
JAX로 처음부터 언어 모델을 개발하는 데 필요한 사항이 궁금하셨다면 이 글이 도움이 될 것입니다. 필자는 최근 Cloud Next 2025에서 이 주제에 대한 워크숍을 진행하고 훌륭한 피드백을 받았습니다. 이에 워크숍에 참석하지 못했던 모든 분을 위한 가이드를 작성해야겠다는 생각이 들었습니다.
JAX를 사용해 Google TPU의 성능을 쉽게 활용하는 방법을 알려주는 이 글과 코드 예시를 통해 GPT-2 모델을 개발하고 사전 학습을 수행하실 수 있을 것입니다. Colab 또는 Kaggle의 TPU를 사용하여 전체 프로젝트를 무료로 실행할 수 있으며 여기에서 전체 노트북을 찾을 수 있습니다.
이것은 실습 튜토리얼이므로 일반적인 머신러닝 개념에 익숙하신 것으로 가정하고 설명하겠습니다. JAX가 처음인 분이라면 PyTorch 개발자의 JAX 기초 가이드부터 시작하는 것이 좋습니다.
먼저, 여기서 사용할 도구에 대해 간단히 살펴보겠습니다.
모델 개발을 시작하기 전에 JAX 생태계에 대해 짧게 말씀드리겠습니다. JAX 생태계는 모듈식 접근 방식을 취합니다. 핵심 수치 처리 기능을 제공하는 JAX 코어와 이를 기반으로 다양한 애플리케이션별 요구를 충족하기 위한 풍부한 라이브러리가 구축되어 있습니다. 예를 들어, 신경망 구축을 위한 Flax, 체크포인트 및 모델 지속성을 위한 Orbax, 최적화를 위한 Optax가 있습니다. (이 글에서는 이 3가지를 모두 사용할 예정입니다). autograd, 벡터화, JIT 컴파일 등의 기본 제공 함수 변환과 더불어 강력한 성능과 사용하기 쉬운 API 덕분에 JAX는 LLM 학습에 완벽한 도구입니다.
OpenAI는 GPT2 모델 코드와 가중치를 이전에 공개한 바 있는데, 이는 좋은 참고 자료가 되었습니다. 또한 nanoGPT 같이 모델을 복제하기 위한 커뮤니티의 다양한 시도가 있습니다. 다음은 GPT2에 대한 상위 수준 모델 아키텍처 다이어그램입니다.
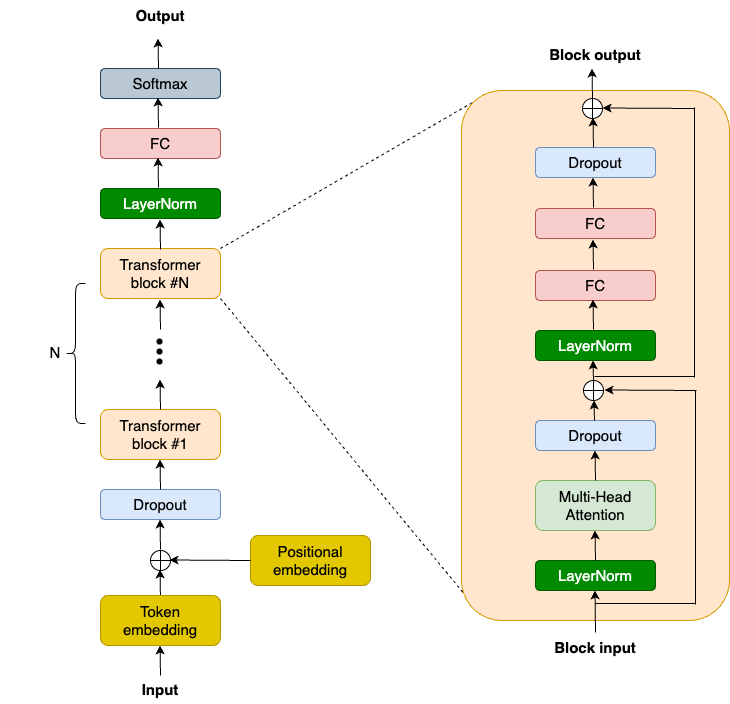
NNX(새로운 Flax 인터페이스)를 사용하여 GPT2 모델을 개발해 보겠습니다. 간결성을 위해 최신 대형 언어 모델의 핵심인 트랜스포머 블록에 초점을 맞추겠습니다. 트랜스포머 블록은 어떤 시퀀스에서도 장거리 종속성을 캡처하고 그에 대한 풍부한 컨텍스트 이해를 구축합니다. GPT2 트랜스포머 블록은 LayerNorm 레이어 2개, MHA(Multi-Head Attention) 레이어 1개, 드롭아웃 레이어 2개, 선형 투영 레이어 2개, 잔차 연결 2개로 구성됩니다. 따라서 먼저 TransformerBlock 클래스의 __init__ 함수에 이러한 레이어를 정의합니다.
