

Na esteira do Gemma 1.1 (Kaggle, Hugging Face), do CodeGemma (Kaggle, Hugging Face) e do modelo multimodal PaliGemma (Kaggle, Hugging Face), temos o prazer de anunciar o lançamento do modelo Gemma 2 no Keras.
O Gemma 2 está disponível em dois tamanhos, parâmetros de 9B e de 27B, com variantes padrão e ajustadas por instruções. Você pode encontrá-los aqui:
Os resultados de alto nível da Gemma 2 em comparativos de mercado de LLM são abordados em outros locais (consulte goo.gle/gemma2report). Nesta postagem, demonstraremos como a combinação do Keras e do JAX pode ajudar você a trabalhar com esses modelos grandes.
O JAX é um framework numérico criado para ser escalonado. Ele usa o compilador de aprendizado de máquina XLA e treina os maiores modelos no Google.
O Keras é o framework de modelagem para engenheiros de ML que agora pode ser executado no JAX, no TensorFlow ou no PyTorch. O Keras agora traz a potência do escalonamento paralelo de modelos por meio da ótima API Keras. Você pode experimentar os novos modelos Gemma 2 no Keras aqui:
Devido ao tamanho, esses modelos só podem ser carregados e ajustados com total precisão pela divisão de seus pesos em vários aceleradores. O JAX e o XLA têm amplo suporte ao particionamento de pesos (paralelismo de modelos SPMD). O Keras adiciona a API keras.distribution.ModelParallel para ajudar a especificar fragmentações camada por camada de maneira simples:
# List accelerators
devices = keras.distribution.list_devices()
# Arrange accelerators in a logical grid with named axes
device_mesh = keras.distribution.DeviceMesh((2, 8), ["batch", "model"], devices)
# Tell XLA how to partition weights (defaults for Gemma)
layout_map = gemma2_lm.backbone.get_layout_map()
# Define a ModelParallel distribution
model_parallel = keras.distribution.ModelParallel(device_mesh, layout_map, batch_dim_name="batch")
# Set is as the default and load the model
keras.distribution.set_distribution(model_parallel)
gemma2_lm = keras_nlp.models.GemmaCausalLM.from_preset(...)A função gemma2_lm.backbone.get_layout_map() é um auxiliar que retorna uma configuração de fragmentação camada por camada para todos os pesos do modelo. Ela segue as recomendações contidas neste relatório do Gemma (goo.gle/gemma2report). Aqui está um trecho:
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", "data")
layout_map["decoder_block.*attention.*(query|key|value).kernel"] =
