ベクトル エンベディングとは、テキスト、画像、音声といった現実のデータを、多次元マップの点として数学的に表すための方法です。そう聞くと無味乾燥なようですが、十分な数の次元があれば、コンピュータ(と、その延長として我々人間)がそのデータに含まれる関係を解明し、理解できるようになります。
たとえば、「word2vec」を覚えておられる方がいるかもしれません。これは、Google が 2013 年に開発した革命的な技術で、単語を数値ベクトルに変換し、機械によってセマンティックを理解できるようにするものです。この画期的な技術によって、機械翻訳から感情分析まで、自然言語処理における無数の進歩への道が開かれました。
我々はこの技術を基に、text-gecko という強力なテキスト エンベディング モデルをリリースしました。デベロッパーはこのモデルを利用し、テキスト内に含まれる豊富なセマンティクスの関係を解明できるようになりました。
Vertex の Multimodal Embeddings API は、これをさらに進化させ、テキスト、画像、動画を同じ共有ベクトル空間で表せるようにして、モダリティが異なっていても、コンテキスト上やセマンティック上の意味が保持されるようにしました。
この記事では、この技術の実際の応用例を 2 つ紹介します。過去 10 年間に我々のチームが作成したすべてのスライドと資料を検索する例と、アーティスト向けの直観的に利用できるビジュアル検索ツールの例です。コードを詳しく説明し、マルチモーダル エンベディングが持つ能力を存分に活用するための実用的なヒントをご紹介します。
我々のチームは、最近リリースされた Multimodal Embeddings API の活用方法を探っていました。企業の大規模なデータセットで活用できることはわかりましたが、もっと個人的で創造的な活用法がないか、必死に探していました。
チームのデザイナーであり、多数の作品を生み出すイラストレーターでもある Khyati は、この技術を利用して自分の作品をより適切に管理し、把握する方法はないかと、特に熱心に考えていました。
「多くのアーティストが、視覚的な類似性や概念的なキーワードに基づいて過去の作品を見つけるのに苦労しています。旧式のファイル整理法では役に立ちません。特に、一般的でない用語や抽象的な概念で検索する場合はお手上げです。」
我々のオープンソースの multimodal-embeddings デモは、このようにして生まれました。
Khyati のデータセットは、Multimodal Embeddings API のドキュメントで参照されている 100 万件のドキュメントの例に比べるとかなり小規模ですが、4 月の Google Cloud Next で発表された新しい Cloud Firestore のベクトル検索のテストケースとして最適です。
我々は Firebase プロジェクトをセットアップし、約 250 の Khyati のイラストを Multimodal Embeddings API に送信しました。このプロセスによって 1,408 次元の float 型配列エンベディング(最大のコンテキストを提供)が生成され、Firestore データベースに保存されました。
mm_embedding_model = MultiModalEmbeddingModel.from_pretrained("multimodalembedding")
# 各画像のエンベディングを作成します
embedding = mm_embedding_model.get_embeddings(
image=image,
dimension=1408,
)
# 保存する Firestore ドキュメントを作成し、コレクションに追加します
doc = {
"name": "Illustration 1",
"imageEmbedding": Vector(embedding.image_embedding),
... # その他のメタデータ
}
khyati_collection.add(doc)必ず、Firestore CLI を使用して imageEmbedding フィールドのインデックスを作成してください。