class TransformerBlock(nnx.Module):
def __init__(
self,
embed_dim: int,
num_heads: int,
ff_dim: int,
dropout_rate: float,
rngs: nnx.Rngs,
):
self.layer_norm1 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim, rngs=rngs
)
self.mha = nnx.MultiHeadAttention(
num_heads=num_heads, in_features=embed_dim, rngs=rngs
)
self.dropout1 = nnx.Dropout(rate=dropout_rate)
self.layer_norm2 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim, rngs=rngs
)
self.linear1 = nnx.Linear(
in_features=embed_dim, out_features=ff_dim, rngs=rngs
)
self.linear2 = nnx.Linear(
in_features=ff_dim, out_features=embed_dim, rngs=rngs
)
self.dropout2 = nnx.Dropout(rate=dropout_rate)다음으로 __call__ 함수에서 이러한 레이어를 조합합니다.
class TransformerBlock(nnx.Module):
def __call__(self, inputs, training: bool = False):
input_shape = inputs.shape
bs, seq_len, emb_sz = input_shape
attention_output = self.mha(
inputs_q=self.layer_norm1(inputs),
mask=causal_attention_mask(seq_len),
decode=False,
)
x = inputs + self.dropout1(
attention_output, deterministic=not training
)
# MLP
mlp_output = self.linear1(self.layer_norm2(x))
mlp_output = nnx.gelu(mlp_output)
mlp_output = self.linear2(mlp_output)
mlp_output = self.dropout2(
mlp_output, deterministic=not training
)
return x + mlp_outputPyTorch 또는 TensorFlow 같은 다른 ML 프레임워크를 사용하여 언어 모델을 학습시켜 본 적이 있다면 이 코드가 무척 익숙해 보일 것입니다. 그러나 JAX의 가장 큰 매력 중 하나는 SPMD(Single Program Multiple Data)를 통해 자동으로 코드를 병렬로 실행할 수 있는 놀라운 기능을 갖췄다는 점입니다. 코드를 여러 가속기(여러 TPU 코어)에서 실행할 것이므로 SPMD는 꼭 필요한 기능입니다. 그 작동 방식을 살펴보겠습니다.
SPMD를 수행하려면 먼저 TPU를 사용 중인지 확인해야 합니다. Colab 또는 Kaggle을 사용하는 경우에는 TPU 런타임을 선택하세요(Cloud TPU VM을 사용할 수도 있음).
import jax
jax.devices()
# Free-tier Colab offers TPU v2:
# [TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),
# TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),
# TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),
# TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),
# TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),
# TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),
# TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),
# TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]Colab과 Kaggle은 8개의 개별 TPU 코어를 가진 TPU v2 또는 v3을 제공합니다. TPU v3 트레이는 다음과 같은 형태입니다.

GPT2 모델을 효율적으로 학습시키기 위해 SPMD를 통해 모든 TPU 코어를 함께 실행하고 JAX에서 데이터 병렬 처리를 활용할 것입니다. 이를 위해 하드웨어 메시를 정의합니다.
mesh = jax.make_mesh((8, 1), ('batch', 'model'))메시를 가속기로 구성된 2D 행렬이라고 생각하시면 됩니다. 오늘은 메시에 대해 batch 축과 model 축이라는 두 축을 정의합니다. 그래서 총 8x1, 즉 8개의 코어가 있습니다. 이 축이 데이터와 모델 매개변수를 분할하는 방법을 결정합니다. 다른 병렬 처리 체계를 실험하려면 나중에 축을 변경할 수 있습니다.
