

Gemma モデルは、最初のリリース以来、1 億回以上ダウンロードされており、コミュニティではあらゆる種類のユースケースに対して、6 万以上のバリエーションが作成されています。以前の Gemma リリースの成功を踏まえて、Gemma オープン モデル ファミリーで最も機能的で高度なバージョンである Gemma 3 を紹介します。コミュニティからのフィードバックに耳を傾け、コンテキスト長の増加、マルチモダリティなど、特にリクエストが多かった機能を追加しています。
Link to Youtube Video (visible only when JS is disabled)
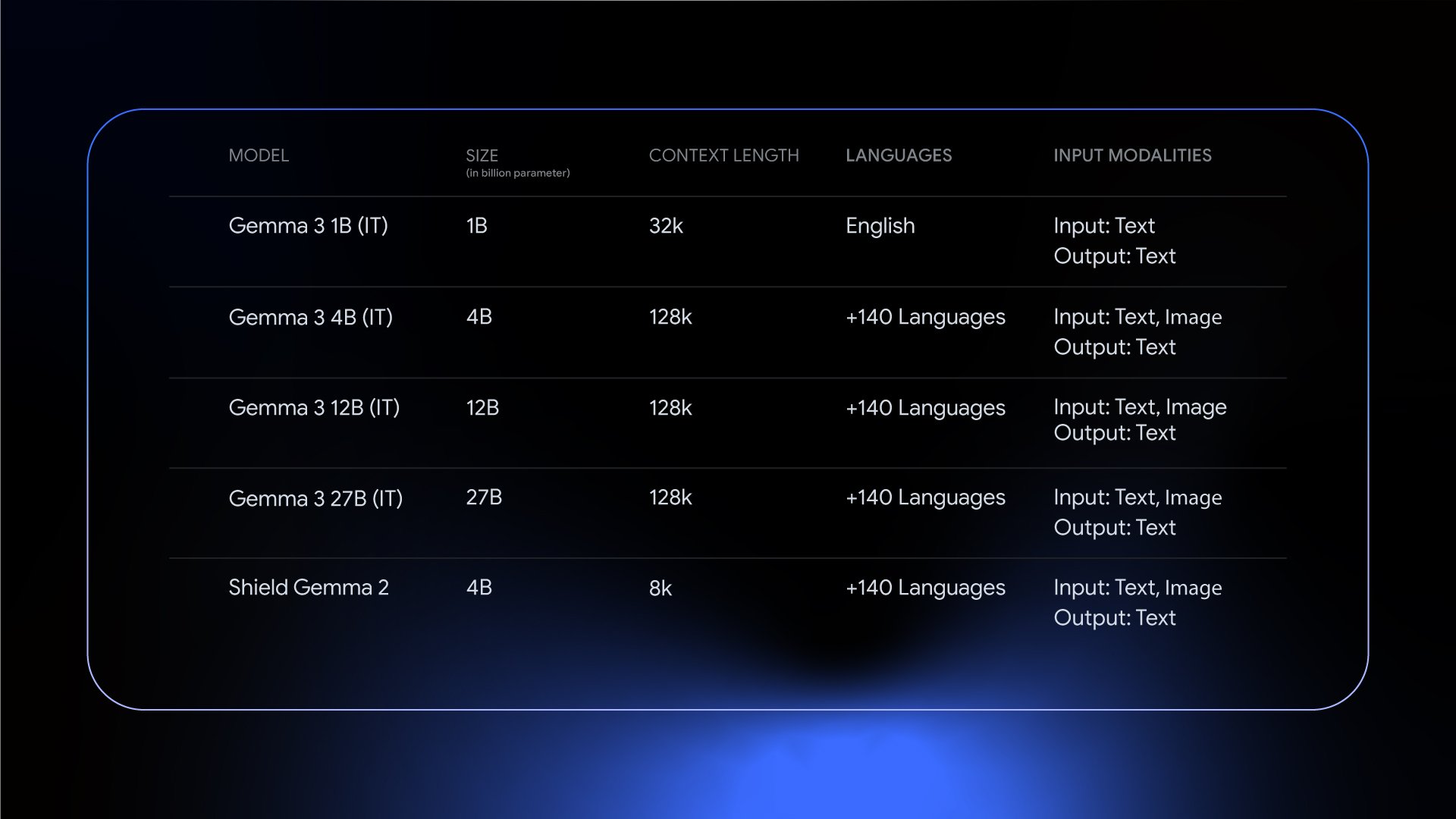
Gemma 3 はマルチモダリティを導入し、視覚言語入力とテキスト出力をサポートしています。最大 128k トークンのコンテキスト ウィンドウを処理し、140 以上の言語を理解するほか、数学、推論、チャット機能が向上し、構造化出力や関数呼び出しにも対応しています。Gemma 3 では、独自のユースケースやドメインに合わせてファインチューニングできる事前トレーニング済みモデルと、汎用インストラクション チューニング バージョンの両方が、4 つのサイズ(1B、4B、12B、27B)で利用できます。
Gemma の事前トレーニングと事後トレーニングのプロセスは、蒸留、強化学習、モデルマージの組み合わせによって最適化されています。このアプローチにより、数学、コーディング、そして命令に従う能力が向上します。Gemma 3 では、140 を超える言語で多言語サポートを向上させるため、新しいトークナイザーを導入しています。Google TPU で JAX フレームワークを使い、1B では 2T トークン、4B では 4T トークン、12B では 12T トークン、27B では 14T トークンでトレーニングしました。