("model", "data", None)
layout_map["decoder_block.*attention_output.kernel"] = ("model", None, "data")
...Em resumo, para cada camada, essa configuração especifica ao longo de qual eixo, ou quais eixos, é necessário dividir cada bloco de pesos e em quais aceleradores essas partes serão posicionadas. Isso é mais fácil entender com uma imagem. Vamos usar como exemplo os pesos de "consulta" na arquitetura de atenção do Transformer, que têm a forma (nb heads, embed size, head dim):
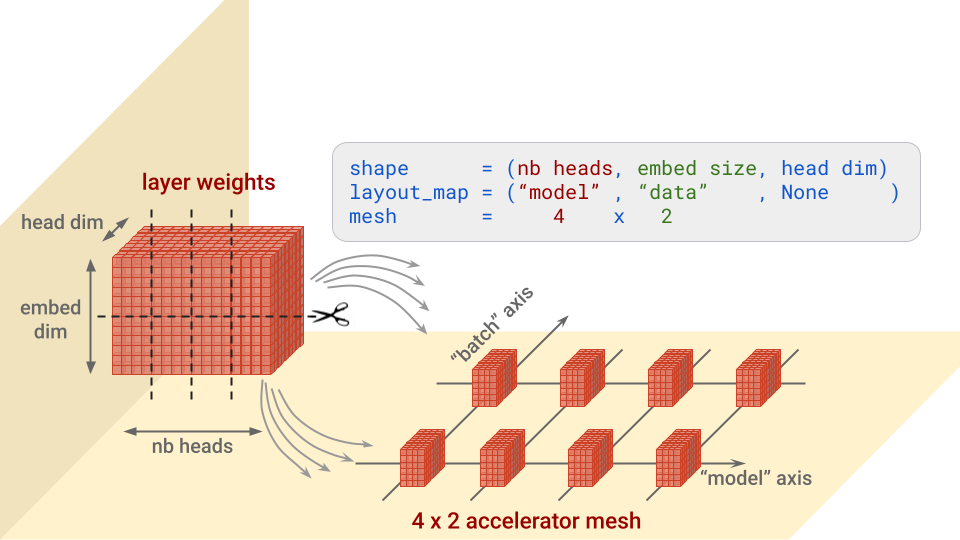
Observação: as dimensões da malha para as quais não houver divisões receberão cópias. Esse seria o caso, por exemplo, se o mapa de layout acima fosse ("model", None, None).
Observe também o parâmetro batch_dim_name="batch" em ModelParallel. Se o eixo "batch" tiver várias linhas de aceleradores, que é o caso aqui, o paralelismo de dados também será usado. Cada linha de aceleradores carregará e treinará apenas uma parte de cada lote de dados e, em seguida, as linhas combinarão seus gradientes.
Depois de carregar o modelo, há dois snippets de código úteis para exibir as fragmentações de peso que foram realmente aplicadas:
for variable in gemma2_lm.backbone.get_layer('decoder_block_1').weights:
print(f'{variable.path:<58} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')
#... set an optimizer through gemma2_lm.compile() and then:
gemma2_lm.optimizer.build(gemma2_lm.trainable_variables)
for variable in gemma2_lm.optimizer.variables:
print(f'{variable.path:<73} {str(variable.shape):<16} \
{str(variable.value.sharding.spec)}')Ao observar a saída (abaixo), podemos notar algo importante: os regex na especificação do layout fizeram a correspondência com os pesos da camada e também com as variáveis momentum e velocity correspondentes no otimizador e realizaram a fragmentação adequadamente. Esse é um ponto importante a ser verificado ao particionar um modelo.
# for layers:
# weight name . . . . . . . . . . shape . . . . . . layout spec
decoder_block_1/attention/query/kernel (16, 3072, 256)
PartitionSpec('model', None, None)
decoder_block_1/ffw_gating/kernel (3072, 24576)
PartitionSpec(None, 'model')
...
# for optimizer vars:
# var name . . . . . . . . . . . .shape . . . . . . layout spec
adamw/decoder_block_1_attention_query_kernel_momentum
(16, 3072, 256) PartitionSpec('model', None, None)
adamw/decoder_block_1_attention_query_kernel_velocity