이제 ‘model‘ 축을 사용하여 모델 매개변수를 어떻게 분할할지 JAX에 알려 __init__ 함수를 변경합니다. 가중치 텐서를 초기화할 때 nnx.with_partitioning을 추가하여 이 작업을 수행합니다. LayerNorm 스케일/바이어스 텐서와 같은 1차원 가중치 텐서의 경우 ‘model‘ 축을 따라 직접 분할하고, MHA 및 Linear 커널 텐서와 같은 2차원 가중치 텐서의 경우 model 축을 따라 2번째 차원을 분할합니다.
class TransformerBlock(nnx.Module):
def __init__(
self,
embed_dim: int,
num_heads: int,
ff_dim: int,
dropout_rate: float,
rngs: nnx.Rngs,
):
self.layer_norm1 = nnx.LayerNorm(
epsilon=1e-6, num_features=embed_dim,rngs=rngs, rngs=rngs,
scale_init=nnx.with_partitioning(
nnx.initializers.ones_init(),
("model"),
),
bias_init=nnx.with_partitioning(
nnx.initializers.zeros_init(),
("model"),
),
)
self.mha = nnx.MultiHeadAttention(
num_heads=num_heads, in_features=embed_dim,
kernel_init=nnx.with_partitioning(
nnx.initializers.xavier_uniform(),
(None, "model"),
),
bias_init=nnx.with_partitioning(
nnx.initializers.zeros_init(),
("model"),
),
)
# 간결성을 위해 블록의 다른 레이어 생략전체 GPT2 모델에 대해 모델 텐서 병렬 처리를 활성화할 수 있도록 이처럼 다른 레이어를 분할해야 합니다. 이 튜토리얼에서는 모델 텐서 병렬 처리를 사용하지 않지만, 그래도 이를 구현하는 것이 좋습니다. 나중에 모델 크기가 커질 수도 있고 모델 매개변수를 분할해야 할 수도 있기 때문입니다. 이러한 구현을 통해 한 줄의 코드만 변경해서 더 큰 모델을 즉시 실행할 수 있습니다. 예를 들면 다음과 같습니다.
mesh = jax.make_mesh((4, 2), ('batch', 'model'))다음으로, 이전 블로그와 유사한 loss_fn 및 train_step 함수를 정의합니다. train_step() 함수는 교차 엔트로피 손실 함수의 기울기를 계산하고 옵티마이저를 통해 가중치를 업데이트하며 모델을 학습시키기 위해 루프에서 호출됩니다. 컴퓨팅 리소스를 많이 사용하므로 최고의 성능을 달성하기 위해서 @nnx.jit 데코레이터를 사용해 두 함수를 모두 JIT로 컴파일하겠습니다.
@nnx.jit
def loss_fn(model, batch):
logits = model(batch[0])
loss = optax.softmax_cross_entropy_with_integer_labels(
logits=logits, labels=batch[1]
).mean()
return loss, logits
@nnx.jit
def train_step(
model: nnx.Module,
optimizer: nnx.Optimizer,
metrics: nnx.MultiMetric,
batch,
):
grad_fn = nnx.value_and_grad(loss_fn, has_aux=True)
(loss, logits), grads = grad_fn(model, batch)
metrics.update(loss=loss, logits=logits, lables=batch[1])
optimizer.update(grads)schedule = optax.cosine_decay_schedule(
init_value=init_learning_rate, decay_steps=max_steps
)
optax_chain = optax.chain(
optax.adamw(learning_rate=schedule, weight_decay=weight_decay)
)
optimizer = nnx.Optimizer(model, optax_chain)마지막으로, 간단한 학습 루프를 만듭니다.
while True:
input_batch, target_batch = get_batch("train")
train_step(
model,
optimizer,
train_metrics,
jax.device_put(
(input_batch, target_batch),
NamedSharding(mesh, P("batch", None)),
),
)
step += 1
if step > max_steps:
breakjax.device_put 함수를 사용하여 batch 축을 따라 입력 데이터를 어떻게 분할하는지 주목하세요. 이 경우 JAX는 데이터 병렬 처리를 활성화하고, 통신 집합 연산(AllReduce)을 자동으로 삽입해 모든 것을 결합하며, 가능한 한 계산과 통신을 중첩합니다. 병렬 계산에 대한 자세한 내용은 JAX의 병렬 프로그래밍 소개 설명서를 참조하세요.