このコードブロックは簡潔にするために省略されています。完全なコードを見るには、 このノートブック をご確認ください。 vertexai.vision_models パッケージからエンベディング モデルを取得してください。 package
Firestore の K 最近傍(KNN)ベクトル検索を使用した検索は簡単です。(画像を埋め込むのと同様に)クエリを埋め込み、API に送信します。
// 我々のフロントエンドは Typescript ですが、同じ Embedding API にアクセスできます
const myQuery = 'fuzzy'; // image でもかまいません
const myQueryVector = await getEmbeddingsForQuery(myQuery); // MM API 呼び出し
const vectorQuery: VectorQuery = await khyati_collection.findNearest({
vectorField: 'imageEmbedding', // インデックスを作成したフィールドの名前
queryVector: myQueryVector,
limit: 10, // 取得するドキュメントの数
distanceMeasure: 'DOT_PRODUCT' // 距離の 3 つのアルゴリズムのいずれか
});これだけです。findNearest メソッドによって、標準の Firestore クエリと同様に、クエリのエンベディングに最も近いドキュメントとそのすべての関連メタデータが返されます。
デモの/searchの実装は こちらをご覧ください。通常の firebase NPM パッケージではなく、@google-cloud/firestoreNPM ライブラリ(この技術の現在のホーム)を使用していることに注目してください。
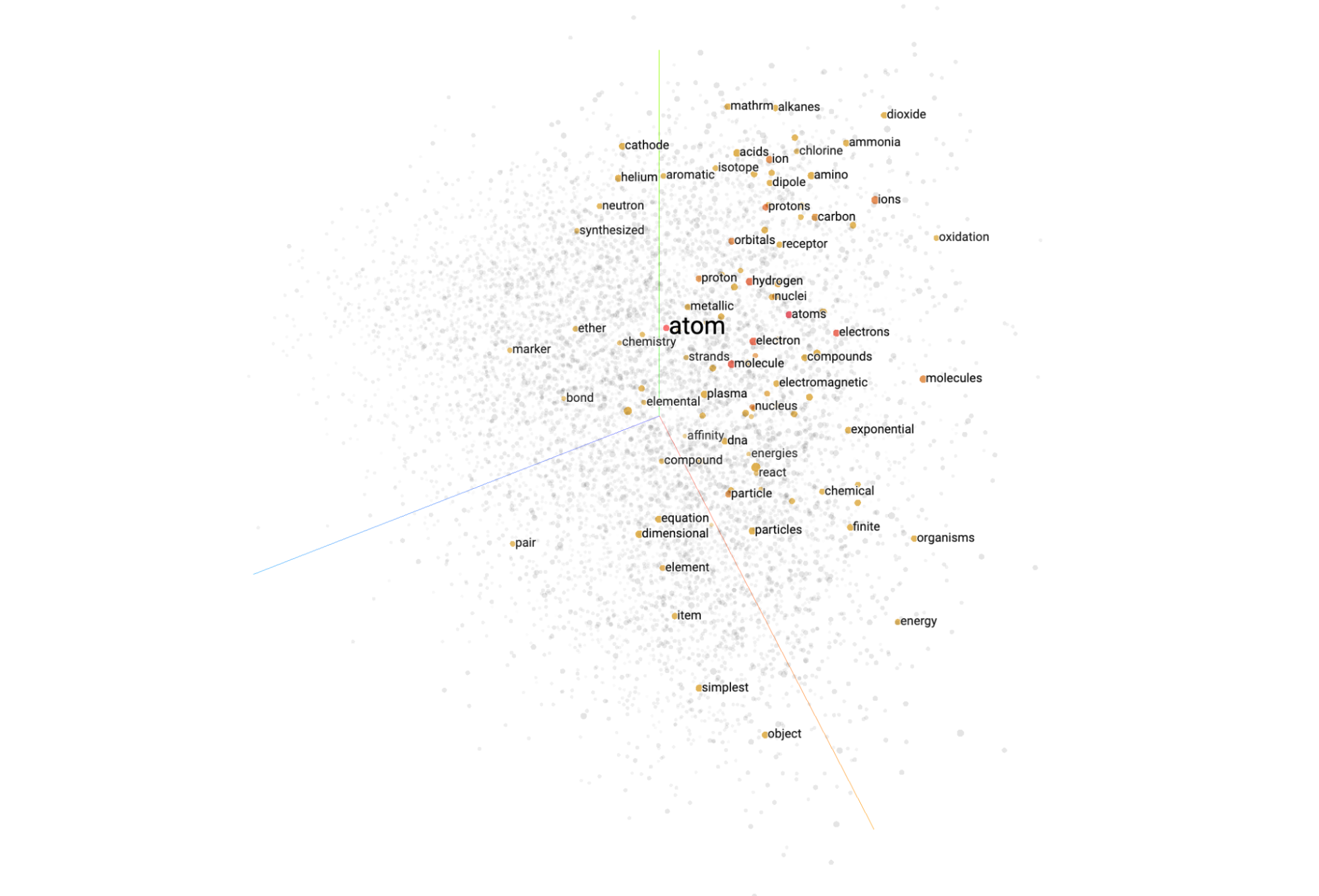
ここまで読んで、まだエンベディング ベクトルとはどういうものかを理解できていなくても、心配はいりません。我々もこのプロジェクトの開始時にはそうでした。私たちは 3 次元の世界に生きており、1,408 次元の空間はちょっとした SF の世界です。
幸いにも、このようなベクトルの次元を削減するためのツールが多数提供されています。その一つに、UMAP という Google PAIR の人々によって実装された優れたツールがあります。t-SNE と同様に、UMAP を使用すれば、マルチモーダル エンベディング ベクトルを簡単に 3 次元で可視化できます。この処理を行うためのコードを GitHub にご用意しています。これには、気象画像のオープンソース データセットと、すぐに利用できるそのエンベディングが含まれます。
我々は Khyati のデモを作成しながら、Multimodal Embeddings API の持つ能力を最大限に活用する方法も探っていました。Google がエンベディング分野で他社より秀でている理由に納得がいきました。類似の技術を、我々の中心的な検索サービスの多くで活用できるのです。
では、この技術を大規模にテストするにはどうすればよいでしょうか。我々のチームは資料作成に関しても同様に多作で、これが結果として、優れたテスト環境となりました。どのくらい多作かというと、この 10 年で数千もの Google スライドのプレゼンテーションが積みあがったほどです。これは、チームのアイデアの歴史を掘り返す、デジタル考古学のようなものと考えてみてください。
ここでの質問は、Multimodal Embeddings API は、この膨大なアーカイブの中に埋もれた宝を掘り起こせるのか?我々のチームリーダーは、忘却の彼方に沈んだ「誰かが付箋に書いた、何かに関するスプリントで出たあのアイデア」をついに見つけることができるのか?デザイナーは、全員が熱狂した「あの素晴らしいポスター」を簡単に掘り起こせるのか?ということです。ネタばらししてしまうと、答えは「できる」です。
我々の開発時間の多くは、何千ものプレゼンテーションについて議論を戦わせ、Drive API や Slides API を使用して各スライドのサムネイルを抽出することに費やされてきました。エンベディング プロセス自体はアーティストのデモとほぼ同じです。概要を以下に示します。
for preso in all_decks:
for slide in preso.slides:
