'my_index_name',
contents_delta_uri = BUCKET_URI,
dimensions = 1408, # Index 생성 시와 동일한 번호를 사용합니다.
approximate_neighbors_count = 10, #
)
# 이 Index를 생성하여 엔드포인트에 배포합니다.
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = "my_endpoint_name",
public_endpoint_enabled = True
)
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = "my_deployed_index_id"
)
# 온라인 상태로 전환되고 준비가 되면 앱에서 이전과 마찬가지로 쿼리를 실행할 수 있습니다!
response = my_index_endpoint.find_neighbors(
deployed_index_id = "my_deployed_index_id",
queries = [some_query_embedding],
num_neighbors = 10
)이 프로세스는 Khyati의 데모와 유사하지만 중요한 차이점이 있습니다. 바로 Google의 고효율 벡터 유사성 검색 알고리즘인 ScaNN의 힘을 활용하기 위해 전용 벡터 검색 인덱스를 만든다는 점입니다.
두 가지 옵션을 모두 살펴봤으므로 이제 차이점에 대해 알아보겠습니다.
각 벡터 검색 서비스와 관련된 알고리즘에는 두 가지 유형이 있음을 알아차리셨을 것입니다. 하나는 Firestore의 K-최근접 이웃(KNN)이고 다른 하나는 Vertex AI 구현의 확장 가능한 최근접 이웃(ScaNN)입니다. 저희는 일반적으로 팀의 일상 업무에서 엔터프라이즈급 솔루션을 사용하지 않으므로 두 가지 데모 모두 Firestore에서 시작했습니다.
그러나 Firestore의 KNN 검색은 무차별 대입 O(n) 알고리즘입니다. 즉, 인덱스에 추가하는 문서의 양에 따라 검색이 선형적으로 확장됩니다. 그래서 10,000개, 15,000개, 20,000개의 문서 임베딩 수를 돌파하자 처리 속도가 급격히 느려지기 시작했습니다.
하지만 Firestore의 표준 쿼리 조건자를 '사전 필터링' 단계에서 사용하면 이와 같은 속도 저하를 완화할 수 있습니다. 따라서 인덱스를 생성한 모든 임베딩을 검색하는 대신, where 쿼리를 수행하여 데이터 세트를 관련 문서로만 제한할 수 있습니다. 이를 위해서는 필터링에 사용할 필드에 다른 복합 인덱스가 필요합니다.
# 추가 인덱스 생성은 쉬운 일이지만 그래도 숙고해야 합니다.
gcloud alpha firestore indexes composite create
--collection-group=all_slides
--query-scope=COLLECTION
--field-config=order=ASCENDING,field-path="project" # 추가 필드
--field-config field-path=slide_embedding,vector-config='{"dimension":"1408", "flat": "{}"}'KNN과 유사하지만 '근사치의' 위치('확장 가능한 근사 최근접 이웃'에서처럼)에 기반한 지능형 인덱싱에 의존하는 ScaNN은 2020년에 공개 출시된 Google Research의 획기적인 혁신이었습니다.
수십억 개의 문서를 밀리초 단위로 쿼리할 수 있지만, 특히 Firestore 읽기/쓰기 작업과 비교하면 그러한 성능을 발휘하는 데는 비용이 듭니다. 또한 인덱스는 기본적으로 슬림하므로(간단한 키-값 쌍) 최근접 이웃이 반환되면 다른 컬렉션이나 테이블에 대한 2차 조회가 필요합니다. 그러나 775,000개 슬라이드의 경우, 조회에 최대 100ms, Firestore가 메타데이터 읽기에 최대 50ms의 시간이 걸려, 여전히 Cloud Firestore 벡터 검색이 기본적으로 제공할 수 있는 속도보다 훨씬 더 빨랐습니다.
하이브리드 검색이라는 접근 방식을 통해 벡터 검색을 기존 키워드 검색과 결합하는 방법에 대한 훌륭한 설명서도 몇 있습니다. 자세한 내용은 여기에서 확인하세요.
잠깐 짚어야 할 형식 지정 문제
Vertex AI용 인덱스를 생성하려면 별개의jsonl키-값 파일 형식도 필요했기에, 원래의 Firestore 구현에서 변환하는 데 약간의 작업이 필요했습니다. 어떤 포맷을 사용해야 할지 잘 모를 경우, 둘 중 어느 시스템에서나 쉽게 수집할 수 있는 애그노스틱 포맷으로 임베딩을 작성하는 것이 좋습니다. 이렇게 하면 LevelDB Firestore 내보내기가 주는 상대적인 두려움을 피할 수 있습니다.
완전한 Cloud 호스팅 솔루션이 적합하지 않은 경우에도 로컬 솔루션으로 Multimodal Embeddings API의 기능을 활용할 수 있습니다.
또한 sqlite-vec라는 새로운 라이브러리도 테스트했습니다. 이 라이브러리는 거의 모든 곳에서 실행 가능하고 Multimodal Embeddings API에서 반환하는 1,408차원 벡터를 쉽게 처리하는 sqlite의 매우 빠르고 종속성이 없는 구현입니다. 테스트를 위해 20,000여 개의 슬라이드를 포팅하면 200ms 범위에서 조회가 표시되었습니다. 여전히 온라인으로 문서 및 쿼리 임베딩을 생성하고 있지만, 이들이 생성되고 저장된 후 필요하다면 어디서나 검색을 처리할 수 있습니다.
word2vec의 기초부터 오늘날의 Multimodal Embeddings API까지, 정보 검색을 위한 자체 멀티모달 AI 시스템을 개발할 수 있는 새로운 가능성이 있습니다.
올바른 벡터 검색 솔루션 선택은 개발자의 필요에 따라 달라집니다. Firebase는 소규모 프로젝트에 사용하기 용이하고 비용 효율적인 옵션을 제공하는 반면, Vertex AI는 대규모 데이터 세트와 밀리초 수준의 검색 시간에 필요한 확장성과 성능을 제공합니다. 로컬 개발을 위해 sqlite-vec와 같은 도구를 사용하면 대부분 오프라인에서 임베딩의 힘을 활용할 수 있습니다.
멀티모달 검색의 미래를 탐험할 준비가 되셨나요? GitHub에서 오픈소스 멀티모달 임베딩 데모를 살펴보고, 코드를 실험해 보고, 직접 만든 창작물을 공유하세요. 여러분이 무엇을 개발하고 만들어낼지 정말 기대됩니다.