

Since its first launch, Gemma models have been downloaded over 100 million times, with the community creating over 60,000 variations for all kinds of use cases. We are excited to introduce Gemma 3, our most capable and advanced version of the Gemma open-model family, building upon the success of previous Gemma releases. We listened to community feedback and added the most requested features, such as longer context, multimodality, and more!
Link to Youtube Video (visible only when JS is disabled)
Gemma 3 introduces multimodality, supporting vision-language input and text outputs. It handles context windows up to 128k tokens, understands over 140 languages, and offers improved math, reasoning, and chat capabilities, including structured outputs and function calling. Gemma 3 is available in four sizes (1B, 4B, 12B, and 27B) as both pre-trained models, which can be fine-tuned for your own use cases and domains, and general-purpose instruction-tuned versions.
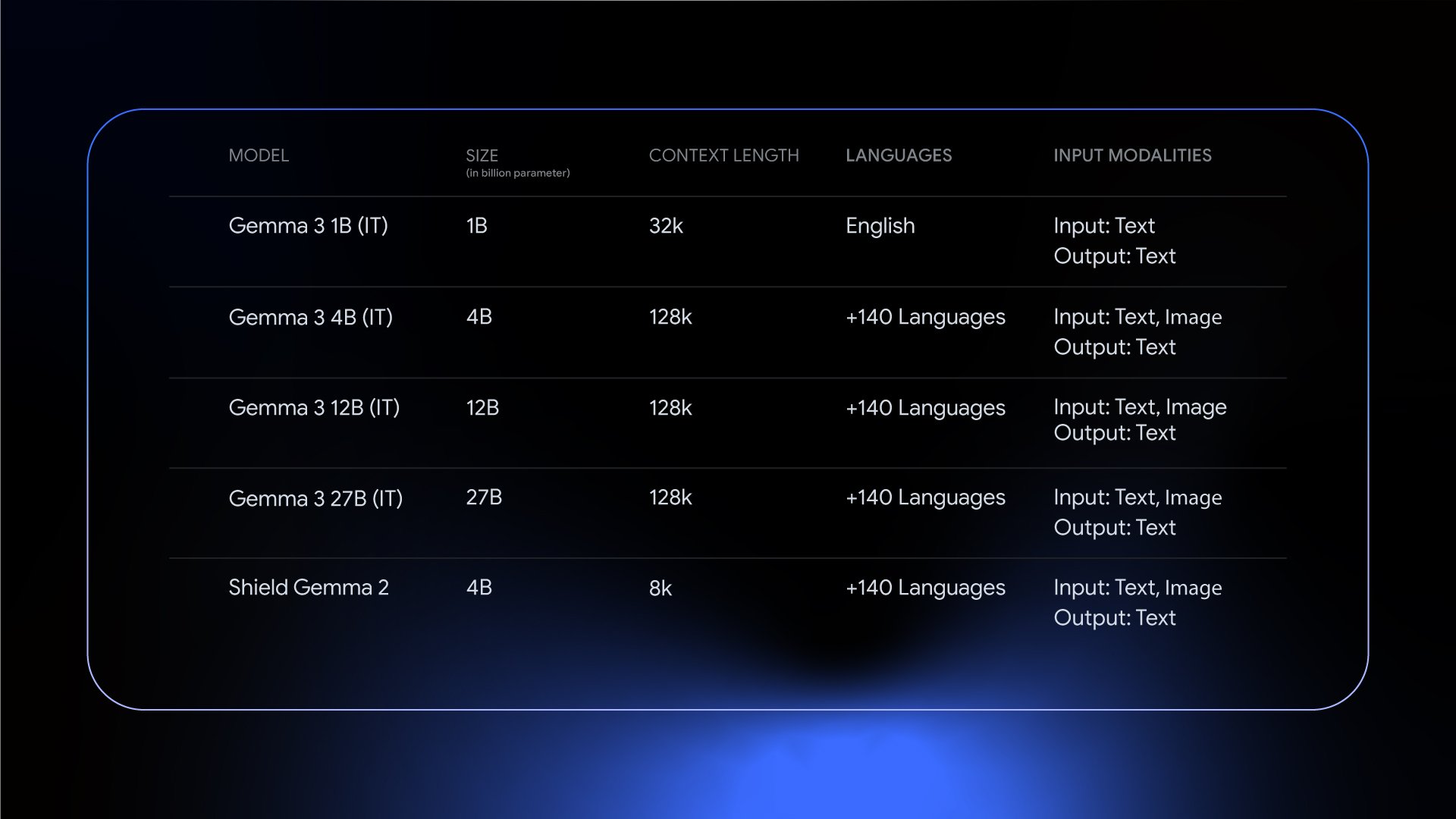
Gemma's pre-training and post-training processes were optimized using a combination of distillation, reinforcement learning, and model merging. This approach results in enhanced performance in math, coding, and instruction following. Gemma 3 uses a new tokenizer for better multilingual support for over 140+ languages and was trained on 2T tokens for 1B, 4T for 4B, 12T for 12B, and 14T tokens for 27B, on Google TPUs using the JAX Framework.
