

[Google에서 Gemini 2.0 Flash 네이티브 이미지 생성을 사용해 만든 이미지]
우리는 현재 Gemini API에서 사용할 수 있는 새로운 실험용 Gemini Embedding 텍스트 모델(gemini-embedding-exp-03-07)1 을 만들고 있습니다.
Gemini 모델 자체에서 학습된 이 임베딩 모델은 언어와 미묘한 맥락에 대한 Gemini의 이해력을 계승하여 광범위한 용도에 적용할 수 있습니다. 이 새로운 임베딩 모델은 이전의 최첨단 모델(text-embedding-004)을 능가하고 MTEB(Massive Text Embedding Benchmark) 다국어 리더보드에서 상위권에 올라 있으며 더 긴 입력 토큰 길이 같은 새로운 기능을 제공합니다!
저희는 금융, 과학, 법률, 검색 등 다양한 영역에서 탁월한 성과를 내는 놀라운 범용성을 갖도록 모델을 학습시켰습니다. 이 모델은 즉시 효과적으로 작동하므로 특정 작업을 위해 광범위하게 미세 조정할 필요가 없습니다.
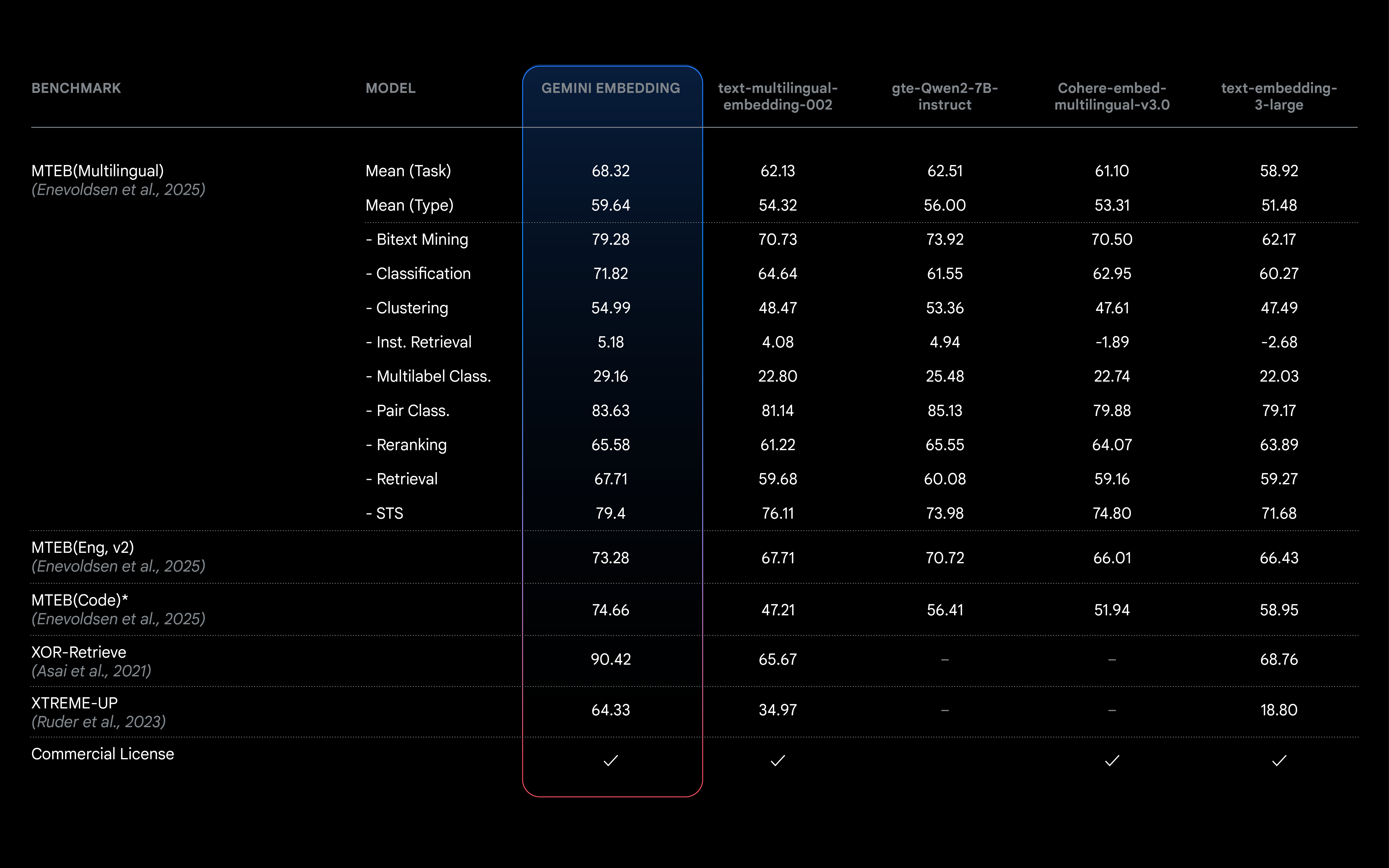
MTEB(다국어) 리더보드는 검색 및 분류 같은 다양한 작업에서 텍스트 임베딩 모델의 순위를 매겨 모델 비교를 위한 포괄적인 업계 기준치를 제공합니다. Gemini Embedding 모델은 평균 (작업) 점수가 68.32점으로 바로 다음 순위 경쟁 모델을 +5.81점 차이로 여유 있게 앞서고 있습니다.
지능형 RAG(검색 증강 생성) 및 추천 시스템 개발부터 텍스트 분류까지, LLM이 텍스트 이면의 의미를 이해하는 능력은 매우 중요합니다. 임베딩은 보다 효율적인 시스템을 구축하고 비용과 지연 시간을 줄이는 데 있어 핵심적인 역할을 하는 경우가 많고, 대체로 키워드 매칭 시스템보다 더 나은 결과를 제공합니다. 임베딩은 데이터를 수치적으로 표현해 시맨틱에 따른 의미와 맥락을 포착합니다. 유사한 시맨틱 의미를 가진 데이터는 서로 더 가까운 임베딩을 갖고 있습니다. 임베딩은 다음을 포함한 광범위한 응용 사례에 사용할 수 있습니다.
Gemini API 문서에서 임베딩 및 일반적인 AI 사용 사례에 대해 자세히 알아볼 수 있습니다.
이제 개발자는 Gemini API를 통해 새로운 실험용 Gemini Embeddings 모델에 액세스할 수 있습니다. 이 모델은 기존 embed_content 엔드포인트와 호환됩니다.
from google import genai
client = genai.Client(api_key="GEMINI_API_KEY")
result = client.models.embed_content(
model="gemini-embedding-exp-03-07",
contents="How does alphafold work?",
)
print(result.embeddings)Gemini Embedding은 모든 차원에서 품질이 향상되었을 뿐만 아니라 다음과 같은 특징도 가지고 있습니다.
현재 용량이 제한된 실험 단계에 있지만, 이 릴리스는 Gemini Embedding 기능을 조기에 탐색할 기회를 제공합니다. 모든 실험용 모델과 마찬가지로 이 모델 역시 변경될 수 있으며, 앞으로 몇 달 내에 안정적인 정식 버전으로 출시할 수 있도록 노력하고 있습니다. 임베딩 피드백 양식에 대한 여러분의 의견을 기다립니다.
1 Vertex AI에서는 엔드포인트 "text-embedding-large-exp-03-07"를 통해 동일한 모델이 제공됩니다. 정식 버전에서도 일관된 명명법이 유지될 것입니다.