Gemma 3 は、次の 4 つの事後トレーニング コンポーネントを利用しています。
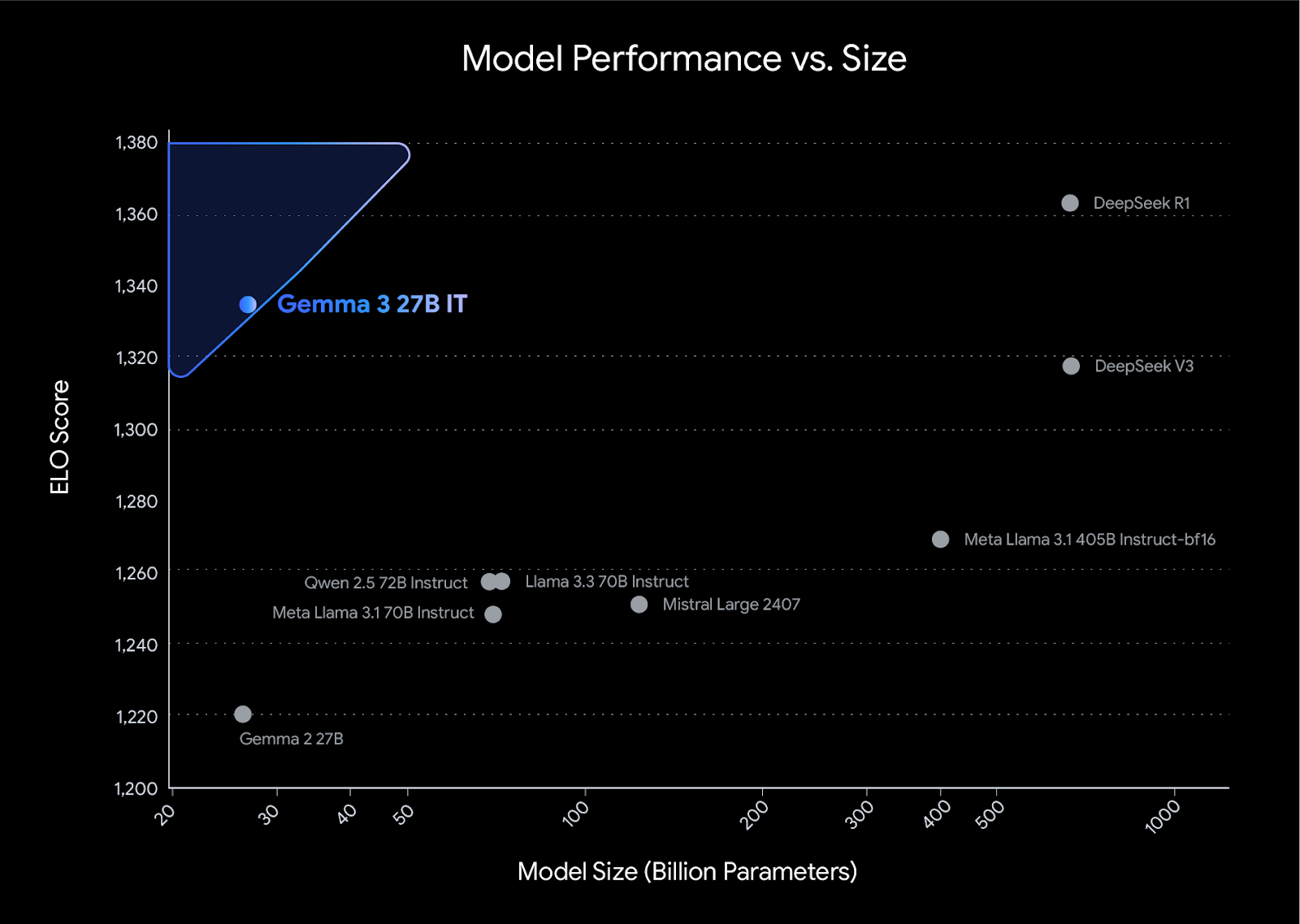
このようなアップデートにより、モデルの数学、コーディング、そして命令に従う機能が大幅に改善された結果、LMArena でスコア 1338 を獲得し、最上位のオープン コンパクト モデルになりました。
Gemma 3 の instruct バージョンでは、Gemma 2 と同じ会話形式が使われるため、テキストのみの入力の場合は、ツールを更新しなくても最新バージョンに更新できます。画像入力の場合は、テキストと画像の両方を指定できます。
<bos><start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
Gemma<end_of_turn>
<start_of_turn>model
Gemma who?<end_of_turn>画像を混ぜた例
<bos><start_of_turn>user
Image A: <start_of_image>
Image B: <start_of_image>
Label A: water lily
Label B:<end_of_turn>
<start_of_turn>model