(16, 3072, 256) PartitionSpec('model', None, None)
...O LoRA é uma técnica que congela os pesos do modelo, substituindo-os por adaptadores de baixa classificação, ou seja, adaptadores pequenos.
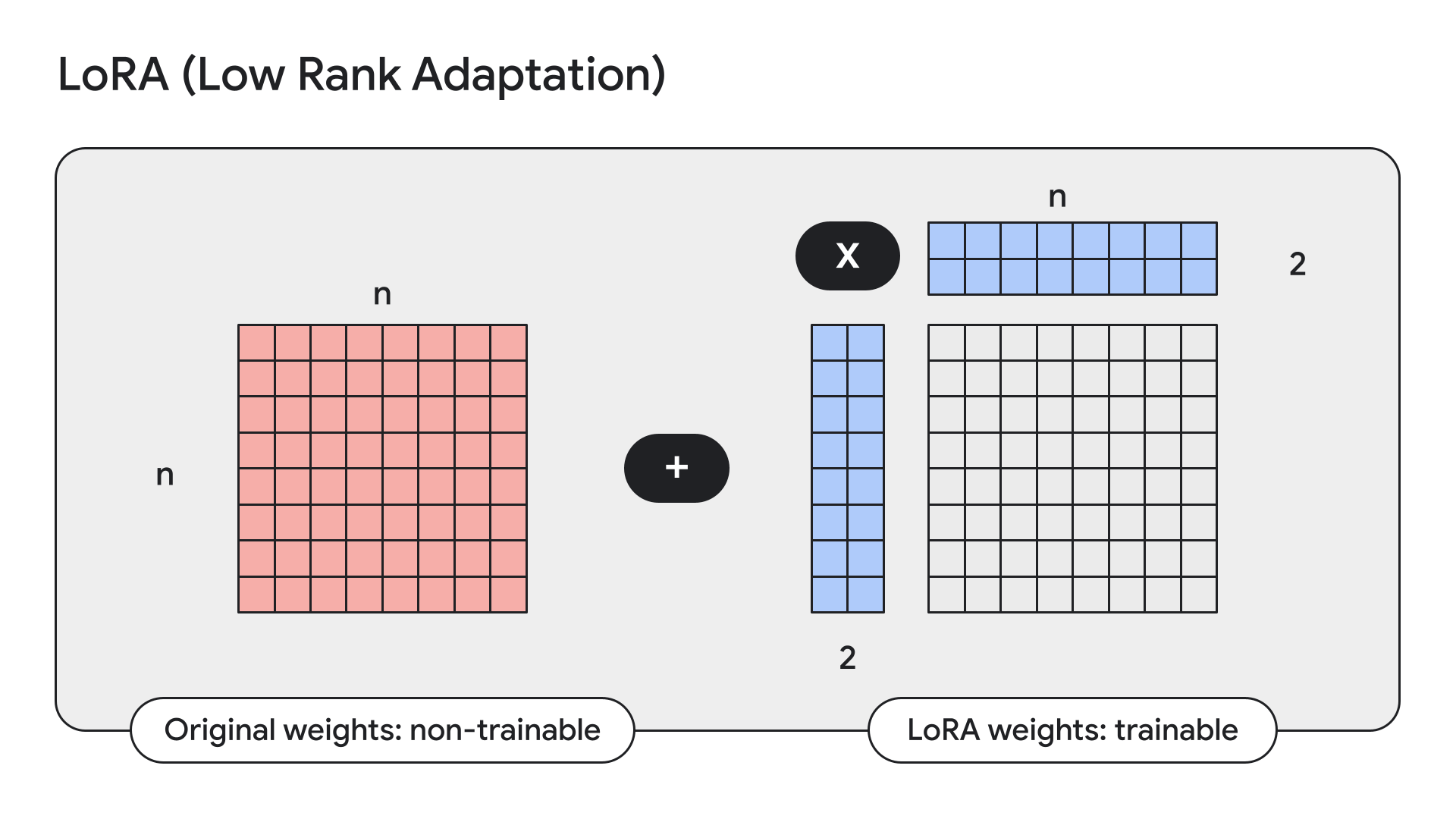
O Keras também tem APIs diretas para isso:
gemma2_lm.backbone.enable_lora(rank=4) # Rank picked from empirical testingAo exibir detalhes do modelo com model.summary() após a ativação do LoRA, podemos ver que o LoRA reduz o número de parâmetros treináveis de 9 bilhões para 14,5 milhões no Gemma de 9B.
No mês passado, anunciamos que os modelos Keras estariam disponíveis no Kaggle e no Hugging Face para que os usuários fizessem download e upload. Hoje, melhoramos ainda mais a integração do Hugging Face: agora, você pode carregar quaisquer pesos ajustados para os modelos com suporte, independentemente de terem sido treinados usando ou não uma versão Keras do modelo. Os pesos serão convertidos automaticamente para que isso funcione. Isso significa que, agora, você tem acesso às dezenas de ajustes do Gemma carregados pelos usuários do Hugging Face, diretamente do KerasNLP. E não apenas do Gemma. Isso acabará funcionando para qualquer modelo Hugging Face Transformers que tenha uma implementação do KerasNLP correspondente. Por enquanto, o Gemma e o Llama3 funcionam. Por exemplo, você pode experimentar isso no ajuste do Hermes-2-Pro-Llama-3-8B usando este Colab:
causal_lm = keras_nlp.models.Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)O PaliGemma é um VLM aberto avançado, inspirado no PaLI-3. Criado com base em componentes abertos, incluindo o modelo de visão SigLIP e o modelo de linguagem Gemma, o PaliGemma foi desenvolvido para ter o melhor desempenho de ajuste da categoria em uma ampla variedade de tarefas de visão-linguagem. Isso inclui legendas de imagens, resposta visual a perguntas, compreensão de textos em imagens e detecção e segmentação de objetos.
Você pode encontrar a implementação do Keras do PaliGemma no GitHub, nos modelos Hugging Face e no Kaggle.
Esperamos que você goste de experimentar ou de criar com os novos modelos Gemma 2 no Keras!

Advancing agentic AI development with Firebase Studio

Apresentamos o Gemma 3n: o guia para desenvolvedores

T5Gemma: A new collection of encoder-decoder Gemma models

Announcing GenAI Processors: Build powerful and flexible Gemini applications