이 시점에서 모델은 학습 중이어야 합니다. 그리고 실행 추적에 가중치와 바이어스를 사용하는 경우 학습 손실을 관찰할 수 있습니다. 다음은 GPT2 124M 모델 학습을 위한 테스트 실행입니다.
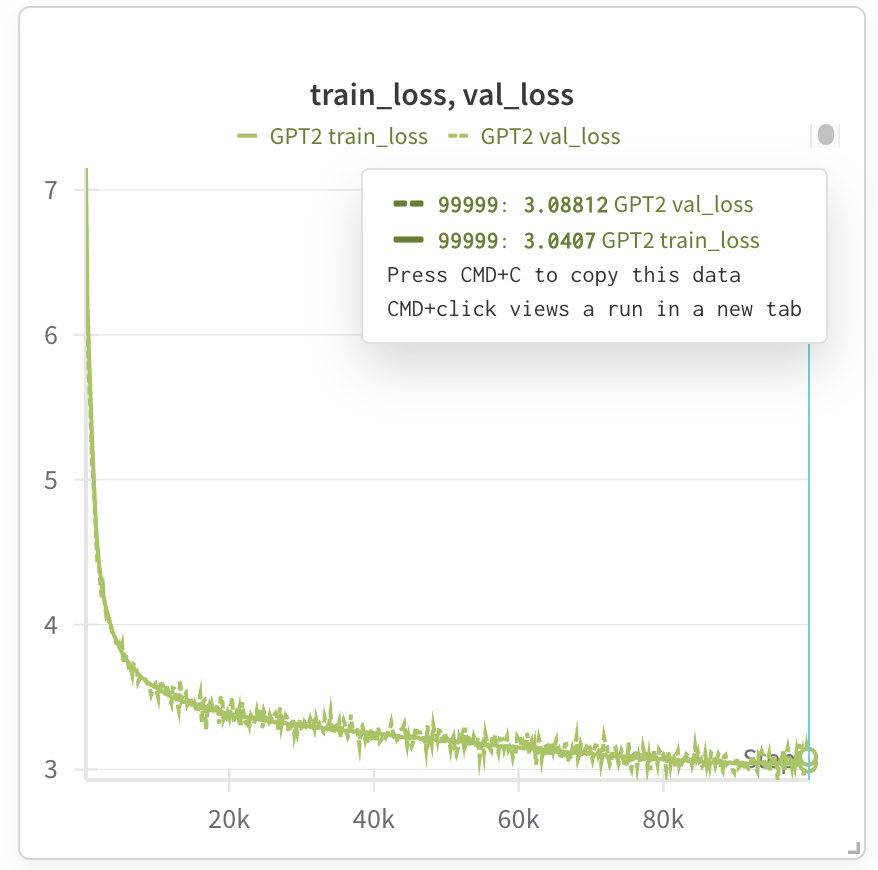
Kaggle TPU v3에서는 최대 7시간이 소요되지만(9시간 동안 중단 없이 사용 가능), Trillium을 사용하는 경우 학습 시간이 1.5시간으로 단축됩니다(Trillium에는 칩당 32G HBM(고대역폭 메모리)이 있으므로, 배치 크기를 두 배로 늘리고 학습 단계를 절반으로 줄일 수 있음).
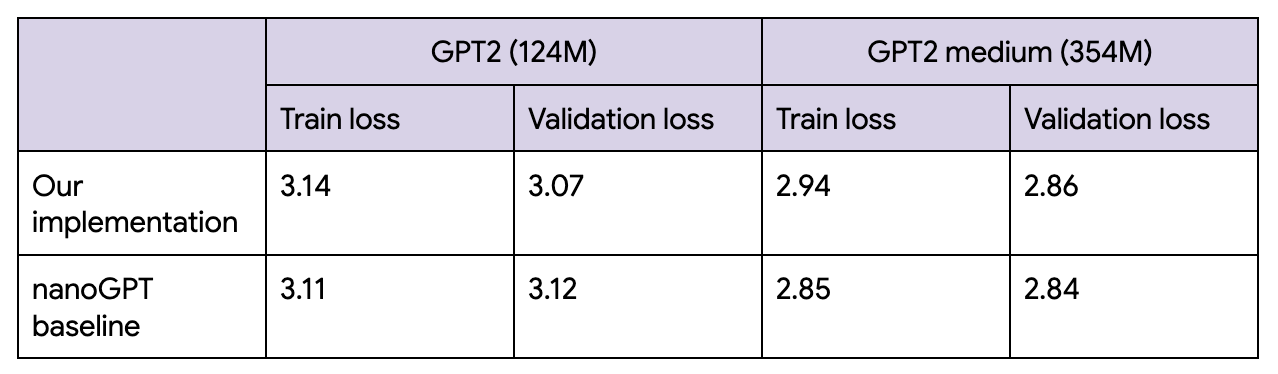
최종 손실은 필자에게 정말 매력적으로 느껴졌던 nanoGPT와 거의 일치했으며, 이 코드 예제를 작성하는 동안 이를 참고했습니다.
