

XNNPack は、すべてのモデルで TensorFlow Lite のデフォルトの CPU 推論エンジンとして使われています。今回、これがモバイル、デスクトップ、ウェブ プラットフォームでゲーム チェンジャーとなる高速化を果たします。XNNPack では、最適化の一環として、畳み込み、深さ方向畳み込み、転置畳み込み、完全結合演算子の静的な重みを、推論計算に最適な内部レイアウトにパッキングし直しています。推論を行うときは、プロセッサのパイプラインに適したシーケンシャル パターンで再パッキングした重みにアクセスします。
推論時間の短縮にはコストがかかります。再パッキングとは、本質的に XNNPack 内部の重みの余分なコピーを作ることを指します。これまでは、XNNPack にインメモリ キャッシュを追加することで、そのコストを削減するという作業が行われてきました。このキャッシュを使えば、同じモデルを独立して実行する TFLite インタプリタ間でパッキングした重みを共有できます。
既存のキャッシュのいくつかの欠点に対処するため、TFLite XNNPack デリゲートの実装を改善しました。
1. キャッシュが匿名メモリに格納されるため、メモリが圧迫されるとディスクへのスワップが発生し、パフォーマンスが低下します。
2. プロセスを開始するたびに、最初の重みのパッキングをやり直す必要があります。
3. 再パッキングは、元の TFLite の重みを読み取って新しいバッファに書き込む処理です。この処理を行っている間は、ピークメモリ使用量が高くなります。
4. XNNPack デリゲートを通して適切にキャッシュを利用できるようにするには、面倒な手順と慎重なライフサイクル管理が必要になります。
5. プロセス間で重みを共有することはできません。
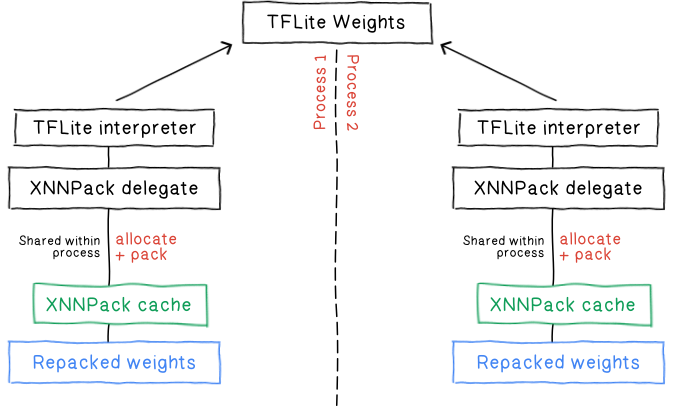
