

[Google が Gemini 2.0 Flash ネイティブ画像生成で作成した画像]
本日、Gemini API で新しい試験運用版 Gemini Embedding テキストモデル(gemini-embedding-exp-03-07)1 を公開します。
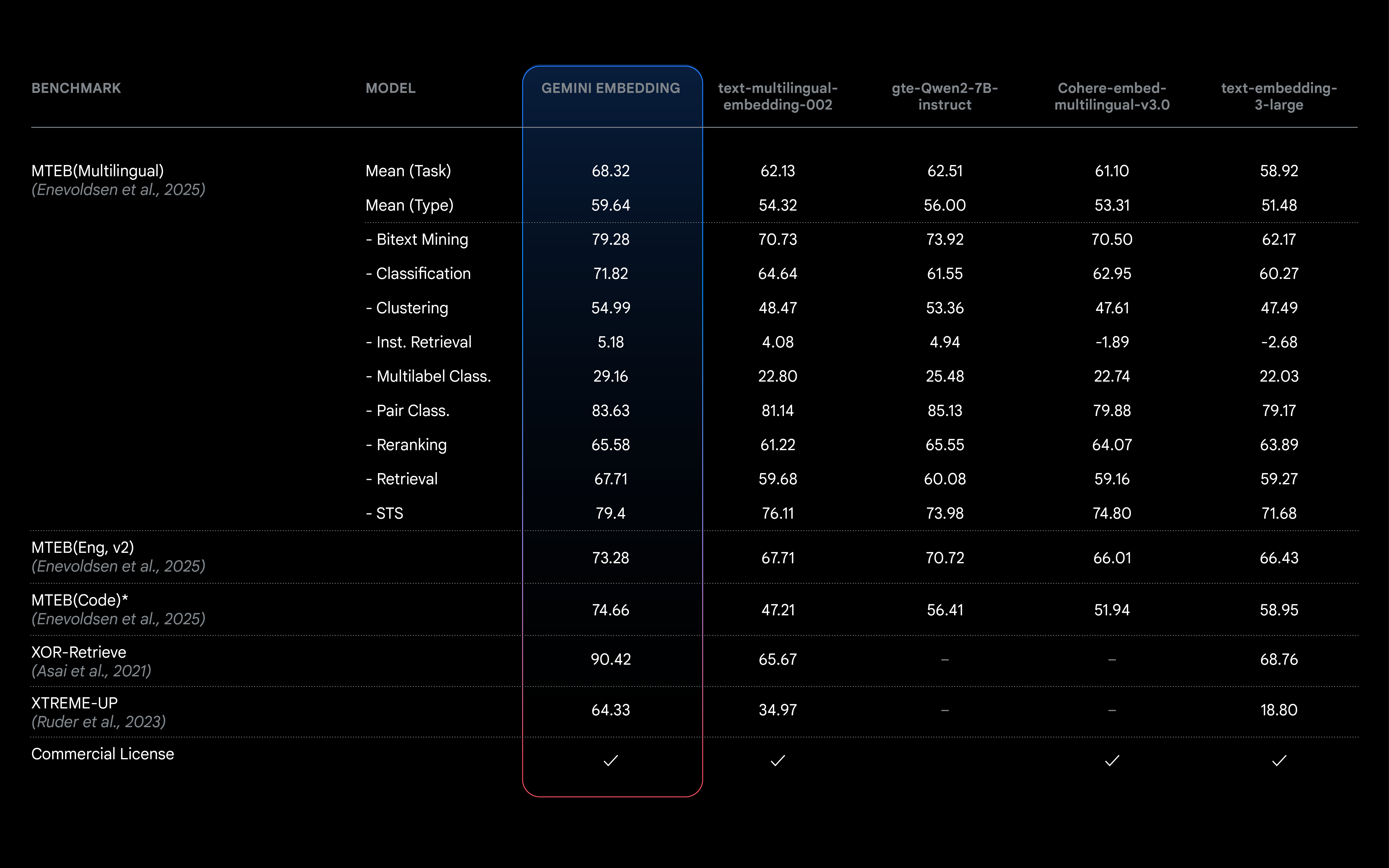
この新しいエンベディング モデルは、Gemini モデルそのものを使ってトレーニングしており、言語や細かな文脈まで理解できる Gemini の能力を受け継いでいるので、幅広い用途で利用できます。以前の最先端モデル(text-embedding-004)を上回る能力を持ち、Massive Text Embedding Benchmark (MTEB)多言語リーダーボードでトップランクを獲得しているほか、より長い入力トークン長などの新機能も搭載されています!
このモデルは、極めて高い汎用性を持つようにトレーニングしてあるので、財務、科学、法務、検索など、さまざまなドメインで優れたパフォーマンスを発揮します。また、すぐに効率的に動作するので、特定のタスク向けに幅広いファインチューニングを行う必要はありません。
MTEB(多言語)リーダーボードは、検索や分類などの多様なタスクに対してテキスト エンベディング モデルをランク付けすることで、包括的なベンチマークを提供し、モデルを比較できるようにするものです。私たちの Gemini Embedding モデルは、68.32 の平均(タスク)スコアを達成しました。これは、次点のモデルを 5.81 上回る数値です。
インテリジェント検索拡張生成(RAG)やレコメンデーション システムの開発、テキスト分類など、LLM がテキストの背後にある意味を理解する能力は極めて重要です。通常、エンベディングは、開発するシステムの効果を高め、コストやレイテンシを削減するうえで欠かせないものであると同時に、一般的にキーワード マッチング システムよりも優れた結果を実現します。エンベディングは、データを数値で表現することで、そのデータの意味と文脈をキャプチャします。似た意味を持つデータからは、近いエンベディングが生成されます。エンベディングは、次のような幅広い用途に利用できます。
エンベディングや一般的な AI でのユースケースの詳細については、Gemini API ドキュメントをご覧ください。
デベロッパーは、Gemini API から新しい試験運用版 Gemini Embeddings モデルにアクセスできます。既存の embed_content エンドポイントと互換性があります。
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="How does alphafold work?",
)
print(result.embeddings)あらゆる次元で品質が向上していることに加えて、Gemini Embedding には次のような特長があります。
現在は、処理能力に制限がある試験運用版段階にありますが、今回のリリースで Gemini Embedding の機能をいち早く試せるようになります。すべての試験運用版モデルと同じく、今後変更される可能性があります。現在は、今後数か月以内に安定版を一般公開リリースすることに向けて作業を進めています。エンベディング フィードバック フォームからご意見をお聞かせください。
1 Vertex AI では、エンドポイント「text-embedding-large-exp-03-07」から同じモデルを利用できます。一般提供版では、一貫性のある名前になる予定です。