thumbnail = slides_api.getThumbnail(slide.id, preso.id)
slide_embedding = mm_embedding_model.get_embeddings(
image=thumbnail,
dimension=1408,
)
# ドキュメントに slide_embedding.image_embedding を保存しますこのプロセスによって、16,000 超のプレゼンテーションから 775,000 を超えるスライドのエンベディングが生成されました。この膨大なデータセットを効率的に保存して検索するために、このような大規模な事例専用に作成された、Vertex AI のベクトル検索を利用しました。
Vertex AI のベクトル検索では、Google 検索、YouTube、Google Play を支えているのと同じ技術が利用されており、何十億ものドキュメントをミリ秒単位で検索できます。アーティストのデモで使用した Firestore アプローチと同様の原則で動作しますが、規模とパフォーマンスはそれよりはるかに大きくなります。
この極めて強力な技術を活用するためには、検索の前に、いくつかの追加手順を実行しておく必要があります。
# ベクトル検索は、コードまたは UI を使用して作成されるインデックスを利用するため、最初に前のステップで生成されたエンベディングがクラウド バケットに保存されていることを確認してから、以下を実行します。
my_index = aiplatform.MatchingEngineIndex.create_tree_ah_index(
display_name = 'my_index_name',
contents_delta_uri = BUCKET_URI,
dimensions = 1408, # エンベディングの作成時と同じ数値を使用します
approximate_neighbors_count = 10, #
)
# このインデックスを作成し、エンドポイントにデプロイします
my_index_endpoint = aiplatform.MatchingEngineIndexEndpoint.create(
display_name = "my_endpoint_name",
public_endpoint_enabled = True
)
my_index_endpoint.deploy_index(
index = my_index, deployed_index_id = "my_deployed_index_id"
)
# インデックスがオンラインで利用可能になったら、アプリから以前と同様にクエリを実行できます
response = my_index_endpoint.find_neighbors(
deployed_index_id = "my_deployed_index_id",
queries = [some_query_embedding],
num_neighbors = 10
)このプロセスは Khyati のデモと似ていますが、大きな違いが一つあります。今回は、Google の非常に効率的なベクトル類似性検索アルゴリズムである、スケーラブルな最近傍探索(ScaNN)の力を活用するために、専用のベクトル検索インデックスを作成したことです。
2 つの選択肢を確認したところで、両者の違いを詳しく見ていきましょう。
各ベクトル検索サービスに関連するアルゴリズムには 2 種類あることにお気付きの方もいるかもしれません。Firestore では K 近傍法(KNN)、Vertex AI の実装では ScaNN です。我々のチームの日常業務では企業規模のソリューションを扱うことがないことから、いずれのデモでも Firestore から始めました。
ただし、Firestore の KNN 検索は総あたりの O(n)アルゴリズムです。つまり、インデックスに追加するドキュメントの数に直線的に比例して拡張するということです。したがって、1 万個、1 万 5,000 個、2 万個のドキュメントのエンベディングを解明しようとすると、検索速度は瞬く間に低下します。
