
Gemma は、Gemini モデルと同じ研究技術で構築されたオープンモデルのファミリーです。Gemma モデルは、テキスト生成、コードの補完や生成、特定のタスクのファイン チューニング、さまざまなデバイスでの実行など、幅広いタスクを実行できます。
Ray は、AI と Python アプリケーションを拡張するオープンソース フレームワークであり、機械学習(ML)ワークフローで分散コンピューティングと並列処理を行うインフラストラクチャを提供します。
このチュートリアルを終えると、Ray on Vertex AI で Gemma の教師ありチューニングを行う方法をしっかりと理解し、機械学習モデルを効率的かつ効果的にトレーニングして提供できるようになります。
Ray で Gemma を使う方法は、GitHub の「Get started with Gemma on Ray on Vertex AI」チュートリアル ノートブックで詳しく解説されています。以下のコードは、すべてこのノートブックの一部です。ぜひ参考にしてください。
すべての環境で次の手順が必要です。
2. プロジェクトで課金を有効にする。
3. API を有効化する。
このチュートリアルをローカルで実行する場合は、Cloud SDK をインストールする必要があります。
このチュートリアルでは、以下の Google Cloud 課金対象コンポーネントを使います。
価格について詳しく知りたい方は、料金計算ツールをご利用ください。予想使用量に基づいて費用の見積もりを作成できます。
一文要約システムのデータセット、Extreme Summarization(XSum)データセットを使います。
データセットなどの中間アーティファクトを格納するストレージ バケットを作成する必要があります。
Google Cloud CLI を使うこともできます。
gsutil mb -l {REGION} -p {PROJECT_ID} {BUCKET_URI}
# 例: gsutil mb -l asia-northeast1 -p test-bebechien gs://test-bebechien-ray-bucketカスタム クラスタ イメージを保存できるように、Artifact Registry に Docker リポジトリを作成します。
Google Cloud CLI を使うこともできます。
gcloud artifacts repositories create your-repo --repository-format=docker --location=your-region --description="Tutorial repository"TensorBoard インスタンスを使うと、チューニング ジョブを追跡、監視できます。[Experiments] から作成できます。
Google Cloud CLI を使うこともできます。
gcloud ai tensorboards create --display-name your-tensorboard --project your-project --region your-regionRay on Vertex AI を使う場合、カスタム イメージ用の Dockerfile をゼロから作成するか、ビルド済みの Ray ベースイメージのどちらかを利用します。こちらにベースイメージの 1 つが公開されています。
最初に、Ray アプリケーションの実行に必要な依存関係を含めた requirements ファイルを準備します。
次に、いずれかのビルド済み Ray on Vertex AI ベースイメージを使って、カスタム イメージ用の Dockerfile を作成します。
最後に、Cloud Build を使って Ray クラスタのカスタム イメージをビルドします。
gcloud builds submit --region=your-region
--tag=your-region-docker.pkg.dev/your-project/your-repo/train --machine-type=E2_HIGHCPU_32 ./dockerfile-pathすべてが成功すれば、カスタム イメージが Docker イメージ リポジトリに正常にプッシュされたことを示すメッセージが表示されます。
Artifact Registry にもあります。
Ray on Vertex AI から Ray クラスタを作成できます。
Vertex AI Python SDK を使ってカスタム イメージの Ray クラスタを作成し、クラスタ構成をカスタマイズすることもできます。クラスタ構成の詳細については、ドキュメントをご覧ください。
次の Python コードは、定義済みのカスタム構成で Ray クラスタを作る例です。
注: 構成によっては、クラスタの作成に数分程度かかる場合があります。
# Ray on Vertex AI をセットアップ
import vertex_ray
from google.cloud import aiplatform as vertex_ai
from vertex_ray import NodeImages, Resources