Desert rote<end_of_turn>Gemma 3 には、SigLIP をベースにした視覚エンコーダが内蔵されています。Gemma 3 の視覚モデルは、トレーニング中は凍結され、複数のサイズ(4B、12B、27B)で同じものが使われています。そのため、Gemma は画像や動画を入力として使用し、画像の分析、画像に関する質問への回答、画像の比較、物体の識別、さらには画像内テキストについての返信を行えるようになっています。このモデルは、もともと 896x896 ピクセルの画像で動作するように作成されたものですが、Gemma 3 では新しいアダプティブ ウィンドウ アルゴリズムを使って入力画像を分割することで、高解像度の非正方形画像で動作できるようになっています。


ShieldGemma 2 は、Gemma 3 をベースに開発された 4B 画像安全分類モデルです。主要な安全カテゴリのラベルを出力することで、合成画像(画像生成モデルによるもの)と自然画像(Gemma 3 などの視覚言語モデルの入力フィルタとして利用可能)の安全性モデレーションを行います。ShieldGemma 2 の詳細については、こちらをご覧ください。
Gemma コミュニティの独創性と Gemmaverse の爆発的な成長には、いつも驚かされています。リファレンス モデルなしで人間の好みに合わせて直接最適化する SimPO 法を開発した Princeton NLP や、ブルガリア語向けの最先端の LLM をトレーニングした INSAIT など、新しいファインチューニング手法を開拓した研究所もあれば、Nexa AI が OmniAudio で行ったように、まったく新しいモダリティで Gemma をトレーニングしたデベロッパーもいます。次にどのようなブレークスルーが実現されるのか、楽しみです。
さっそく Gemma 3 の可能性を探ってみたい方は、次の方法をお試しください。



