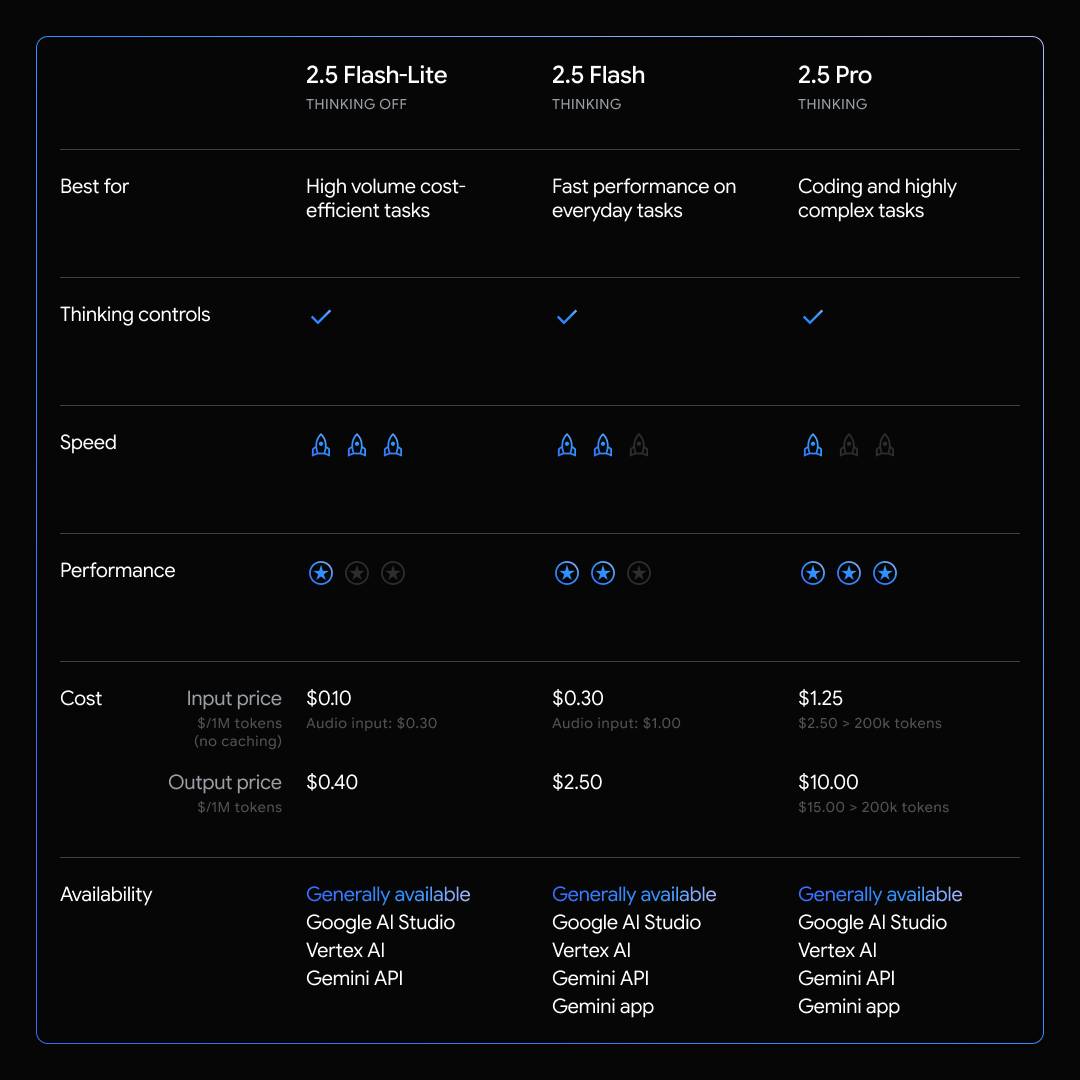
오늘 저희는 Gemini 2.5 모델 제품군에서 가장 빠르고, 비용이 적은(백만 입력당 0.10달러, 백만 출력당 0.40달러) 모델인 Gemini 2.5 Flash-Lite 정식 버전을 출시합니다. 저희는 더 까다로운 사용 사례에 대하여 선택적으로 켤 수 있는 네이티브 추론 기능을 사용해 2.5 Flash-Lite를 구축하고 달러당 지능의 최전선을 확장하였습니다. 2.5 Pro 및 2.5 Flash의 모멘텀을 기반으로 개발된 이 모델은 확장된 프로덕션 사용을 위해 준비된 일련의 2.5 모델을 완성합니다.