# 指定の tensorboard ID から既存のマネージド tensorboard を取得
tensorboard = vertex_ai.Tensorboard(your-tensorboard-id, project=your-project, location=your-region)
# プロジェクトの Vertex AI SDK for Python を初期化
vertex_ai.init(project=your-project, location=your-region, staging_bucket=your-bucket-uri, experiment_tensorboard=tensorboard)
HEAD_NODE_TYPE = Resources(
machine_type= "n1-standard-16",
node_count=1,
)
WORKER_NODE_TYPES = [
Resources(
machine_type="n1-standard-16",
node_count=1,
accelerator_type="NVIDIA_TESLA_T4",
accelerator_count=2,
)
]
CUSTOM_IMAGES = NodeImages(
head="your-region-docker.pkg.dev/your-project/your-repo/train",
worker="your-region-docker.pkg.dev/your-project/your-repo/train",
)
ray_cluster_name = vertex_ray.create_ray_cluster(
head_node_type=HEAD_NODE_TYPE,
worker_node_types=WORKER_NODE_TYPES,
custom_images=CUSTOM_IMAGES,
cluster_name=”your-cluster-name”,
)これで、get_ray_cluster() を使って Ray クラスタを取得できます。プロジェクトのすべてのクラスタを表示するには、list_ray_clusters() を使います。
ray_clusters = vertex_ray.list_ray_clusters()
ray_cluster_resource_name = ray_clusters[-1].cluster_resource_name
ray_cluster = vertex_ray.get_ray_cluster(ray_cluster_resource_name)
print("Ray cluster on Vertex AI:", ray_cluster_resource_name)Ray on Vertex AI で Gemma をファイン チューニングするには、Ray Train で PyTorch トレーニングを使って、HuggingFace Transformers を分散処理します。
Ray Train では、分散処理で Gemma をチューニングする HuggingFace Transformers コードを含むトレーニング関数を定義します。次に、スケーリング構成を定義し、希望のワーカー数と、分散トレーニング プロセスに GPU が必要かどうかを指定します。さらに、ランタイム構成を定義して、チェックポイントと同期の動作を指定します。最後に、TorchTrainer を開始してファイン チューニングを送信し、fit メソッドで実行します。
このチュートリアルでは、Ray on Vertex AI で HuggingFace Transformer を使い、新聞記事を要約できるように Gemma 2B(gemma-2b-it)をファイン チューニングします。そのため、シンプルな Python スクリプト trainer.py を作成して Ray クラスタに送信します。
トレーニング スクリプトを準備します。次に示すのは、HuggingFace TRL ライブラリを使って Gemma のファイン チューニングを初期化する Python スクリプトの例です。
続いて、分散トレーニング スクリプトを準備します。次に示すのは、Ray の分散トレーニング ジョブを実行する Python スクリプトの例です。
次に、このスクリプトを Ray クラスタに送信します。Ray ダッシュボードのアドレスから Ray Jobs API を使います。ダッシュボードのアドレスは、クラスタの詳細ページの次の場所で確認することもできます。
まず、クライアントを起動して、ジョブを送信します。
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)それでは、モデルのパス、ジョブ ID、予測のエントリ ポイントなど、いくつかのジョブ構成を設定しましょう。
import random, string, datasets, transformers
from etils import epath
from huggingface_hub import login
# いくつかのライブラリ設定を初期化
login(token=”your-hf-token”)
