XNNPack is the default TensorFlow Lite CPU inference engine for all models. It delivers game changing speedups across mobile, desktop, and Web platforms. One of the optimizations employed in XNNPack is repacking the static weights of the Convolution, Depthwise Convolution, Transposed Convolution, and Fully Connected operators into an internal layout optimized for inference computations. During inference, the repacked weights are accessed in a sequential pattern that is friendly to the processors’ pipelines.
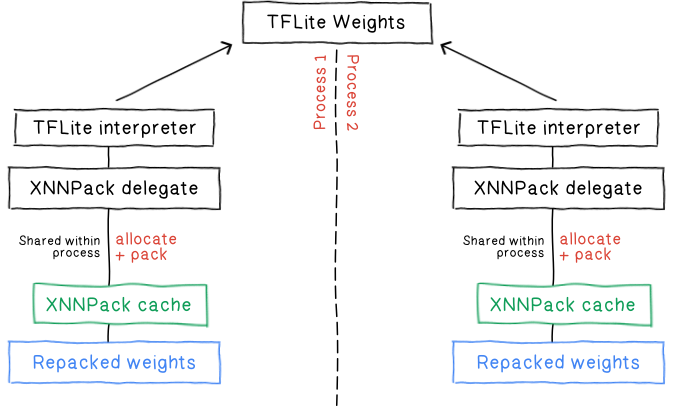
The inference latency reduction comes at a cost: repacking essentially creates an extra copy of the weights inside XNNPack. Previous efforts have been made to reduce that cost by adding an in-memorycache to XNNPack. This cache allows sharing the packed weights between independent TFLite interpreters that would run the same model independently.
TFLite XNNPack delegate implementation has been improved to address some of the shortcomings of the existing cache.
1. The cache lives in anonymous memory, which incurs swapping to disk in case of memory pressure, leading to poor performance.
2. It requires repacking the initial weights every time a process is started.
3. Because repacking reads the original TFLite weights and writes to a new buffer, this leads to a high peak memory usage during the packing.
4. It requires tedious steps and careful lifecycle management to properly enable caching through XNNPack delegate.