XNNPack を更新し、重みキャッシュ プロバイダを実装できるインターフェースを提供しました。重みキャッシュ プロバイダはディクショナリとして動作し、XNNPack はそこに重みを格納したり、パッキング済みのバッファにアクセスしたりします。主な機能は次のとおりです。
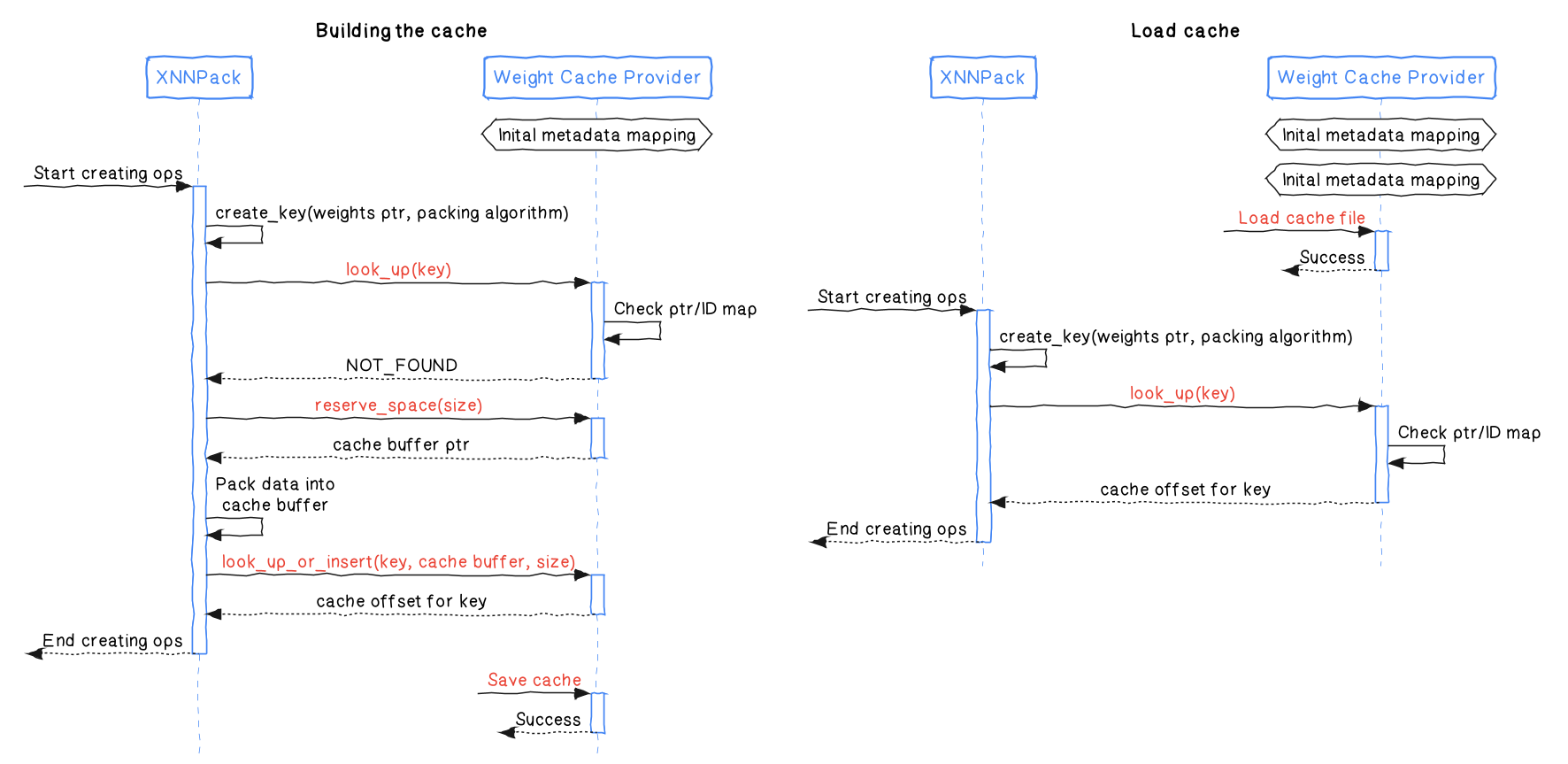
look_up は、パッキング済みのバッファのキーを参照し、一意の識別子(NotFound を表す予約された特別な識別子)を返します。その後この識別子を使うと、バッファのアドレスを取得できます。reserve_space は、所定のサイズの情報を格納できるバッファを予約します。バッファは、look_up_or_insert を使ってコミットする必要があります。look_up_or_insert は、指定されたキーに一致するバッファがキャッシュ プロバイダに存在するかどうかをチェックします。存在しない場合は、所定のデータがキャッシュ プロバイダにコミットされます。この関数は識別子も返します。この識別子を使うと、バッファのアドレスを取得できます。offset_to_addr は、look_up および look_up_or_insert が返す識別子を受け取り、バッファのアドレスを返します。XNNPack と重みキャッシュ プロバイダの連携の詳細を次の図に示します。
TFLite デリゲートは、この新しいインターフェースと専用の重みキャッシュ プロバイダを使います。このプロバイダは、パッキング済みの重みをディスクに直接保存し、ディスクから直接読み込むことができます。TFLite では、かなり前からフラットバッファとファイルベースのメモリ マッピングを使っています。同じ技術を活用してギャップを埋め、次のようなメリットを実現しています。