datasets.disable_progress_bar()
transformers.set_seed(8)
train_experiment_name = “your-experiment-name”
train_submission_id = “your-submission-id”
train_entrypoint = f"python3 trainer.py --experiment-name={train_experiment_name} --logging-dir=”your-bucket-uri/logs” --num-workers=2 --use-gpu"
train_runtime_env = {
"working_dir": "your-working-dir",
"env_vars": {"HF_TOKEN": ”your-hf-token”, "TORCH_NCCL_ASYNC_ERROR_HANDLING": "3"},
}ジョブを送信します。
train_job_id = client.submit_job(
submission_id=train_submission_id,
entrypoint=train_entrypoint,
runtime_env=train_runtime_env,
)OSS ダッシュボードで、ジョブのステータスを確認します。
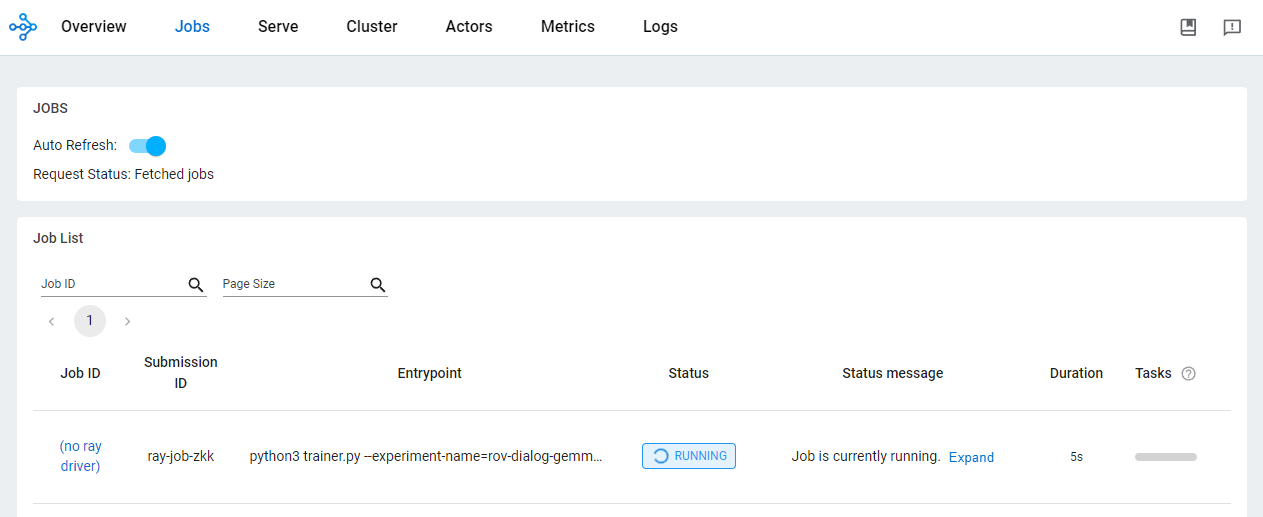
Ray on Vertex AI を使った AI/ML アプリケーションの開発には、さまざまな利点があります。このシナリオでは、Cloud Storage を使って、モデルのチェックポイントや指標などを簡単に保存できます。そのため、Vertex AI TensorBoard でトレーニング プロセスをモニタリングする、Ray Data で一括予測するなど、AI/ML のダウンストリーム タスクですばやくモデルを利用できます。
Ray トレーニング ジョブの実行中および完了後には、Google Cloud CLI を使って Cloud Storage に格納されているモデル アーティファクトを確認できます。
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-nameVertex AI TensorBoard を使うと、結果の指標を記録してトレーニング ジョブを検証できます。
vertex_ai.upload_tb_log(
tensorboard_id=tensorboard.name,
tensorboard_experiment_name=train_experiment_name,
logdir=./experiments,
)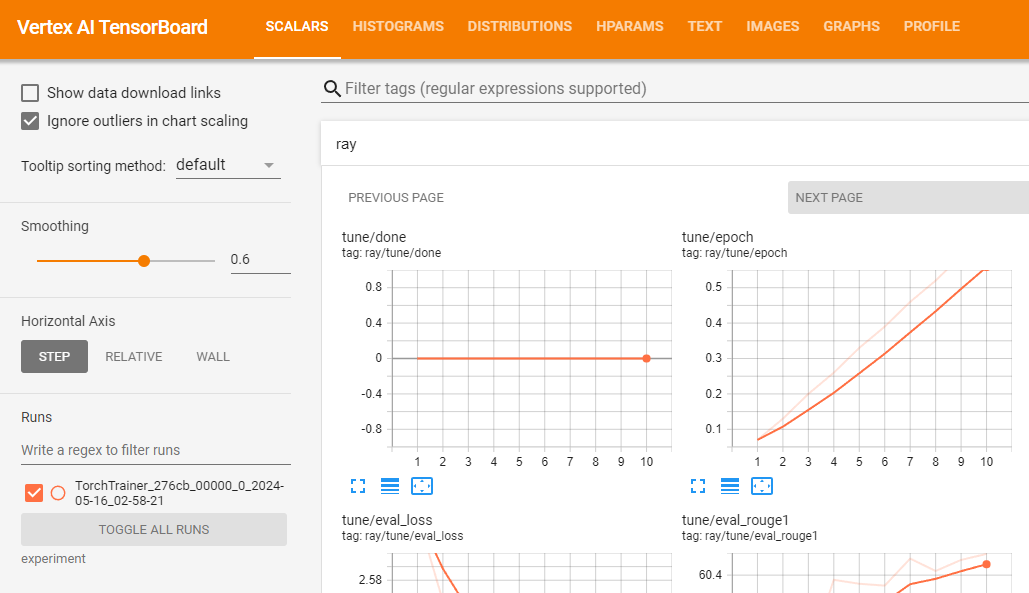
トレーニングが成功したら、ローカルで予測を行ってチューニング済みモデルを検証できます。
まず、Google Cloud CLI を使い、Ray ジョブで生成されたすべてのチェックポイントをダウンロードします。
# すべてのアーティファクトをコピー
gsutil ls -l your-bucket-uri/your-experiments/your-experiment-name ./your-experiment-pathExperimentAnalysis メソッドを使い、関連する指標とモードを考慮して最適なチェックポイントを取得します。
import ray
from ray.tune import ExperimentAnalysis
experiment_analysis = ExperimentAnalysis(“./your-experiment-path”)
log_path = experiment_analysis.get_best_trial(metric="eval_rougeLsum", mode="max")
best_checkpoint = experiment_analysis.get_best_checkpoint(
log_path, metric="eval_rougeLsum", mode="max"
)これで最適なチェックポイントがどれであるかがわかります。次に出力例を示します。

次に、ファイン チューニング済みモデルを読み込みます。この手順は、Hugging Face のドキュメントに記載されています。
次に示すのは、ベースモデルを読み込み、アダプタをマージして、通常のトランスフォーマー モデルのように使えるようにする Python コードの例です。チューニング済みモデルは、tuned_model_path に保存されています。たとえば、“tutorial/models/xsum-tuned-gemma-it” です。
import torch
from etils import epath
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
base_model_path = "google/gemma-2b-it"
peft_model_path = epath.Path(best_checkpoint.path) / "checkpoint"