5. It doesn’t allow sharing the weights across processes.
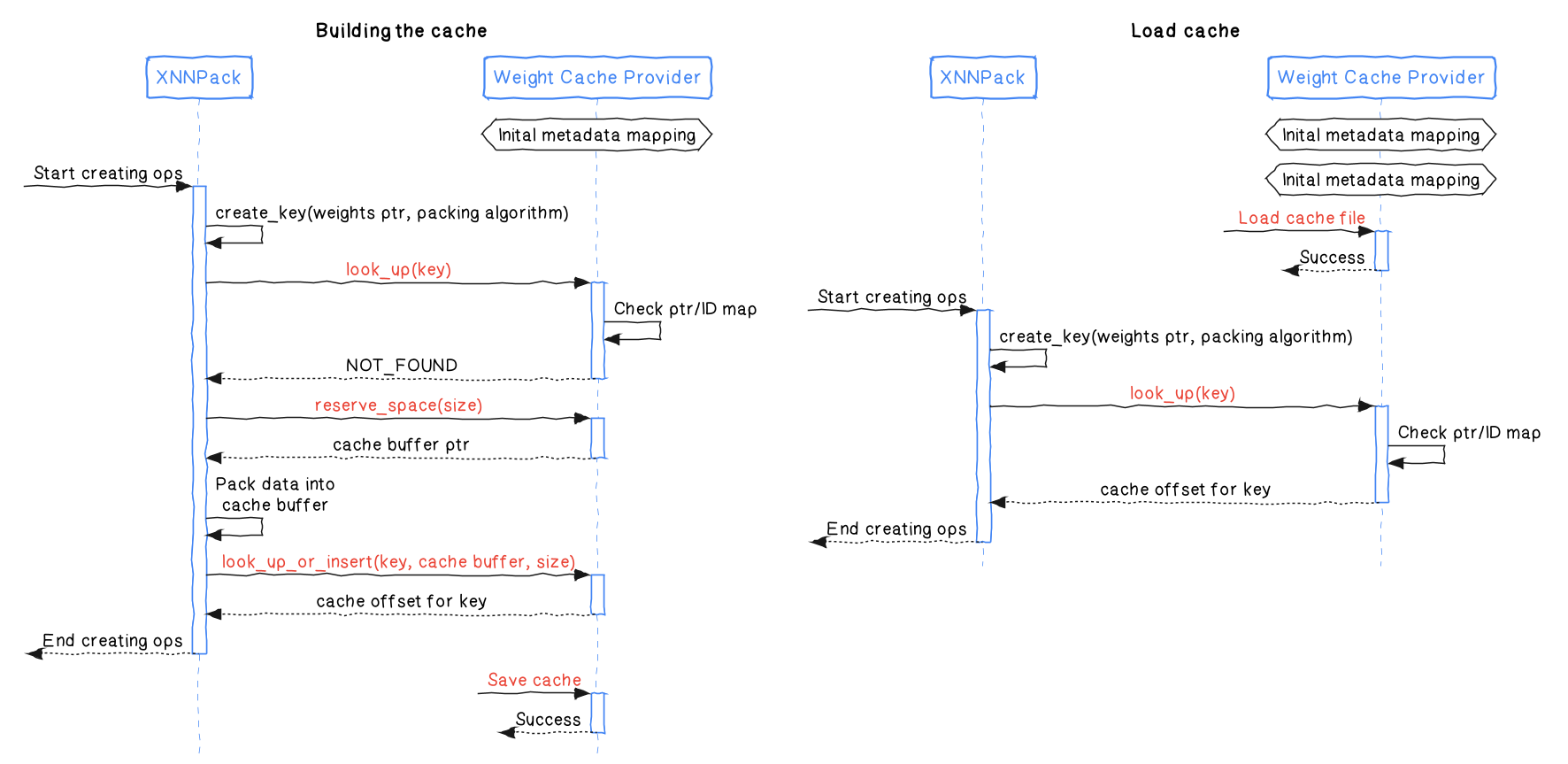
XNNPack has been updated and provides an interface that lets you implement a weight cache provider. A weight cache provider behaves as a dictionary that XNNPack will fill and query in order to access packed buffers. Here are its main functions.
look_up looks up a packed buffer key and returns a unique identifier (or a special identifier reserved for NotFound) that may be later used to retrieve the buffer address.reserve_space reserves a buffer that may be used to store information of a given size. That buffer then needs to be committed using look_up_or_insert.look_up_or_insert checks if a buffer matching the given key exists in the cache provider. If not, the given data is committed to the cache provider. This function also returns the identifier that may be used to retrieve the buffer address.offset_to_addr returns the buffer address from the identifier returned by look_up and look_up_or_insert.The interactions between XNNPack and the weight cache provider are illustrated in the following diagram.
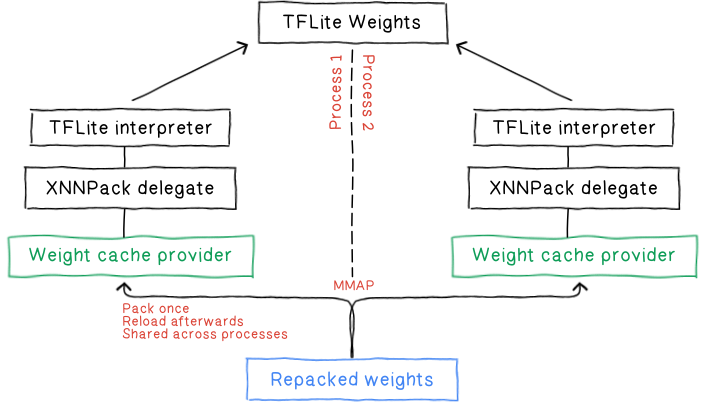
The TFLite Delegate now uses this new interface and has its own weight cache provider. This provider is capable of saving and loading the packed weights directly to / from disk. TFLite has been leveraging flatbuffer and file-backed memory mapping for a long time. We are filling the gap here by leveraging the same technique, for the following advantages.
