

지난 2월 저희는 Gemini 모델 제작에 사용된 동일한 연구와 기술을 이용해 개발한 경량의 최첨단 개방형 모델 제품군 Gemma를 발표했습니다. 인상적인 미세 조정 변형, Kaggle 노트북, 도구와 서비스로의 통합, MongoDB 같은 데이터베이스를 사용하는 RAG 레시피 등, 커뮤니티의 놀라운 반응은 정말 고무적이었습니다.
오늘은 Gemma 제품군에 처음으로 새로 추가되는 모델을 발표하게 되어 기쁘게 생각합니다. 이번 추가를 계기로 ML 개발자가 책임감 있게 혁신할 수 있는 가능성이 더욱 확대됩니다. 이번 추가에는 명령 추종뿐 아니라 코드 완성 및 생성 작업을 위한 CodeGemma와 연구 실험을 위해 효율성을 최적화한 아키텍처인 RecurrentGemma가 포함됩니다. 또한, 커뮤니티와 파트너로부터 청취한 소중한 의견을 토대로 개선을 하고자 Gemma와 약관에 대한 업데이트 내용을 공유해 드리겠습니다.
CodeGemma는 Gemma 모델의 기반을 활용하여 커뮤니티에 강력하면서도 가벼운 코딩 기능을 제공합니다. CodeGemma 모델은 코드 완성 및 코드 생성 작업을 전문으로 하는 7B 사전 학습 변형, 코드 채팅 및 명령 추종을 위한 7B 