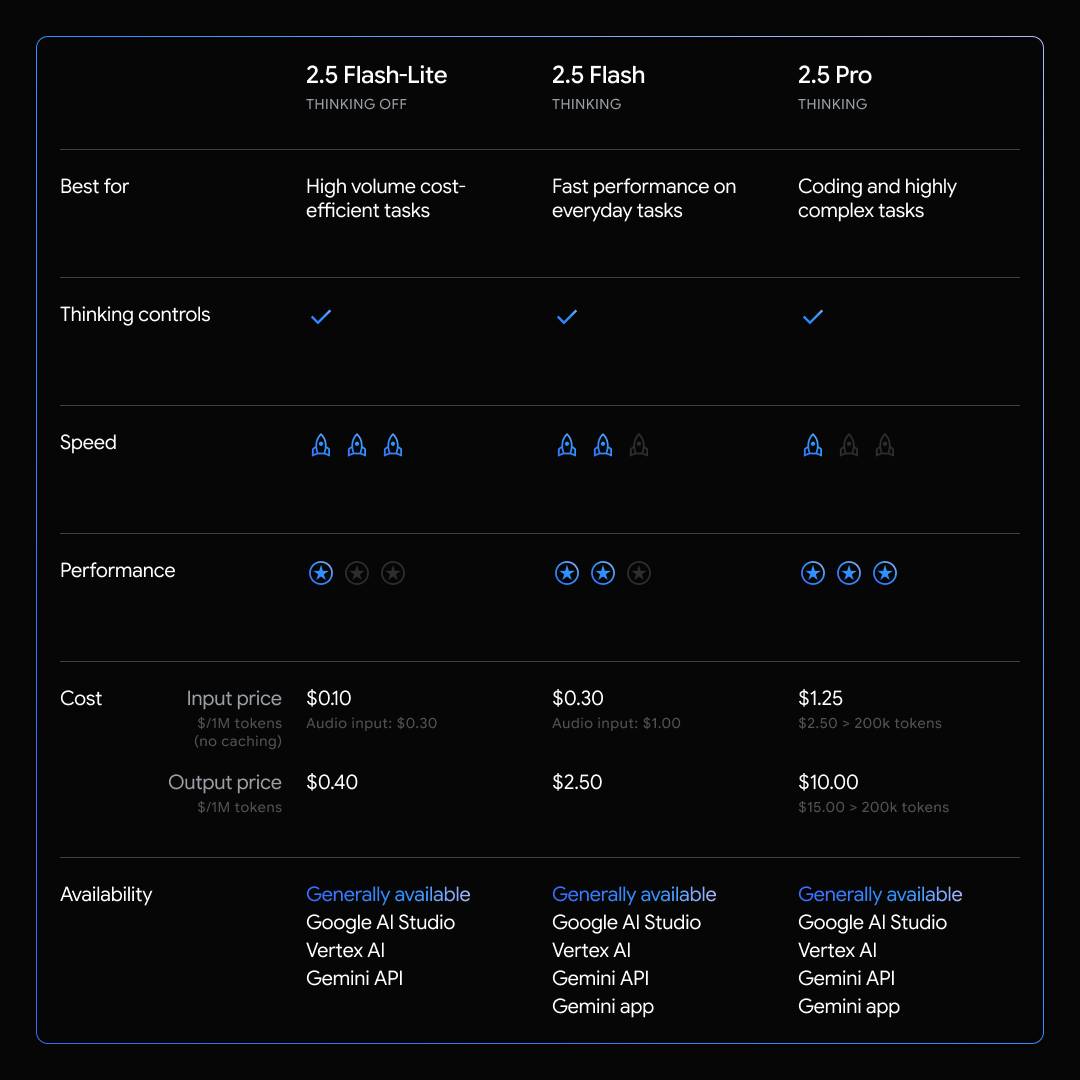
Today, we’re releasing the stable version of Gemini 2.5 Flash-Lite, our fastest and lowest cost ($0.10 input per 1M, $0.40 output per 1M) model in the Gemini 2.5 model family. We built 2.5 Flash-Lite to push the frontier of intelligence per dollar, with native reasoning capabilities that can be optionally toggled on for more demanding use cases. Building on the momentum of 2.5 Pro and 2.5 Flash, this model rounds out our set of 2.5 models that are ready for scaled production use.
Our most cost-efficient and fastest 2.5 model yet
Gemini 2.5 Flash-Lite strikes a balance between performance and cost, without compromising on quality, particularly for latency-sensitive tasks like translation and classification.
Here’s what makes it stand out:
- Best in-class speed: Gemini 2.5 Flash-Lite has lower latency than both 2.0 Flash-Lite and 2.0 Flash on a broad sample of prompts.
- Cost-efficiency: It’s our lowest-cost 2.5 model yet, priced at $0.10 / 1M input tokens and $0.40 output tokens, allowing you to handle large volumes of requests affordably. We have also reduced audio input pricing by 40% from the preview launch.
- Smart and small: It demonstrates all-around higher quality than 2.0 Flash-Lite across a wide range of benchmarks, including coding, math, science, reasoning, and multimodal understanding.
- Fully featured: When you build with 2.5 Flash-Lite, you get access to a 1 million-token context window, controllable thinking budgets, and support for native tools like Grounding with Google Search, Code Execution, and URL Context.
Gemini 2.5 Flash-Lite in action
Since the launch of 2.5 Flash-Lite, we have already seen some incredibly successful deployments, here are some of our favorites:
- Satlyt is building a decentralized space computing platform that will transform how satellite data is processed and utilized for real-time summarization of in-orbit telemetry, autonomous task management, and satellite-to-satellite communication parsing. 2.5 Flash-Lite’s speed has enabled a 45% reduction in latency for critical onboard diagnostics and a 30% decrease in power consumption compared to their baseline models.
- HeyGen uses AI to create avatars for video content and leverages Gemini 2.5 Flash-Lite to automate video planning, analyze and optimize content, and translate videos into over 180 languages. This allows them to provide global, personalized experiences for their users.
- DocsHound turns product demos into documentation by using Gemini 2.5 Flash-Lite to process long videos and extract thousands of screenshots with low latency. This transforms footage into comprehensive documentation and training data for AI agents much faster than traditional methods.
- Evertune helps brands understand how they are represented across AI models. Gemini 2.5 Flash-Lite is a game-changer for them, dramatically speeding up analysis and report generation. Its fast performance allows them to quickly scan and synthesize large volumes of model output to provide clients with dynamic, timely insights.
You can start using 2.5 Flash-Lite by specifying “gemini-2.5-flash-lite” in your code. If you are using the preview version, you can switch to “gemini-2.5-flash-lite” which is the same underlying model. We plan to remove the preview alias of Flash-Lite on August 25th.
Ready to start building? Try the stable version of Gemini 2.5 Flash-Lite now in Google AI Studio and Vertex AI.