Persisting packed weights on disk bypasses the costly repacking process each time a model is loaded. This translates to a significant reduction in both startup latency and peak memory usage. Even for the initial building, this offers packed data deduplication and further improves packing performance by avoiding repacking the same data again.
mmap leverages the operating system's virtual memory management allowing it to optimize overall system memory usage and performance. In our case, this is especially advantageous for random access bulky read-only file access, like a neural network’s operation’s constant weights for instance.
With packed data stored on disk, the XNNPack cache no longer relies on anonymous memory which can be prone to performance issues under memory pressure. Instead, it leverages the operating system's virtual memory management for smoother operation.
By eliminating the need to copy data between the file system and memory, mmap significantly reduces overhead and speeds up access times.
You can find more information about file mappings and memory usage directly from mmap’s man page and other interesting reads.
mmap-based file loading opens the door for seamless weight sharing between multiple processes as each process’ virtual address space maps to the same physical memory pages. This not only reduces the overall memory footprint as multiple processes share the same memory but also accelerates model loading across the board.
Instead of requiring the user to setup and manage the cache object throughout the application lifetime, they can simply provide a path to the cache file.
std::unique_ptr<tflite::Interpreter> interpreter;
// Setup the options for the XNNPack delegate.
TfLiteXNNPackDelegateOptions xnnpack_options = TfLiteXNNPackDelegateOptionsDefault();
xnnpack_options.weight_cache_file_path = "/tmp/cache_file.xnn_cache";
// Create and apply the XNNPack delegate to a TFLite interpreter.
// Static weights will be packed and written into weights_cache on the first run.
// They will be automatically loaded for all other runs.
TfLiteDelegate* delegate = TfLiteXNNPackDelegateCreate(&xnnpack_options);
interpreter->ModifyGraphWithDelegate(delegate);To guarantee accurate and efficient inference, it's crucial to invalidate the XNNPack cache under specific conditions:
Model Evolution: if your model's weights or structure change, the cached data becomes outdated and must be invalidated. This means removing the file at the provided cache path.
XNNPack Upgrades: updates to XNNPack's internal packing algorithm may result in incompatible cached weights, requiring the cache to be recomputed. Fortunately XNNPack is capable of detecting this and will replace the existing cache automatically.
In essence, any modification that could impact the way weights are packed or utilized by XNNPack should trigger a cache invalidation.
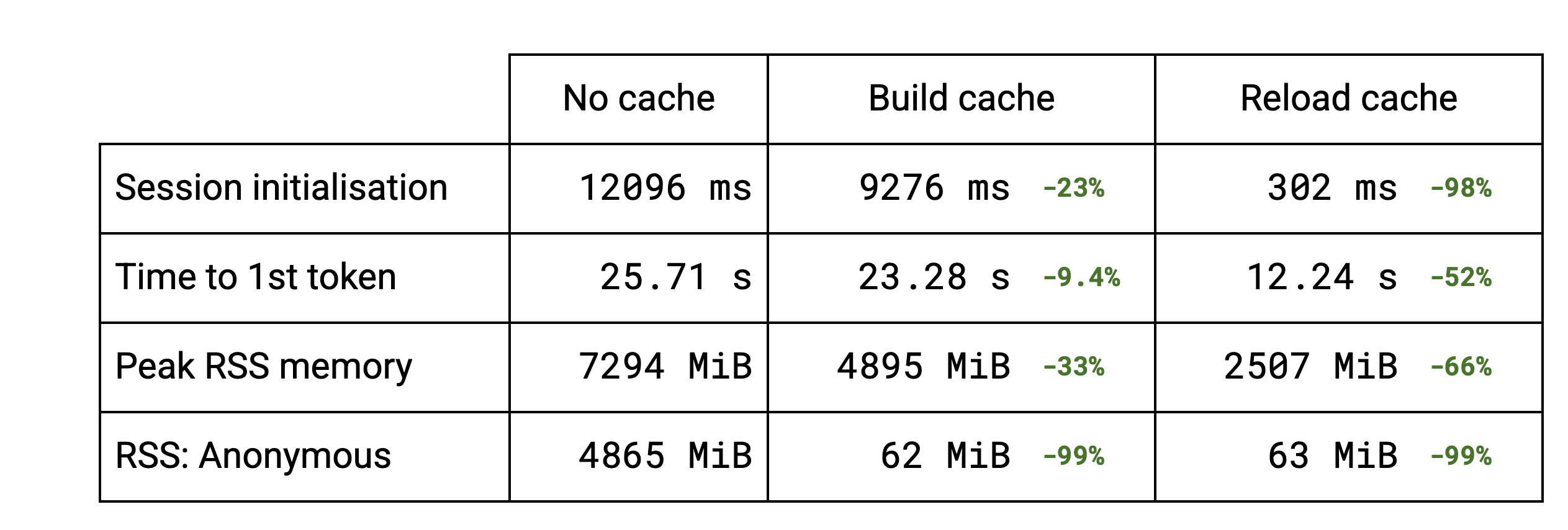