tuned_model_path = models_path / "xsum-tuned-gemma-it"
tokenizer = AutoTokenizer.from_pretrained(base_model_path)
tokenizer.padding_side = "right"
base_model = AutoModelForCausalLM.from_pretrained(
base_model_path, device_map="auto", torch_dtype=torch.float16
)
peft_model = PeftModel.from_pretrained(
base_model,
peft_model_path,
device_map="auto",
torch_dtype=torch.bfloat16,
is_trainable=False,
)
tuned_model = peft_model.merge_and_unload()
tuned_model.save_pretrained(tuned_model_path)豆知識: ファイン チューニング済みモデルは、次の 1 行のコードで Hugging Face Hub にも公開できます。
tuned_model.push_to_hub("my-awesome-model")チューニング済みモデルで、チュートリアル データセットの検証セットを使って要約を生成してみましょう。
次に示すのは、要約用にデータセットから 1 つの記事をサンプリングする Python コードの例です。その後、関連する要約を生成し、基準となるデータセットの要約と生成した要約を並べて表示します。
import random, datasets
from transformers import pipeline
dataset = datasets.load_dataset(
"xsum", split="validation", cache_dir=”./data”, trust_remote_code=True
)
sample = dataset.select([random.randint(0, len(dataset) - 1)])
document = sample["document"][0]
reference_summary = sample["summary"][0]
messages = [
{
"role": "user",
"content": f"Summarize the following ARTICLE in one sentence.\n###ARTICLE: {document}",
},
]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
tuned_gemma_pipeline = pipeline(
"text-generation", model=tuned_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_tuned_gemma_summary = tuned_gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
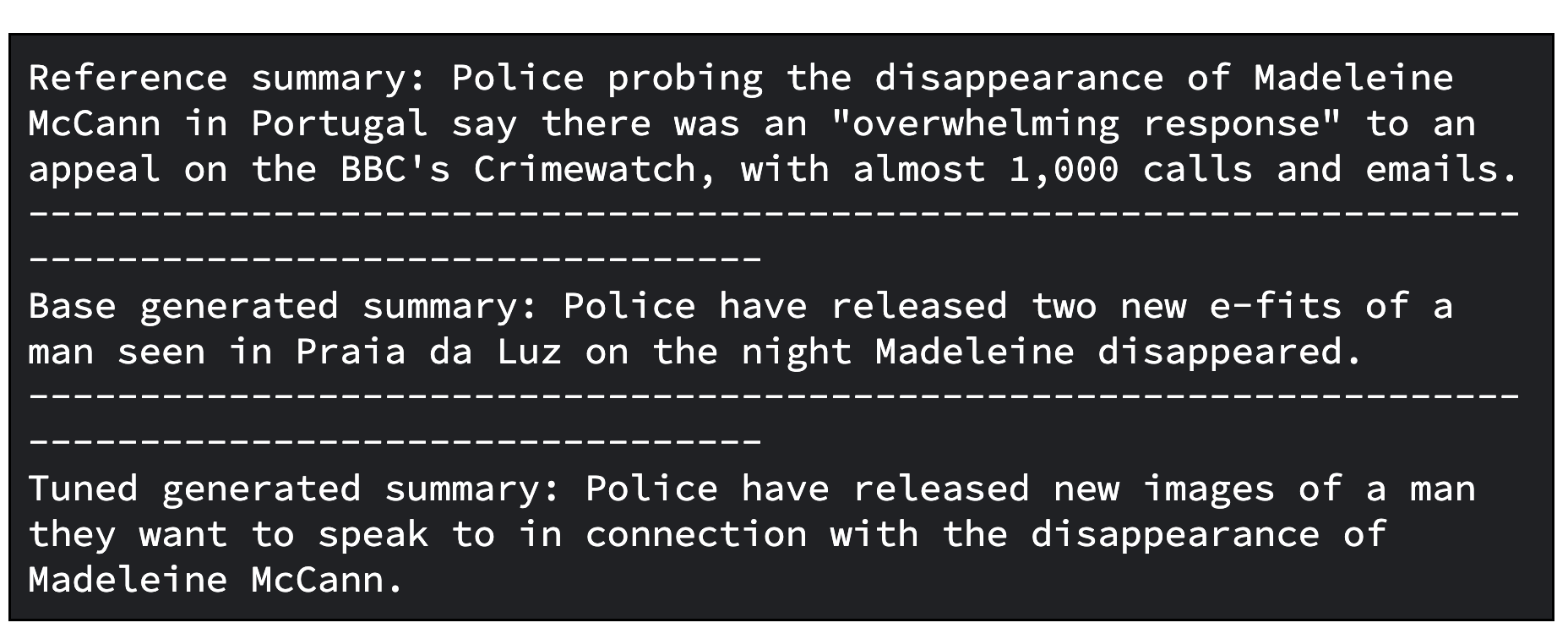
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")次に示すのは、チューニング済みモデルの出力例です。チューニング済みの結果であっても、さらに改善が必要になる場合もあります。最適な品質を得るには、学習率やトレーニング ステップ数などを調整しながら、何度かプロセスを繰り返す必要があります。

追加の手順として、チューニング済みモデルを評価できます。モデルを評価するには、定性的および定量的な比較を行います。
1 つの方法として、ベースの Gemma モデルが生成した応答と、チューニング済みの Gemma モデルが生成した応答を比較することができます。別の方法として、ROUGE 指標とその改善度を計算することもできます。そこから、チューニング済みモデルが基準となる要約をどこまで正確に再現できているかを、ベースモデルと比較して判断できます。
次に示すのは、生成した要約を比較してモデルを評価する Python コードです。
gemma_pipeline = pipeline(
"text-generation", model=base_model, tokenizer=tokenizer, max_new_tokens=50
)
generated_gemma_summary = gemma_pipeline(
prompt, do_sample=True, temperature=0.1, add_special_tokens=True
)[0]["generated_text"][len(prompt) :]
print(f"Reference summary: {reference_summary}")
print("-" * 100)