명령 조정 변형, 로컬 컴퓨터에 맞는 빠른 코드 완성을 위한 2B 사전 학습 변형으로 제공됩니다. CodeGemma 모델은 다음과 같은 몇 가지 장점을 제공합니다.
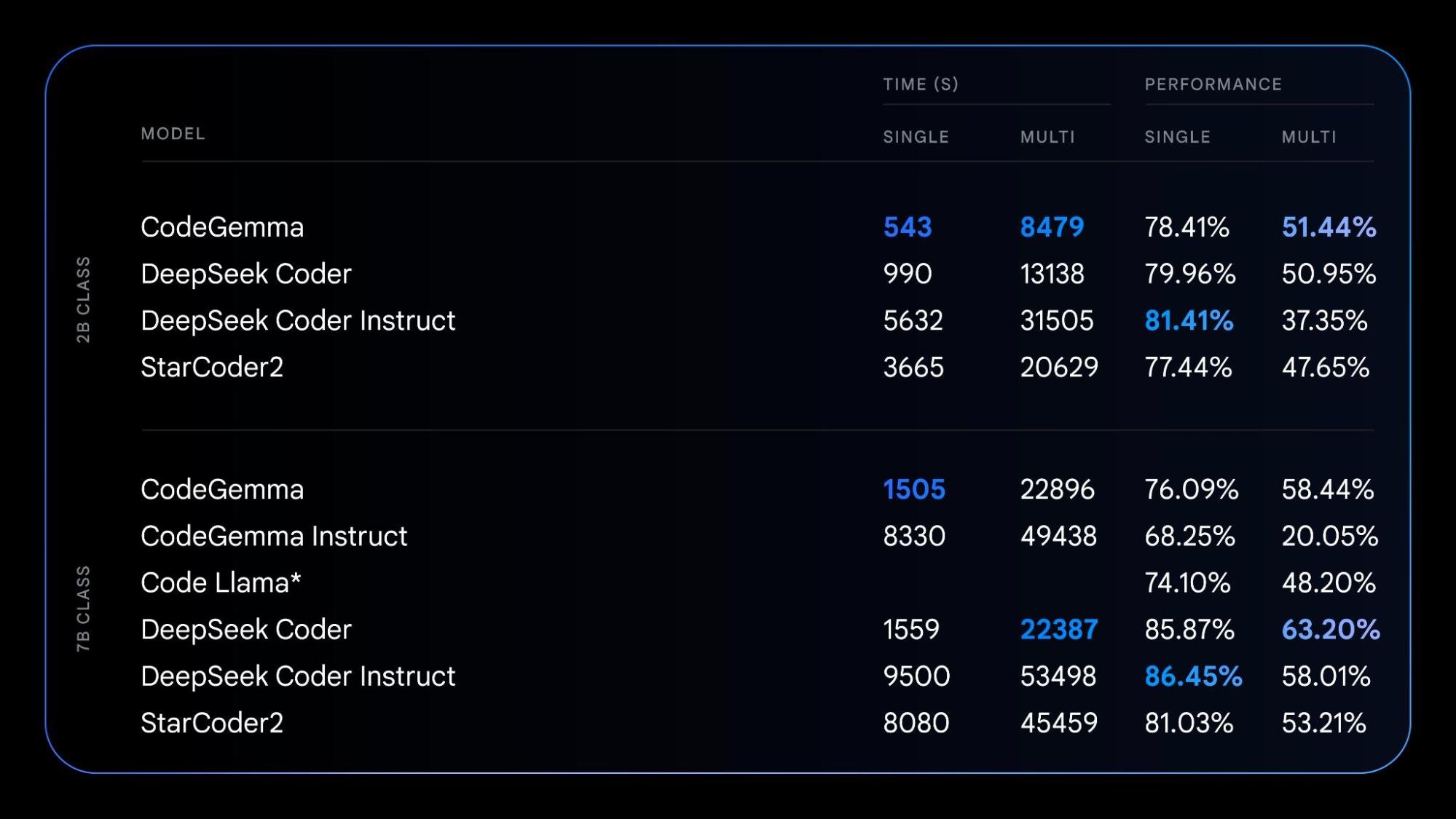
보고서에서 CodeGemma에 관해 자세히 알아보거나 이 빠른 시작 가이드에서 CodeGemma를 사용해 보세요.
RecurrentGemma는 순환 신경망과 로컬 어텐션을 활용하여 메모리 효율을 높여주는 모델로, 기술적으로 매우 독특합니다. RecurrentGemma의 고유한 아키텍처는 Gemma 2B 모델과 유사한 벤치마크 점수 성능을 달성하면서도 다음과 같은 몇 가지 장점을 제공합니다.
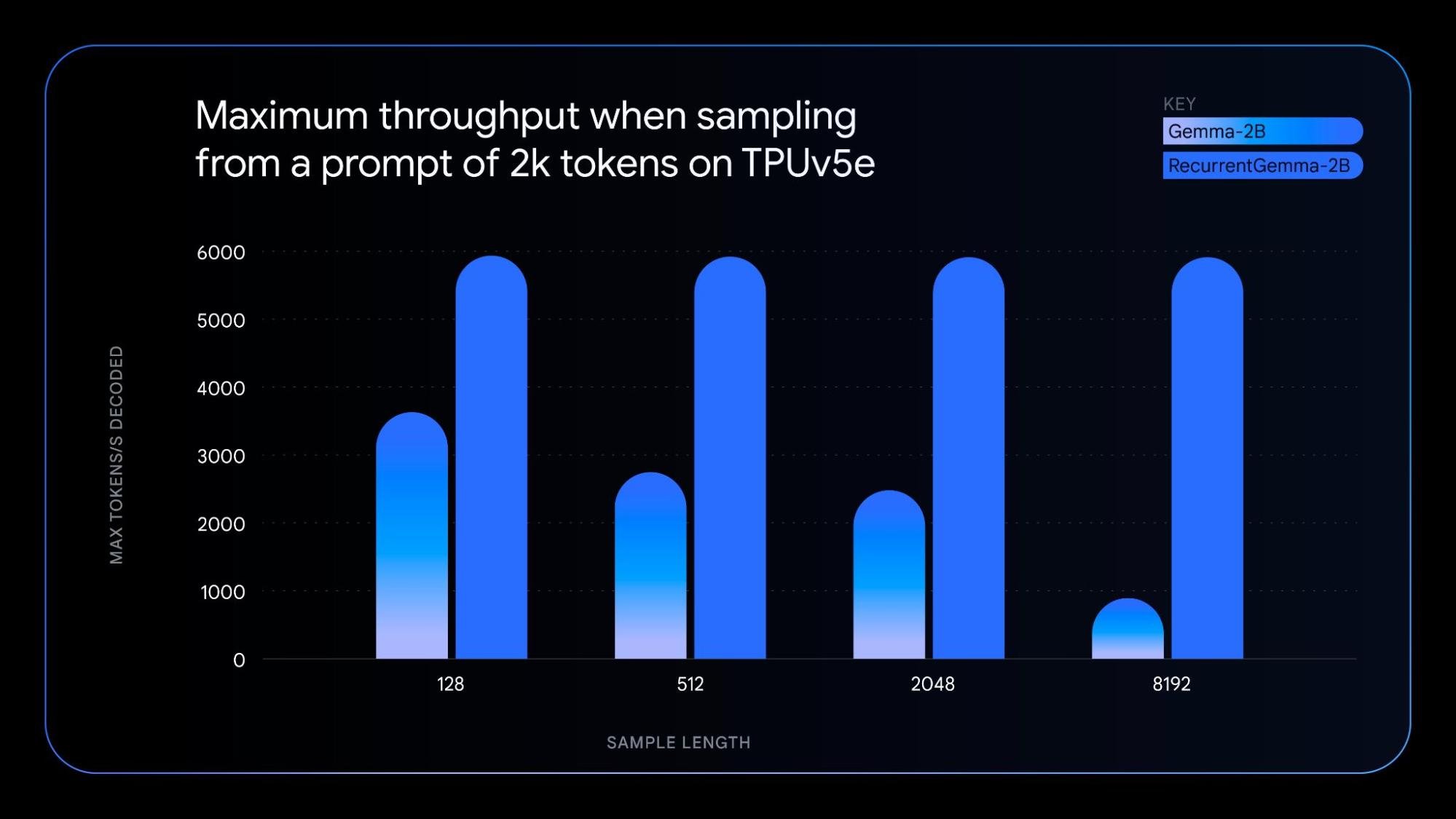
기반 기술을 이해하려면 이 논문을 확인해 보세요. 실용적인 탐색 분석을 위해 모델을 미세 조정하는 방법을 보여주는 노트북을 사용해 보세요.
새로운 모델 변형은 원래의 Gemma 모델과 동일한 원칙에 따라 다음을 제공합니다.