パッキング済みの重みをディスクに永続化することで、モデルを読み込むたびにコストのかかる再パッキングのプロセスを行う必要がなくなります。これにより、起動待ち時間とピークメモリ使用量の両方が大幅に削減されます。初回の作成処理においても、パッキング済みデータの重複除去が可能になるので、同じデータの再パッキングが回避され、パッキングのパフォーマンスがさらに向上します。
mmap は、オペレーティング システムの仮想メモリ管理を利用して、システム全体のメモリ使用量とパフォーマンスを最適化します。今回の場合、ニューラル ネットワークの演算の重み定数など、大きなファイルに読み取り専用でランダム アクセスする際に特に有利です。
パッキング済みのデータがディスクに保存されているため、XNNPack キャッシュで匿名メモリを使う必要がなくなります。匿名メモリは、メモリが圧迫されるとパフォーマンスの問題が発生しやすくなります。代わりにオペレーティング システムの仮想メモリ管理を使うことで、スムーズな演算が可能になります。
mmap を使うと、ファイル システムとメモリとの間でデータをコピーする必要がなくなるので、大幅にオーバーヘッドが低下し、アクセス時間が短縮されます。
ファイルのマッピングとメモリ使用量の詳細については、mmap のマニュアル ページやその他の興味深い文献を直接ご覧ください。
mmap ベースのファイル読み込みを行うと、各プロセスの仮想アドレス空間が同じ物理メモリのページにマッピングされるので、複数のプロセス間でシームレスに重みを共有できるようになります。複数のプロセスが同じメモリを共有するので、全体的なメモリ フットプリントを削減できるだけでなく、モデルの読み込み時間を全般的に短縮できます。
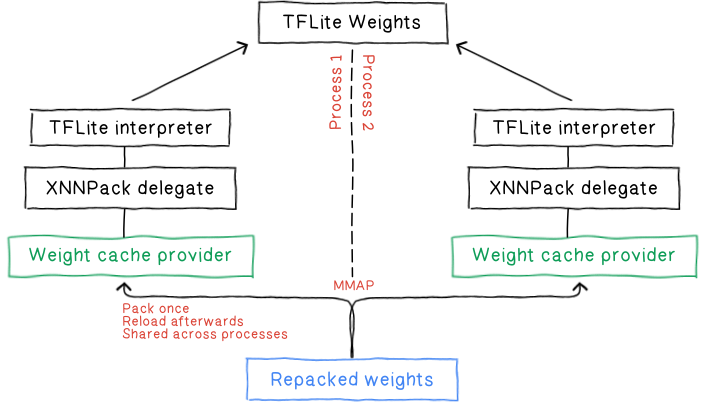
ユーザーがアプリケーション ライフタイム全体でキャッシュ オブジェクトを設定して管理する必要はなく、単純にキャッシュ ファイルのパスだけを渡せばよくなります。