Cloud TPU를 사용하는 경우 'tpu-info‘ 명령(Cloud TPU Monitoring Debugging 패키지의 일부) 또는 가중치 및 바이어스 대시보드를 통해 TPU 사용률을 모니터링할 수도 있습니다. TPU는 신나게 가동 중입니다!
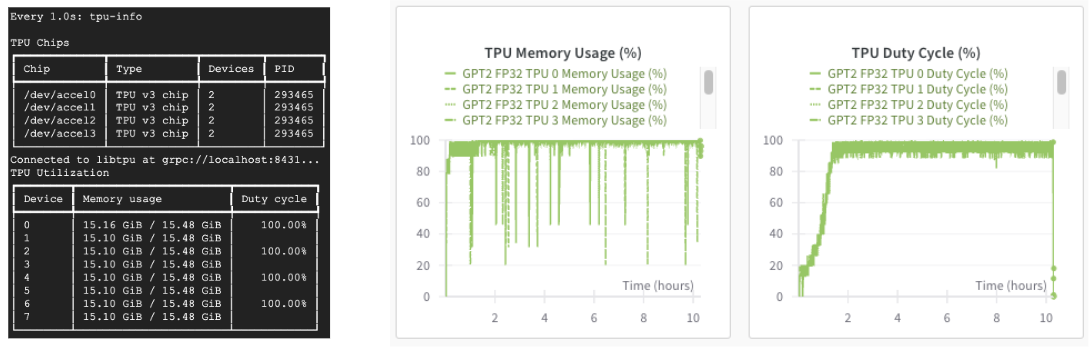
모델을 학습시킨 후 Orbax를 사용하여 저장할 수 있습니다.
checkpointer = orbax.PyTreeCheckpointer()
train_state = nnx.pure(nnx.state(model))
checkpointer.save(checkpoint_path, train_state)GPT2 모델을 학습시키는 데 필요한 거의 모든 내용은 이것이 다입니다. 전체 노트북에서 데이터 로딩, 하이퍼 매개변수, 메트릭과 같은 추가 세부 정보를 찾을 수 있습니다.
물론, GPT2는 지금 기준으로는 작은 모델이며 많은 선구적 연구소에서 수천억 개의 매개변수를 가진 모델을 학습시키고 있습니다. 하지만 이제 JAX와 TPU를 사용하여 작은 언어 모델을 개발하는 방법을 배웠으니 모델을 확장하는 방법에 대해서도 알아볼 준비가 되었습니다.
또한 MaxText를 사용하여 사전 구축된 최첨단 LLM을 학습시키거나 JAX LLM 예제 또는 Stanford Marin 모델을 참조하여 최신 모델을 처음부터 개발하는 방법을 배울 수도 있습니다.
개발자 여러분이 JAX와 TPU로 개발한 멋진 모델을 얼른 보고 싶습니다!

Announcing the Data Commons Gemini CLI extension

Grain 및 ArrayRecord를 사용하여 고성능 데이터 파이프라인 구축
KerasHub 사용하기: Hugging Face를 활용하는 간편한 엔드투엔드 머신러닝 워크플로 구축

Building with Gemini 3 in Jules

LangChain4j 통합을 통해 타사 언어 모델에도 개방되는 자바용 ADK
LLM의 다국어 혁신: 개방형 모델이 글로벌 커뮤니케이션을 지원하는 방법