- CodeGemma와 RecurrentGemma 모두: JAX로 개발되고 JAX, PyTorch, Hugging Face Transformer, Gemma.cpp와 호환됩니다. 노트북, 데스크톱, NVIDIA GPU, Google Cloud TPU를 비롯한 다양한 하드웨어 전반에 걸쳐 로컬 실험과 비용 효율적인 배포를 지원합니다.
- CodeGemma: 또한, Keras, NVIDIA NeMo, TensorRT-LLM, Optimum-NVIDIA, MediaPipe와도 호환되고 Vertex AI에서 사용 가능합니다.
- RecurrentGemma: 앞서 언급한 모든 제품에 대한 지원은 향후 몇 주 내에 제공될 예정입니다.
새로운 모델 변형과 더불어 성능 개선 사항이 포함된 Gemma 1.1을 출시할 예정입니다. 또한 더 많은 유연성을 제공하기 위해 개발자 의견을 경청하고 버그를 수정하고 검색어를 업데이트했습니다.
이러한 첫 Gemma 모델 변형은 오늘 Kaggle, Hugging Face, Vertex AI Model Garden에서 시작해 전 세계 다양한 장소에서 이용 가능합니다. 시작 방법은 다음과 같습니다.
CodeGemma 및 RecurrentGemma 모델을 사용해 보고 Kaggle을 통해 의견을 나눠주세요. AI 기반 콘텐츠 제작 및 이해의 미래를 함께 만들어 나갑시다.



