

This past December, we launched PaliGemma 2, an upgraded vision-language model in the Gemma family. The release included pretrained checkpoints of different sizes (3B, 10B, and 28B parameters) that can be easily fine-tuned on a wide range of vision-language tasks and domains, such as image segmentation, short video captioning, scientific question answering and text-related tasks with high performance.
Now, we’re thrilled to announce the launch of PaliGemma 2 mix checkpoints. PaliGemma 2 mix are models tuned to a mixture of tasks that allow directly exploring the model capabilities and using it out-of-the-box for common use cases.
If you were already using the original PaliGemma mix checkpoints, you can directly upgrade to PaliGemma 2 without needing to do any changes. The model performs different tasks depending on how it’s prompted. You can review the different prompt task syntax in the official documentation and learn more about how PaliGemma 2 was developed in our technical report.

Result:
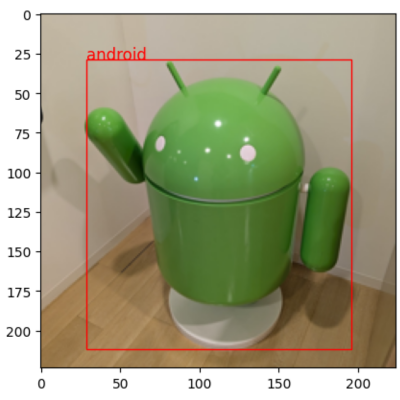

Result:


Result:


Result:
![Japanese Kanji reads: Downlight, Dining Room, Kitchen, Living Room, Bathroom/Dressing Room]](https://storage.googleapis.com/gweb-developer-goog-blog-assets/images/PaliGemma_inline_images.original.png)

Result:


Result: beach
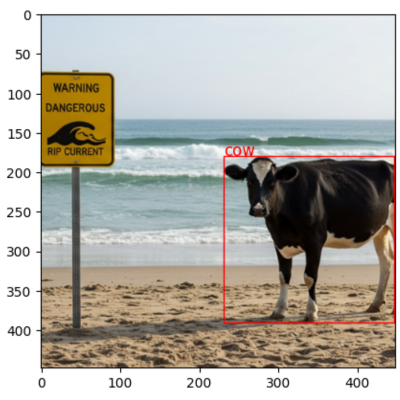
Result: a cow standing on a beach next to a sign that says warning dangerous rip current.
Optical Character Recognition (OCR)
Result:
WARNING
DANGEROUS
RIP CURRENT
Result:
Result:
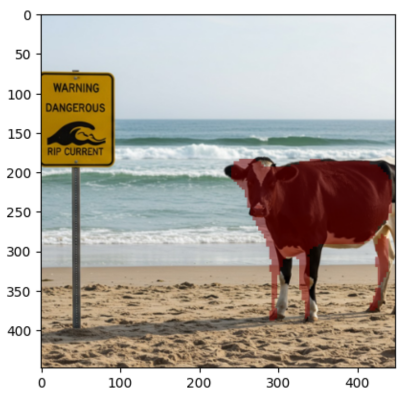
Result: A cow standing on a beach next to a warning sign.
Result:
WARNING DANGEROUS
RIP CURRENT
Ready to discover the potential of PaliGemma 2? Here is how you can explore the mix model capabilities:
While PaliGemma 2 mix has strong performance across multiple tasks, you will get the best results by fine-tuning PaliGemma 2 in your own task or domain. To learn how to do it, dive into our comprehensive documentation, check our official example notebooks for Keras and JAX, or use the Hugging Face transformers example. We’re looking forward to seeing what you build with it!

Enable on-demand expertise with Agent Skills in Genkit Go

Introducing EmbeddingGemma: The Best-in-Class Open Model for On-Device Embeddings

Introducing Gemma 3 270M: The compact model for hyper-efficient AI

Run Ray on TPU, Part 2: Ray AI libraries

Agent and Model Evaluations in Gemini Enterprise Agent Platform are now GA