先月、最新世代のオープンモデル Gemma 3 をリリースしました。最先端のパフォーマンスを提供する Gemma 3 は、ネイティブで BFloat16(BF16)精度になっており、NVIDIA H100 のような 1 つのハイエンド GPU で動作する主要モデルとしての地位をいち早く確立しました。
Gemma 3 をさらに身近なものにするため、量子化対応トレーニング(QAT)で最適化した新しいバージョンを発表します。これにより、高い品質を維持しながらメモリ要件を大幅に削減できるので、NVIDIA RTX 3090 などのコンシューマグレードの GPU で、Gemma 3 27B などの強力なモデルをローカル実行できるようになります。
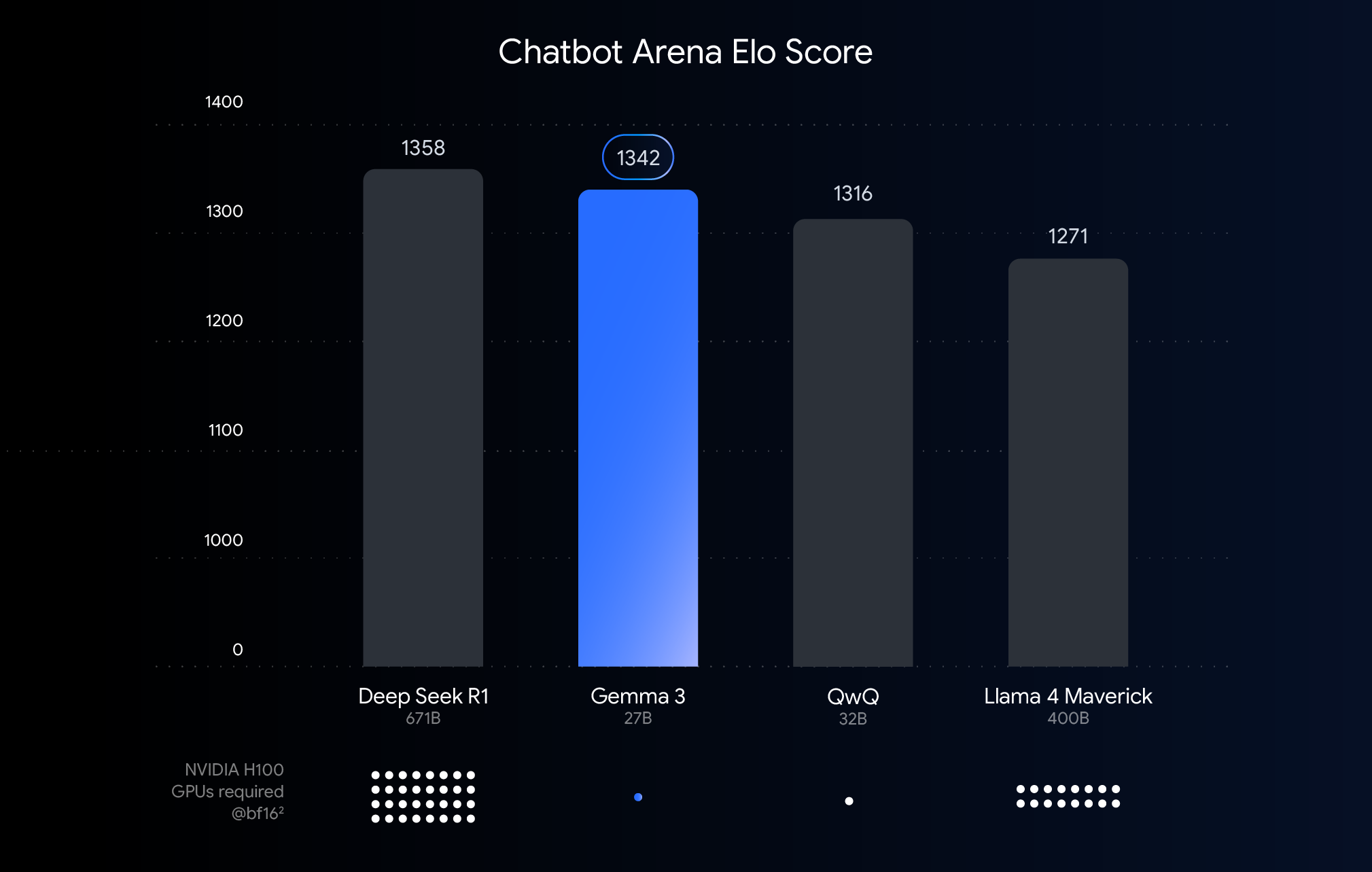
上のグラフは、最近リリースされた大規模言語モデルのパフォーマンス(Elo スコア)を示しています。2 つのモデルの応答を匿名で並べ、それを見た人間の評価を比較するという手法で、結果が良かったものほどバーが高くなります。それぞれのバーの下で示しているのは、BF16 データ型でそのモデルを実行するために必要と推定される NVIDIA H100 GPU の数です。
なぜ BFloat16 で比較したのか?BF16 は多くの大規模モデルの推論に使われる一般的な数値形式で、モデルのパラメータが 16 ビット精度で表されることを意味します。すべてのモデルで BF16 を使えば、一般的な推論設定で、モデルを同じ条件で比較できます。つまり、ハードウェアの違いや、量子化などの最適化技術(以降で詳しく説明します)といった変動要素を排除し、モデル自体に固有な機能を比較できます。
このグラフでは、BF16 を使って公正な比較を行っています。しかし重要な点は、非常に大きなモデルをデプロイする場合、実用上の理由から、FP8 のような低精度形式を使って巨大なハードウェア要件(GPU の数など)に対応することがあります。つまり、実用性を得るために、パフォーマンスとのトレードオフを受け入れざるをえない場合があります。