ただし、この速度低下は、「事前フィルタ」ステップで使用される Firestore の標準のクエリ述語によって緩和することができます。インデックスを作成したエンベディングすべてを検索するのではなく、where クエリを実行して、関連ドキュメントのみを検索するように制限します。この場合、フィルタに使用するフィールドの別の複合インデックスが必要になります。
# 追加のインデックスの作成は簡単ですが、注意は必要です
gcloud alpha firestore indexes composite create
--collection-group=all_slides
--query-scope=COLLECTION
--field-config=order=ASCENDING,field-path="project" # 追加フィールド
--field-config field-path=slide_embedding,vector-config='{"dimension":"1408", "flat": "{}"}'ScaNN は KNN と似ていますが、「近似」の場所(「スケーラブルな近似最近傍」の「近似」)に基づくインテリジェントなインデックス作成を利用します。これは、2020 年に一般公開された Google Research による画期的技術です。
何十億ものドキュメントをミリ秒単位でクエリすることができますが、その分コストがかかります。特に Firestore の読み取り / 書き込みと比較した場合に顕著です。さらに、インデックスはデフォルトで情報量が少ない(単純な Key-Value ペア)ので、最近傍が返された後で、他のコレクションやテーブルの 2 次検索を行う必要があります。ただし、我々の 775,000 枚のスライドであれば、検索時間が約 100 ms、Firestore によるメタデータの読み取り時間が約 50 ms なので、それでもなお Cloud Firestore のベクトル検索でネイティブに提供される検索よりも桁違いに速くなります。
ベクトル検索と従来のキーワード検索を組み合わせた、ハイブリッド検索という方法に関する優れたドキュメントもあります。詳細は、こちらをご覧ください。
形式に関する余談
Vertex AI のインデックス作成では、さらにjsonlKey-Value ファイル形式が必要なので、元の Firestore 実装からの変換にある程度の手間がかかりました。どちらの形式を使用すべきか不明な場合は、煩雑な LevelDB 形式の Firestore エクスポートを行わなくて済むように、いずれのシステムでも簡単に取り込める、システム非依存の形式でエンベディングを作成するのが賢明です。
完全にクラウドでホストされているソリューションが適切でない場合は、ローカル ソリューションで Multimodal Embeddings API の力を活用することもできます。
我々は、sqlite-vec という新しいライブラリもテストしました。これは、極めて高速で、ほぼあらゆる場所で実行できる sqlite の依存関係ゼロの実装で、Multimodal Embeddings API によって返される 1,408 次元のベクトルを容易に処理できます。20,000 を超えるスライドを移植して行ったテストでの検索速度は、約 200 ms 台でした。ドキュメントとクエリのエンベディングの作成はオンラインで行いますが、作成して保存した後は、必要に応じてどこででも検索を行えます。
word2vec の誕生から現在の Multimodal Embeddings API まで、情報検索用の独自のマルチモーダル AI システムの開発には、わくわくするような、新しい可能性があります。
ニーズに応じて適切なベクトル検索ソリューションを選択します。Firebase は、小規模なプロジェクトにとって、使いやすく、費用対効果の高い選択肢となります。一方 Vertex AI は、大規模なデータセットで必要な拡張性とパフォーマンス、またミリ秒単位の検索時間を実現します。ローカル開発では、sqlite-vec のようなツールを使用することで、ほぼオフラインにあるエンベディングの力を活用できます。
マルチモーダル検索の未来をさらに体験したい方は、GitHub にあるオープンソースの multimodal-embeddings デモをご利用ください。実際にコードを試し、ご自分の作品を共有してください。皆様のビルドを拝見できるのを楽しみにしています。