print(f"Base generated summary: {generated_gemma_summary}")
print("-" * 100)
print(f"Tuned generated summary: {generated_tuned_gemma_summary}")次に示すのは、ベースモデルとチューニング済みモデルの出力例です。
また、次に示すのは、モデルを評価するために ROUGE 指標とその改善度を計算するコードです。
import evaluate
rouge = evaluate.load("rouge")
gemma_results = rouge.compute(
predictions=[generated_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
tuned_gemma_results = rouge.compute(
predictions=[generated_tuned_gemma_summary],
references=[reference_summary],
rouge_types=["rouge1", "rouge2", "rougeL", "rougeLsum"],
use_aggregator=True,
use_stemmer=True,
)
improvements = {}
for rouge_metric, gemma_rouge in gemma_results.items():
tuned_gemma_rouge = tuned_gemma_results[rouge_metric]
if gemma_rouge != 0:
improvement = ((tuned_gemma_rouge - gemma_rouge) / gemma_rouge) * 100
else:
improvement = None
improvements[rouge_metric] = improvement
print("Base Gemma vs Tuned Gemma - ROUGE improvements")
for rouge_metric, improvement in improvements.items():
print(f"{rouge_metric}: {improvement:.3f}%")評価の出力例も示します。

ML ワークロード用のスケーラブルなデータ処理ライブラリ Ray Data を使うと、Ray on Vertex AI でチューニングした Gemma で大規模なオフライン予測を行うことができます。
Ray Data を使って Gemma でオフライン予測を行うには、Python クラスを定義して Hugging Face Pipeline でチューニング済みモデルを読み込む必要があります。次に、データソースとその形式に応じて、Ray Data を使って分散データ読み込みを行い、Python クラスで Ray データセットのメソッドを使って、複数のデータバッチで同時に予測を行います。
Vertex AI の Ray Data でチューニング済みモデルを使ってバッチ予測を行うには、予測に使うデータセットとチューニング済みモデルをクラウドのバケットに保存しておきます。
次に、Ray Data を活用します。Ray Data では、オフラインでバッチ推論を行うための便利な API が提供されています。
まず、Google Cloud CLI を使って、チューニング済みモデルを Cloud Storage にアップロードします。
gsutil -q cp -r “./models” “your-bucket-uri/models”Ray でバッチ予測ジョブを行うためのバッチ予測トレーニング スクリプト ファイルを準備します。
ここでも、Ray Jobs API と Ray ダッシュボードのアドレスを使って、クライアントからジョブを送信します。次に例を示します。
import ray
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient(
address="vertex_ray://{}".format(ray_cluster.dashboard_address)
)それでは、モデルのパス、ジョブ ID、予測のエントリ ポイントなど、いくつかのジョブ構成を設定しましょう。
import random, string
batch_predict_submission_id = "your-batch-prediction-job"
tuned_model_uri_path = "/gcs/your-bucket-uri/models"
batch_predict_entrypoint = f"python3 batch_predictor.py --tuned_model_path={tuned_model_uri_path} --num_gpus=1 --output_dir=”your-bucket-uri/predictions”"
batch_predict_runtime_env = {
"working_dir": "tutorial/src",