std::unique_ptr<tflite::Interpreter> interpreter;
// XNNPack デリゲートのオプションを設定する。
TfLiteXNNPackDelegateOptions xnnpack_options = TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weight_cache_file_path = "/tmp/cache_file.xnn_cache";
// XNNPack デリゲートを作成して TFLite インタプリタに適用する。
// 初回起動時に静的な重みをパッキングして weights_cache に書き込む。
// 以降の実行では、これが自動的に読み込まれる。
TfLiteDelegate* delegate = TfLiteXNNPackDelegateCreate(&xnnpack_options);
interpreter->ModifyGraphWithDelegate(delegate);正確で効率的な推論を確実に行うには、特定の条件で XNNPack キャッシュを無効化することが不可欠です。
モデルの進化: モデルの重みや構造が変更された場合、キャッシュされたデータは古くなり、無効化する必要があります。これは、提供されたキャッシュパスのファイルを削除することを意味します。
XNNPack のアップグレード: XNNPack の内部パッキング アルゴリズムが更新されると、キャッシュされた重みに互換性がなくなり、キャッシュの再計算が必要になる場合があります。うれしいことに、XNNPack はこれを検出し、既存のキャッシュを自動的に置き換えます。
つまり、XNNPack による重みのパッキング方法や利用方法に影響を与える可能性がある変更が行われた場合は、キャッシュを無効化する必要があります。