ハイエンドのハードウェアで最高のパフォーマンスを発揮できることは、クラウドへのデプロイや研究には最適です。しかし、すでに所有しているハードウェアで Gemma 3 を活用したいという明確で強い声も上がっています。私たちが取り組んでいるのは、強力な AI を身近なものにすることです。つまり、デスクトップやノートパソコン、さらにはスマートフォンに搭載されているコンシューマグレードの GPU で、効率的にモデルを動作させたいと考えています。
ここで役立つのが量子化です。AI モデルを量子化すると、保存や応答の計算に使う数値(モデルのパラメータ)の精度が下がります。量子化は、画像で使う色の数を減らして圧縮するようなものです。1 つの数字につき 16 ビット(BFloat16)を使うのではなく、8 ビット(int8)や 4 ビット(int4)のような少ないビットを使います。
int4 を使うということは、それぞれの数を表現するために 4 ビットしか使えないことになり、BF16 と比べると、データのサイズが 4 分の 1 になります。量子化を行うとパフォーマンスが低下することが多いため、量子化しても劣化しにくい Gemma 3 モデルをリリースできたのはすばらしいことです。Gemma 3 のそれぞれのモデルについて、いくつかの量子化バージョンをリリースしています。お気に入りのエンジンで推論できるように、Ollama、llama.cpp、MLX 向けの Q4_0(一般的な量子化フォーマット)などを準備しました。
どのようにして品質を維持しているのか?QAT を使います。QAT は、トレーニングを終えてからモデルを量子化するのではなく、トレーニングに量子化プロセスを組み込みます。QAT は、トレーニング時に低精度演算をシミュレートすることで、劣化が少ない量子化を実現します。その結果、精度を維持しつつ、小さく高速なモデルを作ることができます。もう少し詳しく説明すると、量子化されていないチェックポイントから得られた確率をターゲットとして、最大 5,000 ステップの QAT を行いました。これにより、Q4_0 に量子化したときの困惑度の低下を 54% 抑えることができました(llama.cpp の困惑度評価を利用)。