"env_vars": {"HF_TOKEN": “your-hf-token”},
}"--num_gpus" 引数で、利用する GPU の数を指定できます。Ray クラスタで利用できる GPU の数以下である必要があります。
その後、ジョブを送信します。
batch_predict_job_id = client.submit_job(
submission_id=batch_predict_submission_id,
entrypoint=batch_predict_entrypoint,
runtime_env=batch_predict_runtime_env,
)Pandas DataFrame を使って、生成した要約を簡単に確認してみましょう。
import io
import pandas as pd
from google.cloud import storage
def read_json_files(bucket_name, prefix=None):
"""Cloud Storage のバケットから JSON ファイルを読み込み、Pandas の DataFrame を返す"""
# ストレージ クライアントのセットアップ
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
blobs = bucket.list_blobs(prefix=prefix)
dfs = []
for blob in blobs:
if blob.name.endswith(".json"):
file_bytes = blob.download_as_bytes()
file_string = file_bytes.decode("utf-8")
with io.StringIO(file_string) as json_file:
df = pd.read_json(json_file, lines=True)
dfs.append(df)
return pd.concat(dfs, ignore_index=True)
predictions_df = read_json_files(prefix="predictions/", bucket_name=”your-bucket-uri”)
predictions_df = predictions_df[
["id", "document", "prompt", "summary", "generated_summary"]
]
predictions_df.head()次に出力例を示します。要約する記事のデフォルト数は 20 です。この数は、“--sample_size” 引数で指定できます。

ここでは、次のようなたくさんのことを学びました。
このチュートリアルが、貴重な知見を提供する有用なものとなることを願っています。
Google デベロッパー コミュニティの Discord サーバーにご参加ください。プロジェクトを共有したり、他のデベロッパーと交流したり、共同ディスカッションに参加したりできます。
また、このプロジェクトで使ったすべての Google Cloud リソースは、忘れずにクリーンアップしておきましょう。これは、チュートリアルで使った Google Cloud プロジェクトを削除するだけで行えます。そうしない場合は、作成した個々のリソースを削除できます。
# tensorboard を削除
tensorboard_list = vertex_ai.Tensorboard.list()
for tensorboard in tensorboard_list:
tensorboard.delete()
# Experiment を削除
experiment_list = vertex_ai.Experiment.list()
for experiment in experiment_list:
experiment.delete()
# Ray on Vertex クラスタを削除
ray_cluster_list = vertex_ray.list_ray_clusters()
for ray_cluster in ray_cluster_list:
vertex_ray.delete_ray_cluster(ray_cluster.cluster_resource_name)# アーティファクト リポジトリを削除
gcloud artifacts repositories delete “your-repo” -q
# 作成した Cloud Storage オブジェクトを削除
gsutil -q -m rm -r “your-bucker-uri”
Java 向け ADK、LangChain4j 統合によってサードパーティ言語モデルに対応

EmbeddingGemma の概要: オンデバイス埋め込み処理向けの最高水準オープンモデル

Building with Gemini 3 in Jules

Grain と ArrayRecord を使用した高性能データ パイプラインの構築

Gemma 3 270M の概要: 超高効率 AI のためのコンパクト モデル

Announcing the Data Commons Gemini CLI extension