
The newly introduced continuous checkpointing feature in Orbax and MaxText is engineered to help your training job strike the optimal balance between reliability and performance.

The periodicity of checkpoint generation during model training is conventionally fixed - be it every X training step or every Y minutes. Selecting an appropriate checkpoint frequency is far from trivial, as an incorrect setting often leads to one of two critical scenarios:
Continuous checkpointing, conversely, maximizes the exploitation of the host machine and I/O bandwidth and minimizes the risk associated with hardware failures. This capability is achieved with minimal performance degradation, as Orbax intelligently initiates an asynchronous checkpoint save only upon the successful completion of the preceding save operation.
Take MaxText as an example, it takes only one step to enable continuous checkpointing. You will simply need to configure the following flags for the training task:
# Enable asynchronous checkpointing
enable_checkpointing: True
async_checkpointing: True
...
# Enable continuous checkpointing
enable_continuous_checkpointing: True
# Keep the lastest 10 checkpoint to avoid excessive amount of storage consumption
max_num_checkpoints_to_keep: 10
...MaxText will attempt to save the checkpoint once the previous saving request is fulfilled in the background. Take the llama-3.1-70B model continuous pre-training (CPT) task as an example - on two slices of v5p-128 cluster, we pick two different configurations: (a) continuous checkpointing enabled. (b) checkpointing every 100 steps.

As demonstrated by the benchmark findings, the P50 checkpoint intervals are markedly smaller when continuous checkpointing is activated. This is accompanied by an anticipated increase in the average training step time, primarily attributed to the more frequent device-to-host data transfer operations.
To accurately quantify the tangible benefits associated with more frequent checkpointing, we can reasonably assume a mean-time-between-failure (MTBF), where failure encompasses any event that terminates the job, such as hardware malfunctions or preemption events.
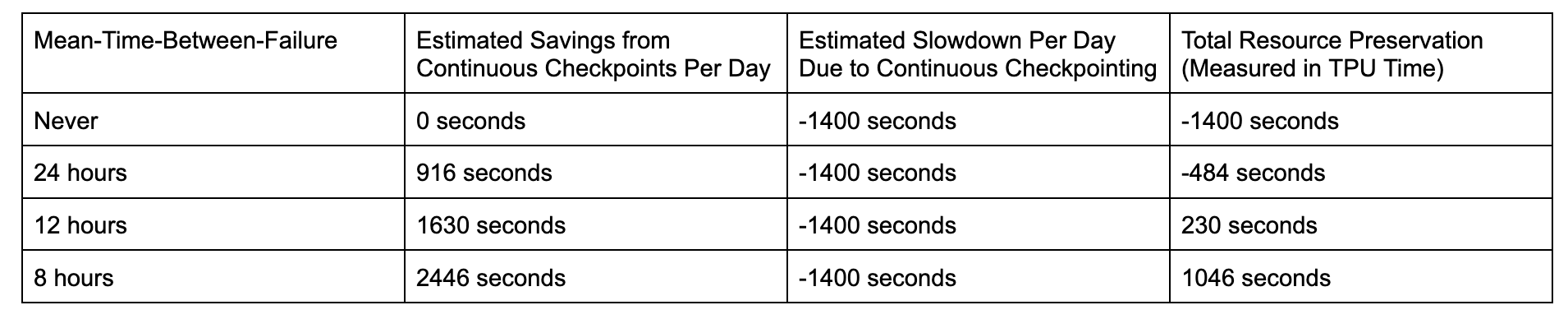
The benchmark was conducted on a relatively modest cluster configuration, specifically featuring 64 chips per slice; yet, it demonstrates substantial resource conservation. Moreover, the efficiency gains realized through continuous checkpointing are amplified during large-scale training initiatives for the following compelling reasons:
Orbax also offers more flexible options in terms of saving and preserving checkpoints beyond what MaxText offers today. These options can be defined as highly customizable policies for more complicated use cases:
continuous_checkpointing_policy_with_minimum_interval = save_decision_policy.ContinuousCheckpointingPolicy(minimum_interval_secs = 30)Each training step might be very small when working with lightweight models, checkpointing too frequently might create some unwanted I/O overhead. A minimum_interval_secs could be set to allow a cool down period between checkpoints.
every_n_seconds_preservation_policy =
preservation_policy.EveryNSeconds(180)In the above example, Orbax will attempt to save at least one checkpoint every 180 seconds, unless there is nothing within this period. This could be used to prune checkpoints, while maintaining the ability to evaluate or restore to a previous checkpoint.
@dataclasses.dataclass
class CustomizedPreservationPolicy(PreservationPolicy):
"""Implement your own policy for reserving checkpoints. """
def should_preserve(
self,
checkpoints: Sequence[PolicyCheckpointInfo],
*,
context: PreservationContext,
) -> Sequence[bool]:
result = [is_checkpoint_preservable(checkpoint) for checkpoint in checkpoints]
_log_preservation_decision(
"Customized Preservation Policy",
checkpoints,
result
)
return resultReduction of the checkpoint interval could not achieve the expected result, for the following reasons:
A prevalent concern arises when conducting training jobs across multiple slices: the potential bottleneck imposed by the Data Center Network (DCN) bandwidth. When utilizing a multi-slice configuration, DCN bandwidth is leveraged for both model weight updates and checkpointing operations. However, within the Orbax framework, the substantial component of checkpointing remains asynchronous and is confined to communication between the storage server and a single slice (typically slice 0). Crucially, this design ensures that the inter-slice communication remains unblocked and unaffected by the checkpointing process. In our benchmark over multiple slices, we don’t see significant slow down due to the enablement of continuous checkpointing.
It is strongly recommended that you ensure the storage bucket is co-located with your training cluster. The efficacy of continuous checkpointing is heavily reliant on network bandwidth. Utilizing a cross-metro network can significantly degrade checkpointing speed, which, in turn, introduces substantial reliability risks to the overall process.



