

MongoDB Atlas용 Google Cloud Dataflow 템플릿의 주요 개선 사항을 소개하게 되어 기쁩니다. 사용자는 이제 JSON 데이터 유형에 대한 직접 지원을 활성화함으로써 MongoDB Atlas 데이터를 BigQuery에 원활하게 통합할 수 있으므로 복잡한 데이터 변환을 할 필요가 없습니다.
이처럼 간소화된 접근 방식 덕분에 시간과 리소스를 절약할 수 있어, 사용자는 고급 데이터 분석과 머신러닝을 통해 데이터의 잠재력을 최대한 활용할 수 있습니다.
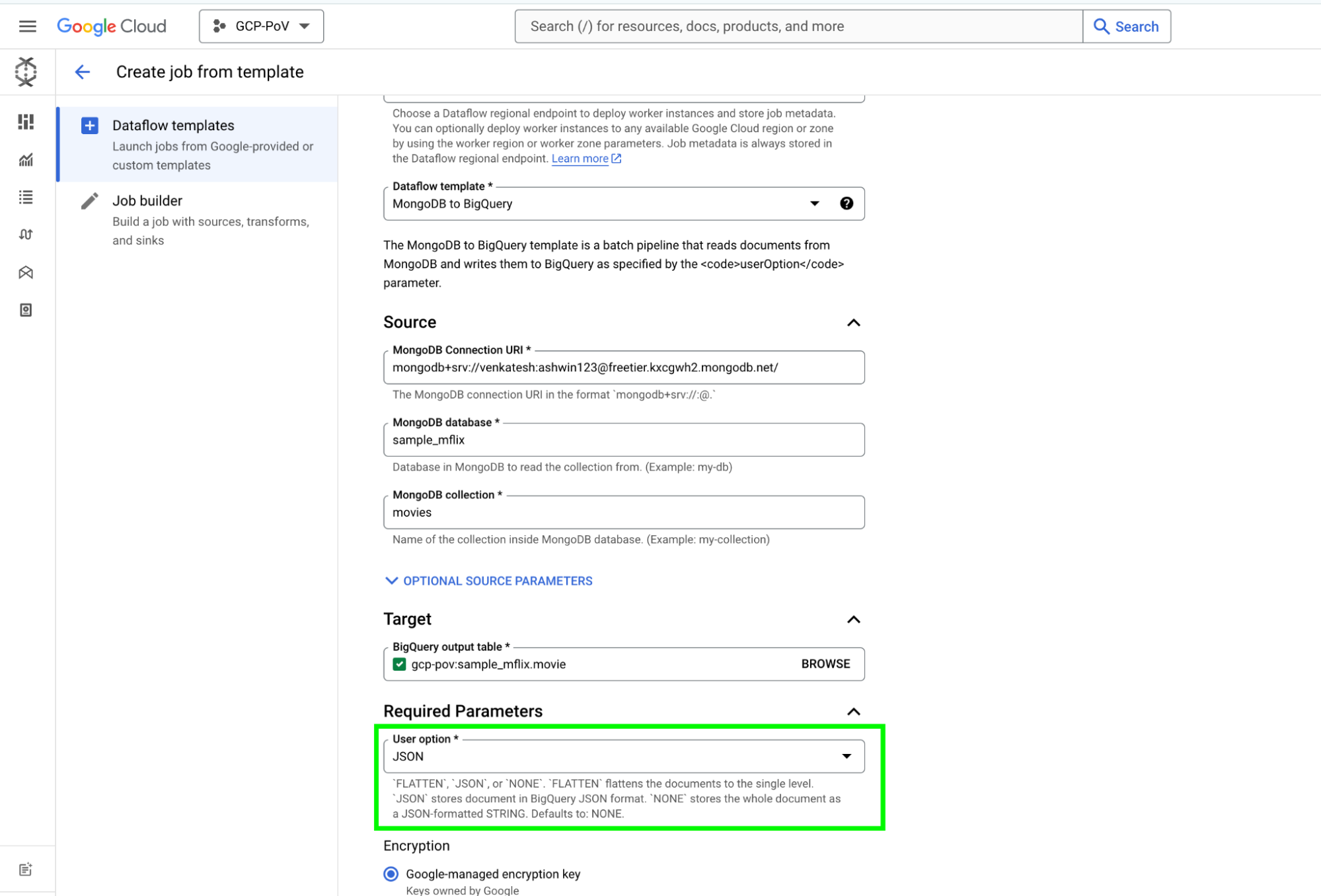
전통적으로, MongoDB Atlas 데이터를 처리하도록 설계된 Dataflow 파이프라인은 BigQuery에 로드하기 전에 데이터를 JSON 문자열로 변환하거나 복잡한 구조를 단일 수준의 중첩으로 평탄화해야 하는 경우가 많습니다. 이 접근 방식은 실행 가능하지만 다음과 같은 몇 가지 단점이 발생할 수 있습니다.
BigQuery의 Native JSON 형식은 사용자가 중간 변환 없이 MongoDB Atlas에서 중첩된 JSON 데이터를 BigQuery로 직접 로드할 수 있도록 하여 이러한 문제를 해결합니다.
이 접근 방식에는 다음과 같은 다양한 이점이 있습니다.
이 파이프라인의 주요 장점은 BigQuery에 로드된 MongoDB 데이터에 대해 BigQuery의 강력한 JSON 함수를 직접 활용할 수 있다는 것입니다. 따라서 복잡하고 시간이 많이 걸리는 데이터 변환 프로세스가 필요하지 않습니다. BigQuery 내의 JSON 데이터는 표준 BQML 쿼리를 사용하여 쿼리하고 분석할 수 있습니다.
간소화된 클라우드 기반 접근 방식을 선호하든 맞춤 설정 가능한 직접적 솔루션을 선호하든, Google Cloud 콘솔을 통해서나 github 저장소에서 구할 수 있는 코드를 실행하여 Dataflow 파이프라인을 배포할 수 있습니다.
요약하자면, Google의 Dataflow 템플릿은 MongoDB에서 BigQuery로 데이터를 전송하는 유연한 솔루션을 제공합니다. MongoDB의 Change Stream 기능을 사용하여 전체 컬렉션을 처리하거나 증분 변경 사항을 캡처할 수 있습니다. 특정 요구에 맞춰 파이프라인의 출력 형식을 맞춤 설정할 수 있습니다. 원시 JSON 표현을 선호하든 개별 필드가 있는 평면화된 스키마를 선호하든, userOption 매개변수를 통해 쉽게 구성할 수 있습니다. 또한 UDF(사용자 정의 함수)를 사용하여 템플릿 실행 중에 데이터 변환을 수행할 수 있습니다.
Dataflow 파이프라인에서 BigQuery Native JSON 형식을 채택하면 데이터 처리 워크플로의 효율성, 성능, 비용 효율성을 크게 향상시킬 수 있습니다. 이 강력한 조합을 통해 데이터에서 가치 있고 유용한 정보를 추출하고 데이터 기반 의사 결정을 내릴 수 있습니다.
Google 설명서를 따라 MongoDB Atlas와 BigQuery의 Dataflow 템플릿을 설정하는 방법을 알아보세요.

Building production AI on Google Cloud TPUs with JAX

Announcing the Data Commons Gemini CLI extension

Google Colab is Coming to VS Code

Stanford의 Marin 파운데이션 모델: JAX를 사용하여 개발된 최초의 완전 개방형 모델

Building with Gemini 3 in Jules

Firebase Studio로 에이전트 AI 개발 진전