현재 가장 비용 효율적이고 빠른 2.5 모델
Gemini 2.5 Flash-Lite는 성능과 비용 사이의 균형을 이루면서도 특히 번역과 분류 등 지연 시간에 민감한 작업에서 품질을 저해하지 않습니다.
이 모델의 장점은 다음과 같습니다.
- 동급 대비 최고의 속도: Gemini 2.5 Flash-Lite는 폭넓은 샘플 프롬프트에서 2.0 Flash-Lite 및 2.0 Flash보다 지연 시간이 짧습니다.
- 비용 효율성: 현재 가장 비용이 적은 2.5 모델로, 가격은 백만 입력 토큰당 0.10달러 및 백만 출력 토큰당 0.40달러입니다. 덕분에 대량의 요청을 적당한 비용으로 처리할 수 있습니다. 또한 오디오 입력 가격을 미리보기 버전 출시 때보다 40% 낮췄습니다.
- 스마트하고 작은 크기: 코딩, 수학, 과학, 추론 및 멀티모달 이해를 포함한 다양한 업계 기준치에서 2.0 Flash-Lite보다 전반적으로 보다 고품질을 보여줍니다.
- 완벽한 기능: 2.5 Flash-Lite로 개발하는 경우 백만 토큰 맥락 범위, 제어할 수 있는 사고 예산 및 Google 검색으로 그라운딩, 코드 실행, URL 컨텍스트 같은 Google의 모든 네이티브 도구에 대한 지원을 이용할 수 있습니다.
Gemini 2.5 Flash-Lite를 사용하는 모습
2.5 Flash-Lite를 출시한 이래 놀라울 정도로 성공적인 개발 사례를 이미 몇 차례나 확인할 수 있었습니다. 그중에서도 공유하고자 하는 사례는 다음과 같습니다.
- Satlyt는 위성 데이터를 처리하고, 궤도 내 원격 측정 자료, 자율 작업 관리 및 위성 간 통신 파싱을 실시간으로 요약한 내용을 활용하는 방식을 바꿀 탈중앙화 우주 컴퓨팅 플랫폼을 개발하고 있습니다. 2.5 Flash-Lite의 속도 덕분에 주요 선내 진단에 대한 지연 시간을 45% 감축할 수 있었으며 기초 모델과 비교하여 전력 소비가 30% 감소했습니다.
- HeyGen은 AI를 사용하여 동영상 콘텐츠용 아바타를 만들고 Gemini 2.5 Flash-Lite를 활용하여 동영상 계획을 자동화하고, 콘텐츠를 분석 및 최적화하며, 동영상을 180개 이상의 언어로 번역합니다. 이를 통해 전 세계 사용자를 위한 맞춤화된 경험을 제공할 수 있습니다.
- DocsHound는 Gemini 2.5 Flash-Lite를 사용하여 짧은 지연 시간에 긴 동영상을 처리하고 수천 장의 스크린샷을 추출하여 제품 데모를 문서로 변환합니다. 이렇게 하면 동영상이 기존 방식보다 훨씬 빠르게 종합적인 문서 및 AI 에이전트를 위한 학습 데이터로 변환됩니다.
- Evertune는 AI 모델 전반에서 브랜드가 어떻게 표현되는지 이해하는 것을 돕습니다. 분석 및 보고서 생성 속도를 극적으로 올려주는 Gemini 2.5 Flash-Lite는 판도를 바꿀 정도의 혁신을 불러왔습니다. 이 모델의 빠른 성능 덕분에 브랜드는 빠르게 대량의 모델 출력을 스캔하고 종합하여 고객에게 동적이고 시기적절한 유용한 정보를 제공할 수 있습니다.
코드에 “gemini-2.5-flash-lite”를 지정하여 2.5 Flash-Lite를 사용할 수 있습니다. 미리보기 버전을 사용하고 있는 경우 동일한 기본 모델인 “gemini-2.5-flash-lite”로 전환할 수 있습니다. Flash-Lite의 미리보기 별칭은 8월 25일에 삭제될 예정입니다.
개발할 준비가 되셨나요? 지금 Google AI Studio 및 Vertex AI에서 Gemini 2.5 Flash-Lite 정식 버전을 사용해 보세요.