int4 量子化の影響は劇的です。モデルの重みを読み込むことだけに必要になる VRAM(GPU メモリ)の量をご覧ください。
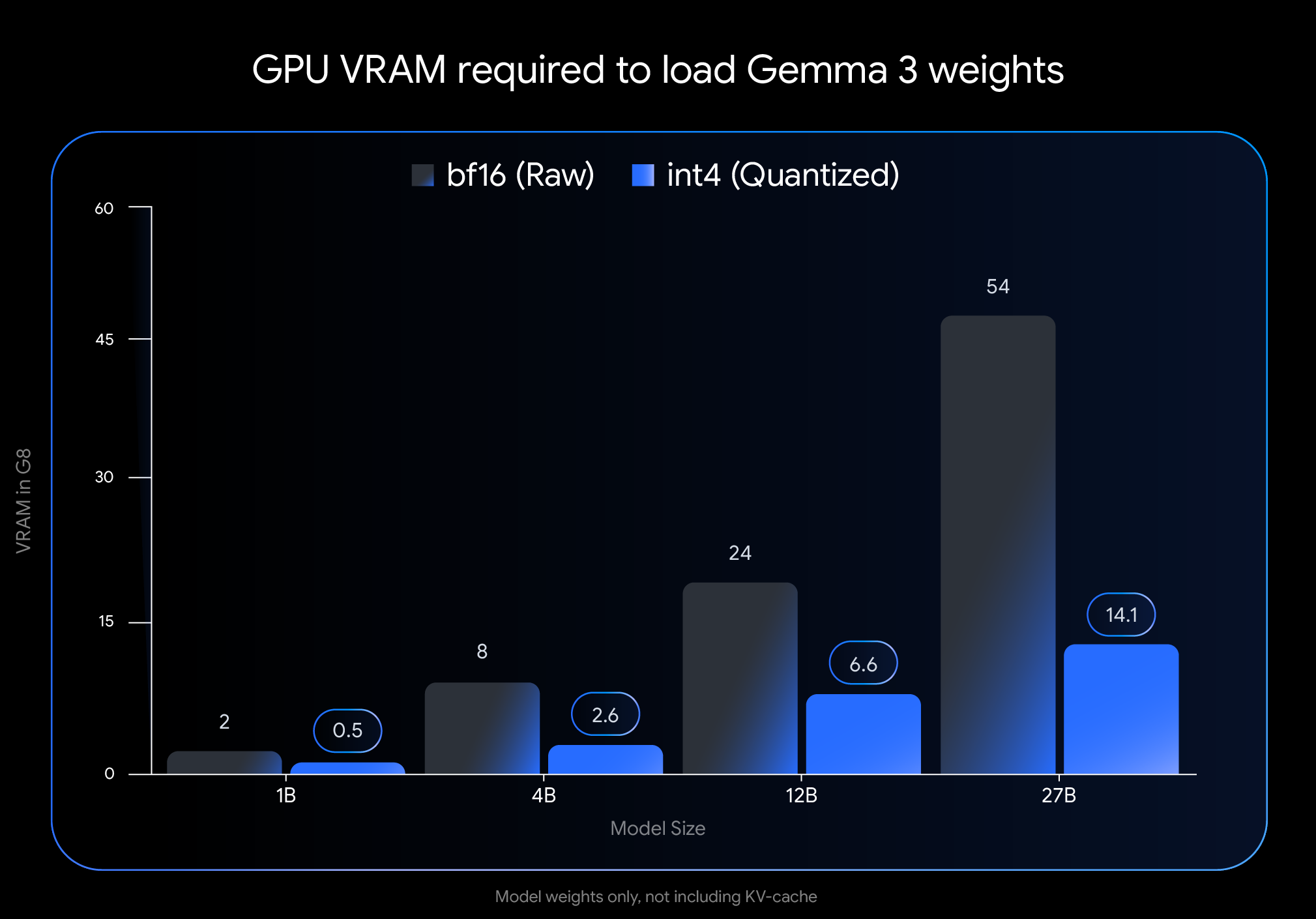
注: この図は、モデルの重みを読み込むために必要な VRAM だけを示しています。モデルを実行するには、KV キャッシュ用の追加の VRAM も必要です。これは進行中の会話に関する情報を格納するために使われ、コンテキストの長さに依存します。
この劇的な削減により、広く利用できるコンシューマ向けハードウェアでも、大きく強力なモデルを実行できるようになります。
こういったモデルを皆さんのお気に入りのワークフローで簡単に利用できるようにしたいと考えています。公式の int4 および Q4_0 の非量子化 QAT モデルは、Hugging Face と Kaggle から利用できます。また、人気のデベロッパー ツールと連携し、QAT ベースの量子化チェックポイントをシームレスに試せるようにしています。
公式版の量子化対応トレーニング(QAT)モデルは高品質のベースラインを提供するものですが、活気に満ちた Gemmaverse では、多くの選択肢が提供されています。そのほとんどは、トレーニング後量子化(PTQ)によるものです。Bartowski、Unsloth、GGML などのメンバーからの重要な貢献は、Hugging Face ですぐに入手できます。こういったコミュニティ オプションを検討すれば、サイズ、スピード、品質のトレードオフの幅が広がり、特定のニーズを満たすことができます。
最先端の AI のパフォーマンスを身近なハードウェアで利用できるようにすることは、AI 開発を誰でも行えるようにするための重要なステップです。QAT で最適化した Gemma 3 モデルにより、皆さんのデスクトップやノートパソコンで最先端の機能を活用できるようになります。
以下の方法で、量子化モデルを試して開発を始めることができます。
皆さんが Gemma 3 を使ってローカルで動かすものを楽しみにしています!