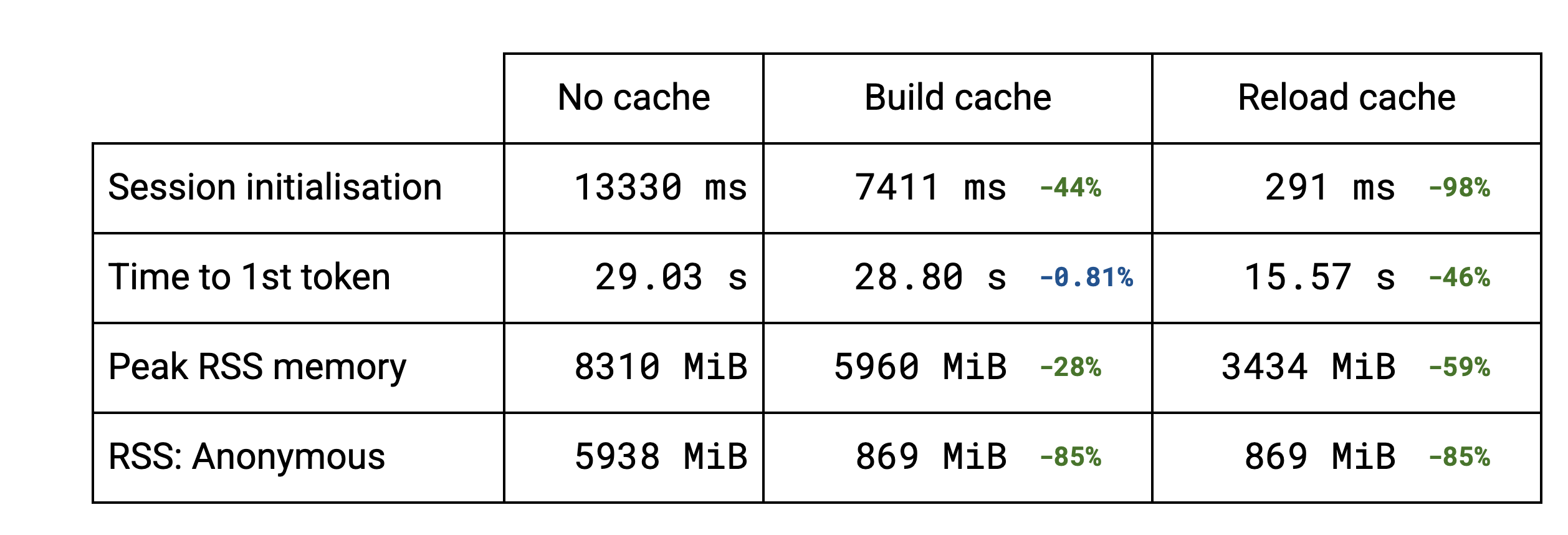
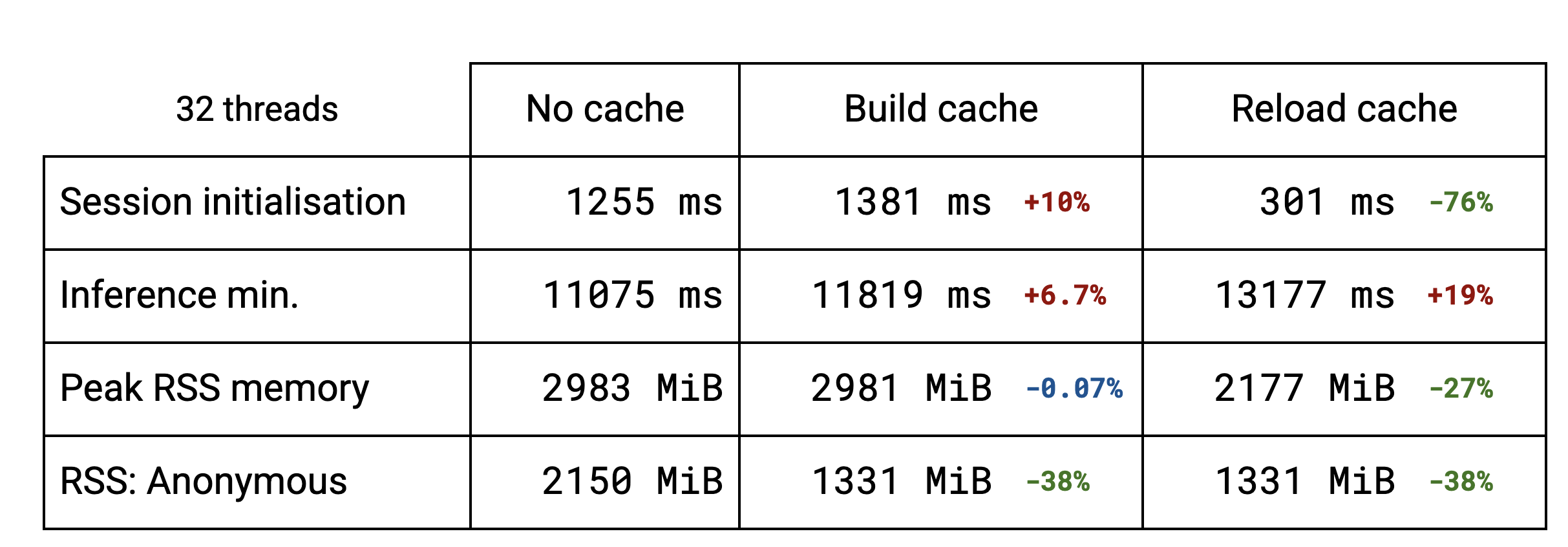
The session initialisation is dominated by the weight packing. For LLMs several subgraphs are reusing the same weights. Building the cache is faster because the deduplication functionality avoids packing those same weights multiple times. For more standard models, like stable diffusion, there is no deduplication and the slightly higher initialisation time is due to saving the cache to disk. Reloading the cache (from the 2nd run on) brings the initialisation down to a fraction of the previous time in all the cases.
The session initialisation improvement naturally affects the time to the first token for LLMs, roughly dividing it by 2 in the benchmarks.
The memory gains brought by the cache implementation can also be seen. The peak Resident Set Size is lowered for LLMs thanks to the deduplication. For other models that don’t benefit from the deduplication, there is no change. Reloading the cache brings the peak RSS even further down because the TFLite original models aren’t read anymore and therefore never get pulled into memory.
Currently the cache is tied to using the file system. We want to be able to take advantage of the data deduplication mechanism independently for use cases that do not want to trade traditional allocated memory with file-backed mappings. mmap allows making anonymous mappings which will allow reusing most of the implementation.