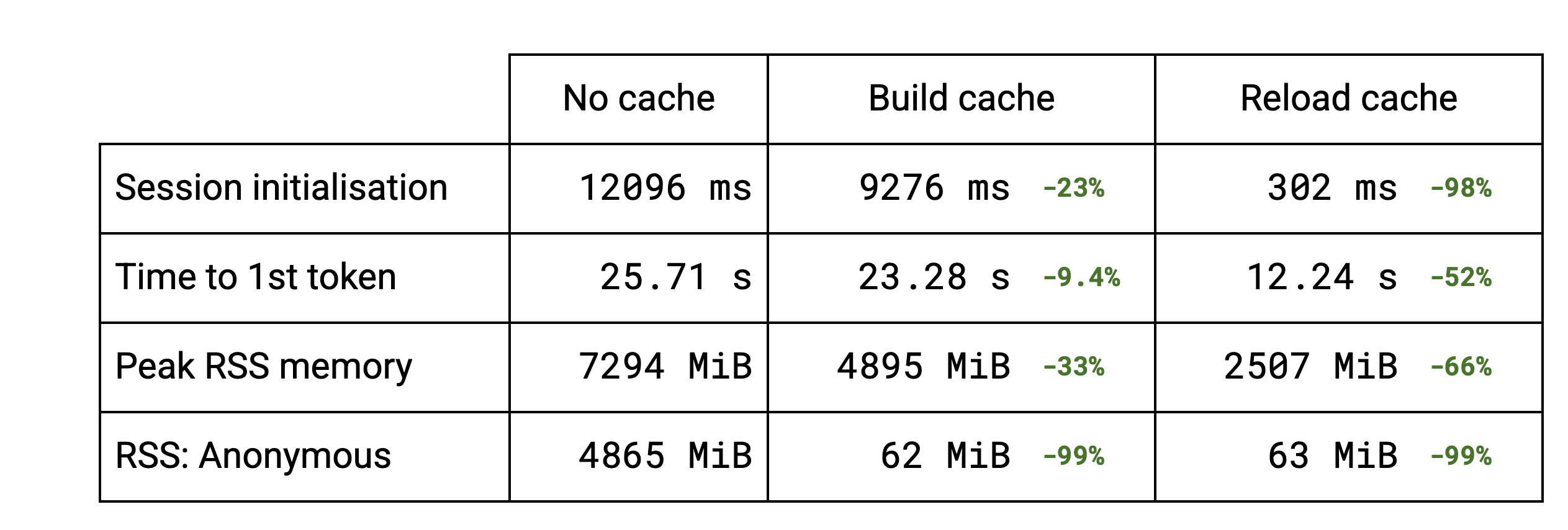
セッションの初期化の大部分が、重みのパッキング処理によって占められています。LLM では、複数のサブグラフが同じ重みを再利用しています。重複除去機能により、同じ重みを複数回パッキングすることを回避できるため、キャッシュの作成が高速になります。Stable Diffusion のような標準的なモデルでは、重複排除は行われないので、キャッシュをディスクに保存する初期化時間がわずかに長くなります。キャッシュを再読み込みする場合(2 回目以降の実行)、すべてのケースで初期化時間は以前の数分の 1 になります。
当然ながら、セッション初期化の改善により、LLM の最初のトークン出力までの時間が改善されます。ベンチマークでは、所要時間が約半分になっています。
このキャッシュの実装により、メモリ使用量が改善されていることもわかります。重複除去を利用できる LLM では、ピーク常駐セットサイズが低下しました。重複除去を利用できないモデルでは、変化は見られません。キャッシュを再読み込みすると、ピーク RSS がさらに低下します。TFLite のオリジナルのモデルを読み込んでメモリに取り込むことがなくなるためです。
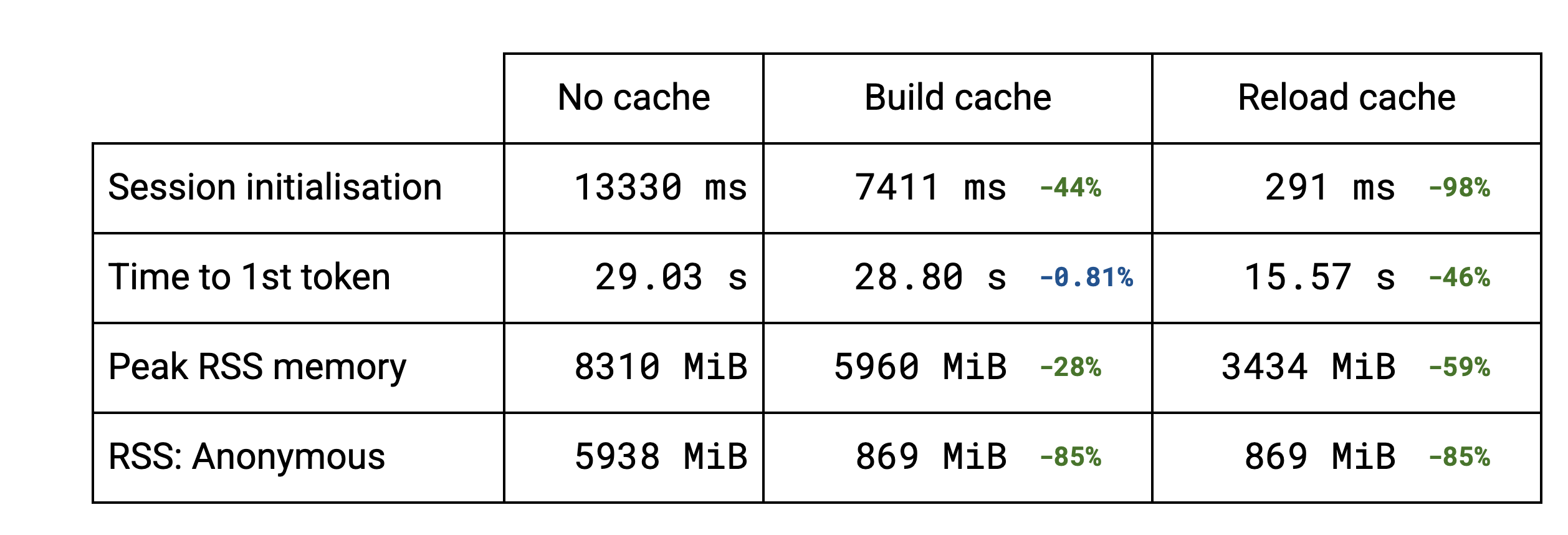
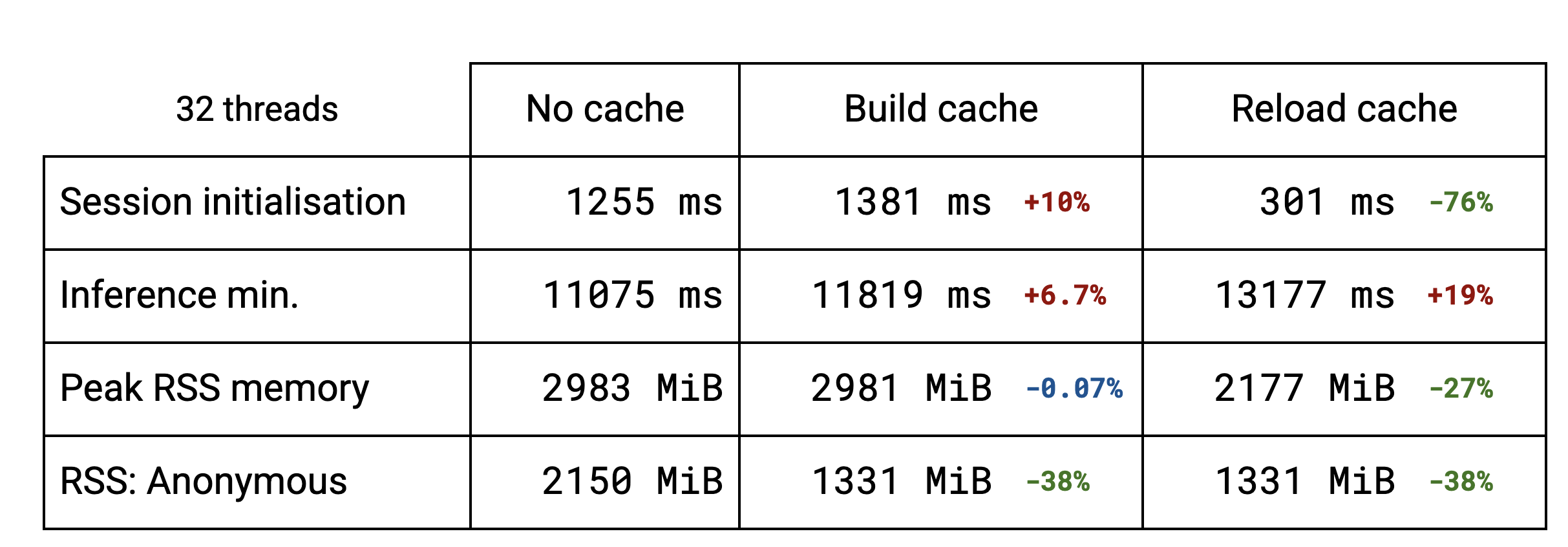
現在のところは、キャッシュとファイル システムが密接に結びついていますが、ファイルベースのマッピングではなく、従来どおりに割り当てられるメモリを使いたいユースケースでも、データ重複除去メカニズムを個別に利用できるようにしたいと考えています。mmap を使って匿名マッピングを作成することで、ほとんどの実装を再利用できるようになります。