For post-training, Gemma 3 uses 4 components:
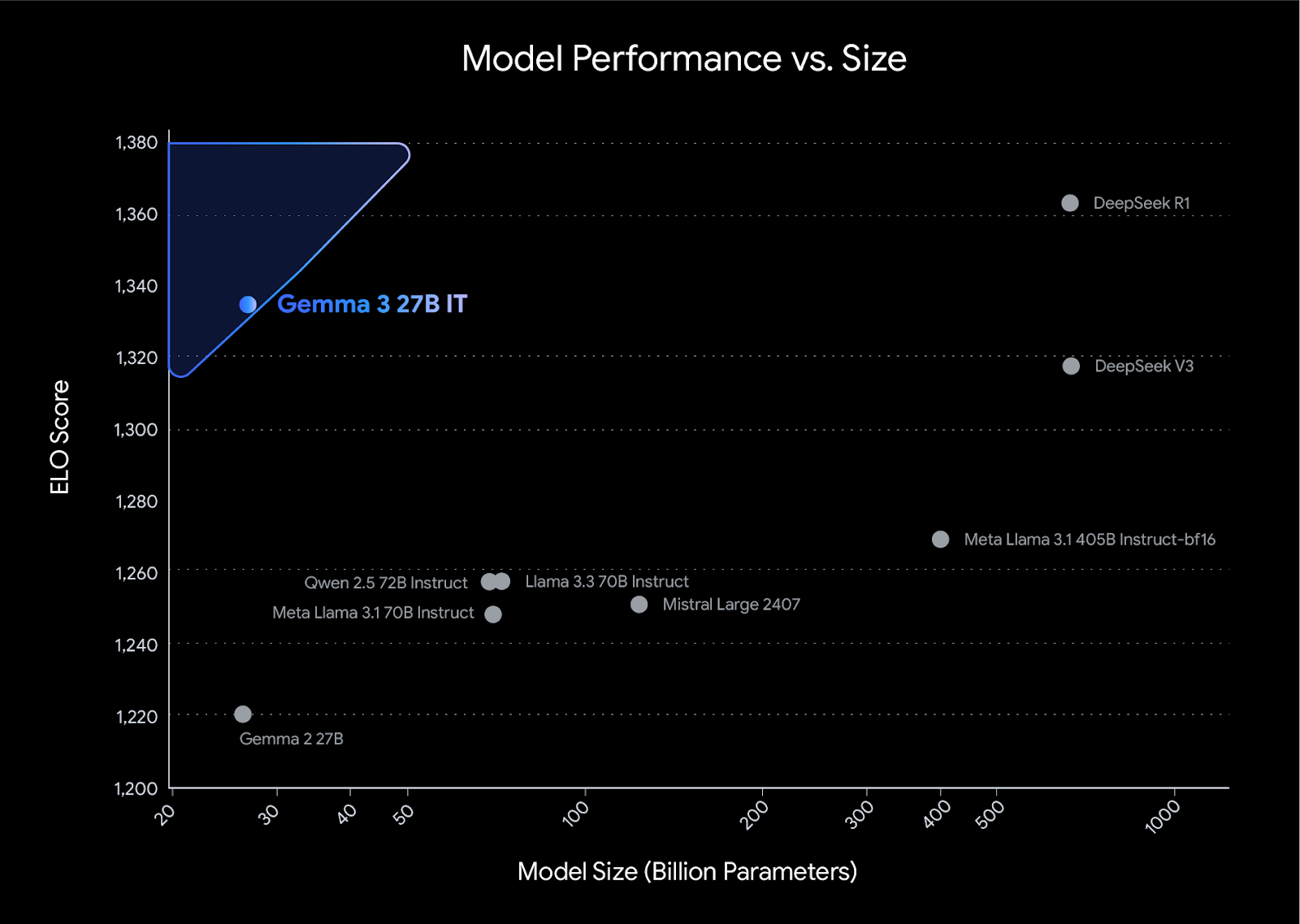
These updates significantly improved the model math, coding, and instruction following capabilities, making it the top open compact model in LMArena, with a score of 1338.
The instruct versions of Gemma 3 use the same dialog format as Gemma 2, so you don’t need to update your tooling to update to the latest version for text-only input. For image input, Gemma 3 allows specifying images interleaved with text.
<bos><start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
Gemma<end_of_turn>
<start_of_turn>model
Gemma who?<end_of_turn>Interleaved image example
<bos><start_of_turn>user
Image A: <start_of_image>
Image B: <start_of_image>
Label A: water lily
Label B:<end_of_turn>
<start_of_turn>model
Desert rote<end_of_turn>Gemma 3 has an integrated vision encoder based on SigLIP. The Gemma 3 vision model, which was kept frozen during training, is the same across its different sizes (4B, 12B and 27B). Thanks to this, Gemma can use images and videos as inputs, allowing it to analyze images, answer questions about an image, compare images, identify objects, and even reply about text within an image. Although the model was originally created to work with images of 896x896 pixels, a new adaptive window algorithm is used to segment input images, allowing Gemma 3 to work with high resolution and non-square images.


ShieldGemma 2 is a 4B image safety classifier built on Gemma 3. It outputs labels across key safety categories, enabling safety moderation of synthetic images (from image generation models) and natural images (which could be the input filter of a Vision-Language Model such as Gemma 3). Learn more about ShieldGemma 2.
We're continually astounded by the ingenuity of the Gemma community and the explosive growth of the Gemmaverse. From research labs pioneering novel fine-tuning techniques – such as the SimPO method developed by Princeton NLP, which directly optimizes for human preferences without a reference model; INSAIT training state-of-the-art LLMs for Bulgarian – to developers training Gemma on entirely new modalities like Nexa AI did with OmniAudio. We can't wait to see what breakthroughs you achieve next.
Ready to explore the potential of Gemma 3 today? Here's how:


